Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.

Akhil Sharma
April 4, 2026
Building a Distributed Job Scheduler
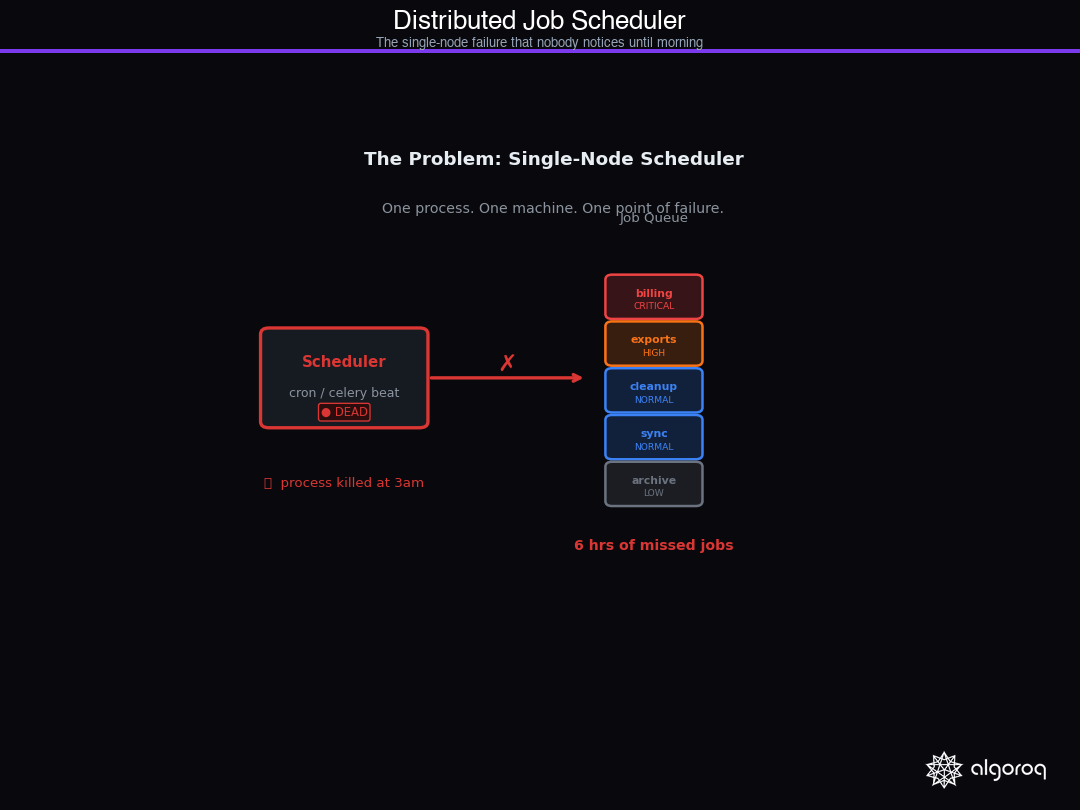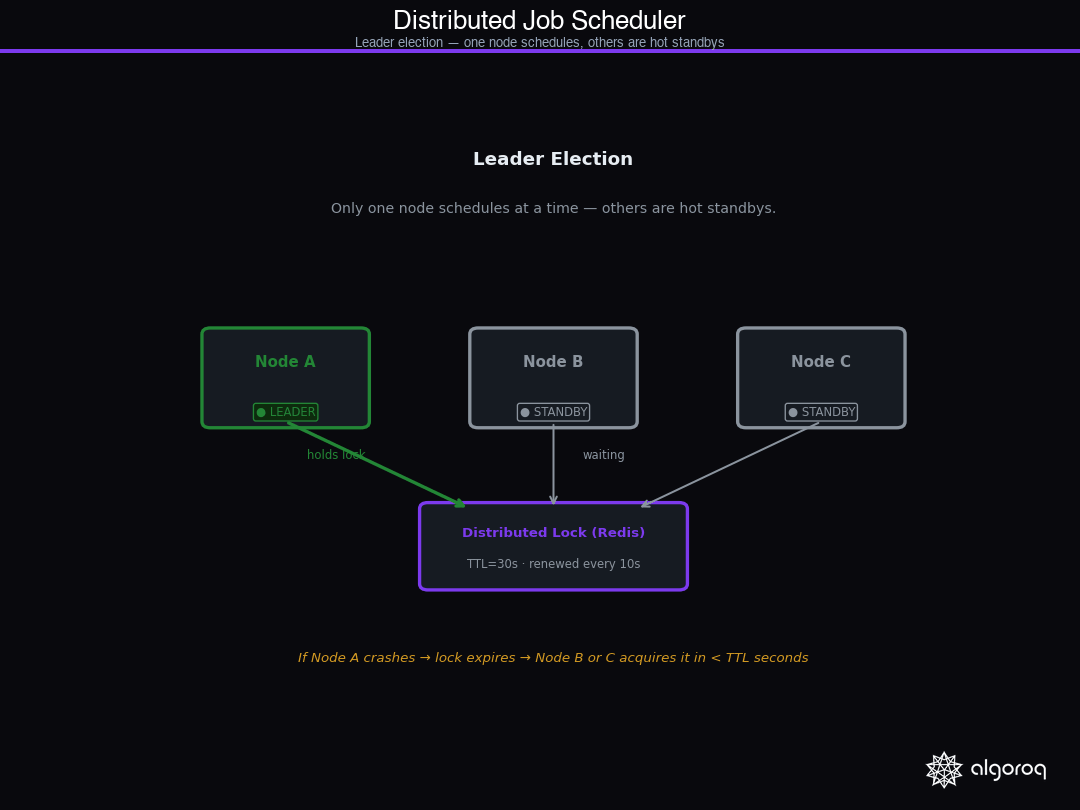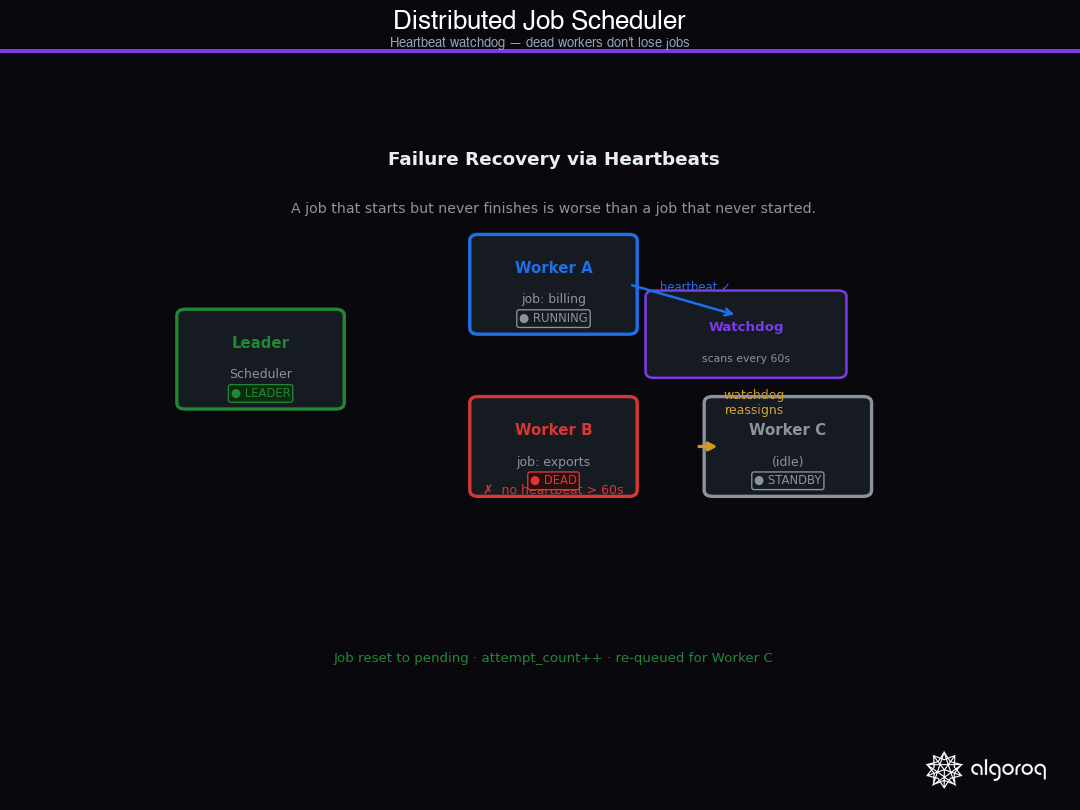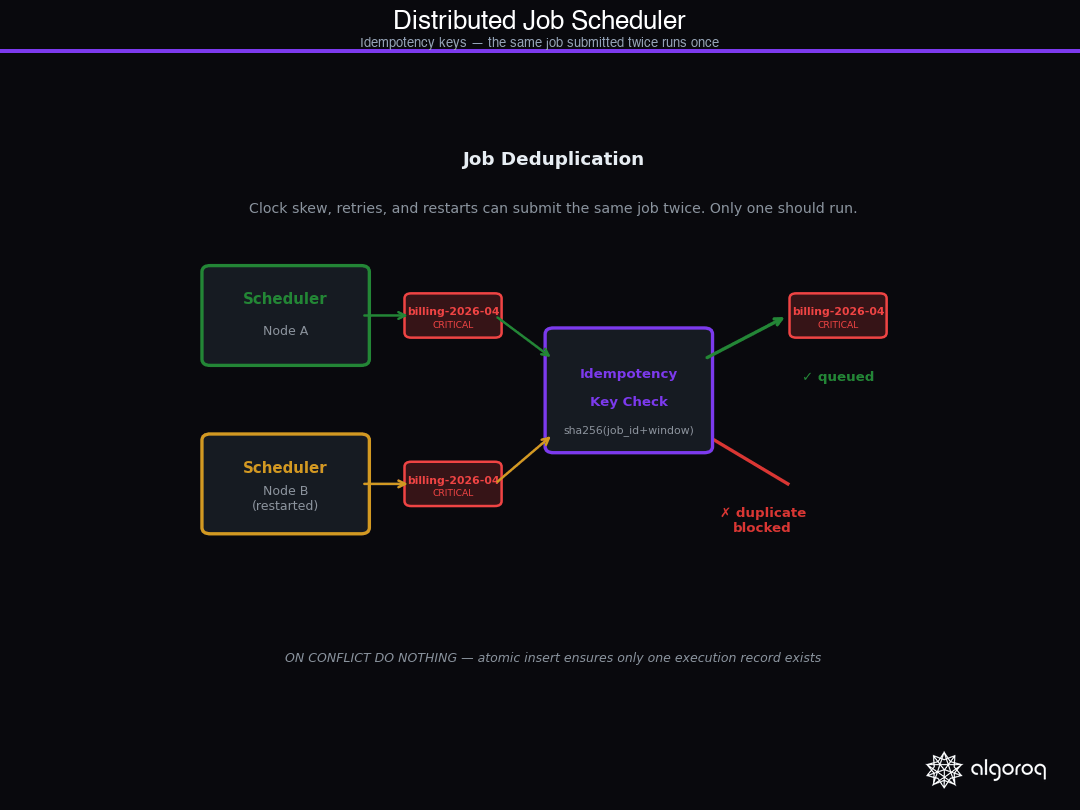
