Cache Invalidation Strategies Beyond TTL
Advanced cache invalidation patterns including event-driven invalidation with CDC, tag-based eviction, and thundering herd mitigation techniques.

Akhil Sharma
January 22, 2026
Cache Invalidation Strategies Beyond TTL
Phil Karlton famously said there are only two hard things in computer science: cache invalidation and naming things. TTL-based expiration is the default answer to cache invalidation, but it forces you to choose between stale data (long TTL) and cache churn (short TTL). For systems where data freshness matters, you need better strategies.
The Cache Pattern Landscape
Before discussing invalidation, let's establish the caching patterns and how invalidation applies to each:
Cache-Aside (Lazy Loading): Application checks cache, misses go to the database, results are written back to cache. Invalidation is the application's responsibility.
Write-Through: Every write goes to both the cache and the database. Cache is always fresh, but write latency increases.

Write-Behind (Write-Back): Writes go to the cache first, then asynchronously to the database. Lowest write latency, but risks data loss if the cache node crashes before the write-behind completes.
Most production systems use cache-aside because it's the simplest and gives the application full control over what gets cached and when it gets invalidated. The rest of this post assumes cache-aside unless noted.
Strategy 1: Event-Driven Invalidation with CDC
Change Data Capture (CDC) watches the database's write-ahead log (WAL/binlog) and emits events for every row change. These events trigger cache invalidation — no TTL needed, no stale windows.
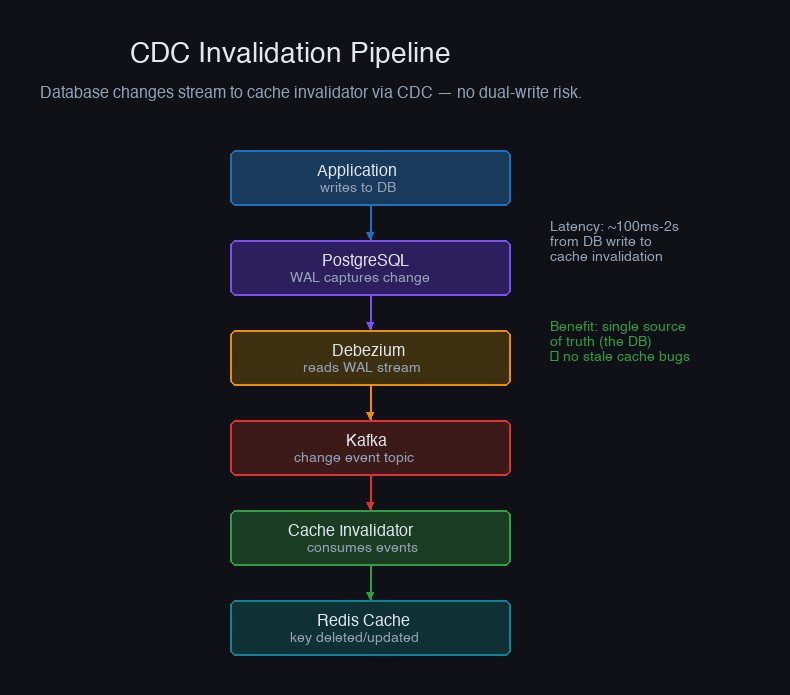
Using Debezium to capture PostgreSQL changes:
The invalidation consumer:
Advantages: Near-real-time invalidation (typically 100-500ms delay), no coupling between write path and cache invalidation, works even for direct database modifications (migrations, admin scripts).
Disadvantages: Operational complexity (running Debezium, managing Kafka), eventual consistency window (the CDC pipeline has latency), and schema changes require updating the invalidation logic.
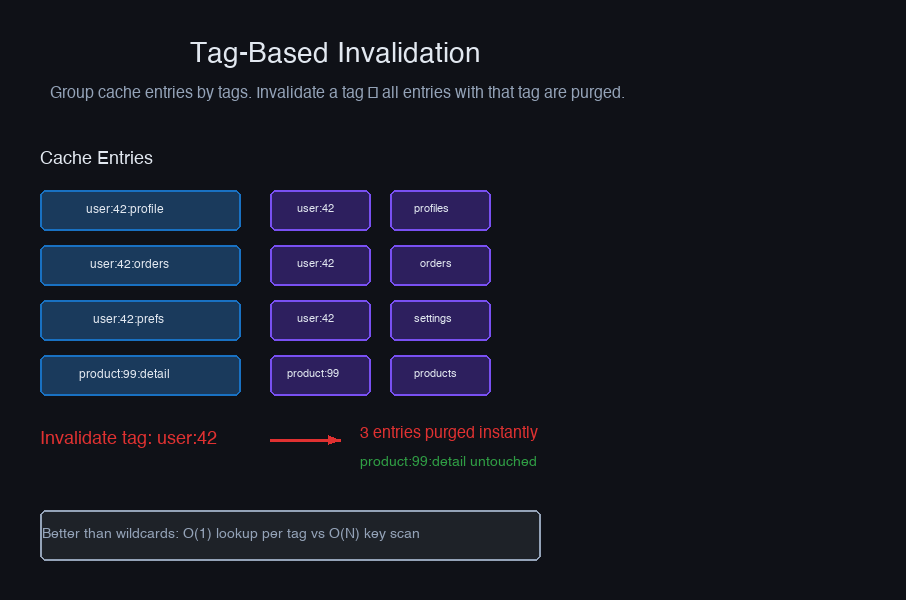
Strategy 2: Tag-Based Invalidation
Assign tags to cache entries. When the underlying data changes, invalidate all entries with a matching tag. This handles the "cascade" problem where one data change affects multiple cached views.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
async def invalidate_tag(self, tag: str): keys = await self.redis.smembers(f"tag:{tag}") if keys: pipe = self.redis.pipeline() for key in keys: pipe.delete(key) pipe.delete(f"tag:{tag}") await pipe.execute()
Usage
cache = TaggedCache(redis)
Cache a product page (depends on product and its category)
await cache.set( "page:product:42", rendered_html, tags=["product:42", "category:electronics", "pricing"], )
Cache a category listing
await cache.set( "page:category:electronics", listing_html, tags=["category:electronics"], )
When product 42 price changes, invalidate everything related
await cache.invalidate_tag("product:42") await cache.invalidate_tag("pricing")
Advantages: No explicit invalidation needed. No race condition between invalidation and re-caching. Old entries expire naturally.
Disadvantages: Orphaned cache entries waste memory until TTL expires. The version counter is a hot key that must survive Redis restarts (use persistence or accept one cache miss after restart).
Thundering Herd Mitigation
When a popular cache entry expires, hundreds of concurrent requests all miss the cache and hit the database simultaneously. This is the thundering herd (or cache stampede) problem.

Solution 1: Mutex Lock
Only one request fetches from the database. Others wait for the cache to be repopulated.
Solution 2: Probabilistic Early Expiration
Recompute the cache entry before it actually expires. Each request has a small probability of triggering a refresh as the TTL approaches.
This is the XFetch algorithm from Vattani et al. With beta=1.0, the probability of early refresh increases smoothly as the TTL decreases, spreading recomputation across time instead of concentrating it at the expiry moment.
Solution 3: Stale-While-Revalidate
Serve stale data immediately while triggering an async refresh in the background.
This trades freshness for latency — the user gets an instant response (possibly stale), and the next request gets fresh data.
Multi-Layer Cache Consistency
Many applications use multiple cache layers: in-process (L1) → Redis (L2) → database:
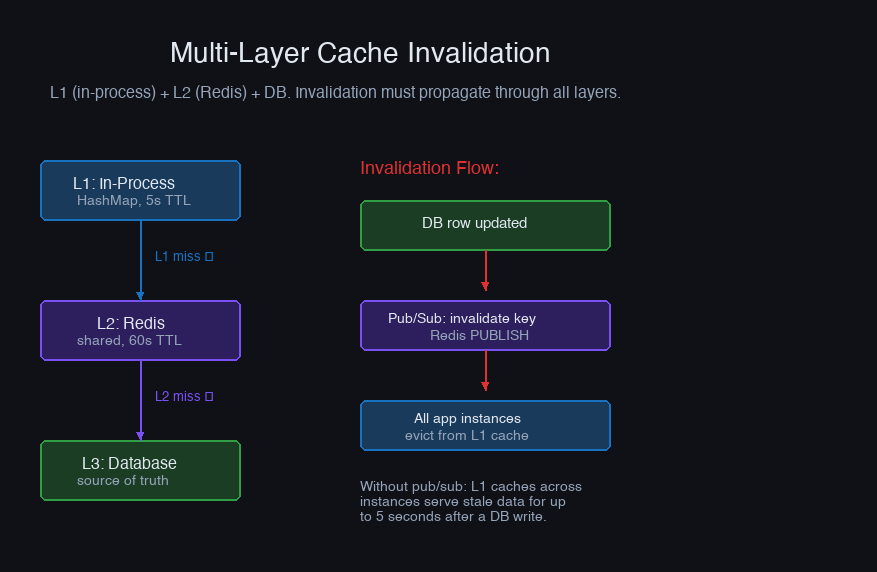
Invalidation must propagate through all layers. The common approach: invalidate L2 (Redis) and use Redis pub/sub to notify all application instances to invalidate their L1:
Gotcha: Pub/sub is fire-and-forget. If an instance misses a message (network blip, restart), its L1 cache will serve stale data until the L1 TTL expires. Keep L1 TTLs short (30-60 seconds) to bound the staleness window.
Cache invalidation is a spectrum. Pure TTL is the simplest but gives the least control. CDC-based invalidation gives near-real-time freshness but adds infrastructure. Tag-based and version-based approaches fall in between. Choose based on how stale your users can tolerate and how much operational complexity you can absorb.
More in System Design
Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.
Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.