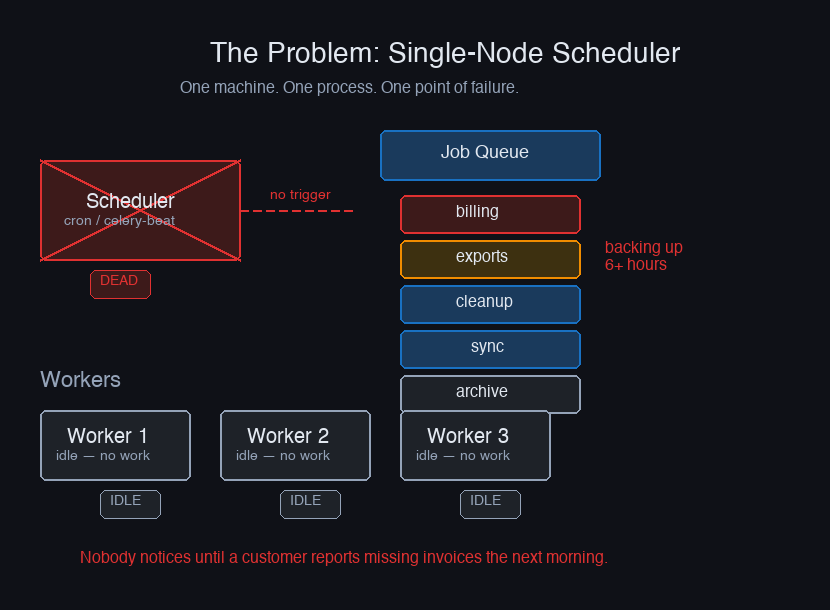
Cron is the oldest and most widely deployed job scheduler in the world. It's also the one most likely to silently fail at the worst possible moment. Your machine goes down at 3am, nobody notices, and by morning the billing jobs haven't run in 6 hours, the nightly data exports are stale, and the cleanup tasks that prevent your database from bloating have been skipped. Cron doesn't alert you. It doesn't retry. It just doesn't run.
The obvious fix is to run your scheduler on more than one machine. That introduces a different problem: two machines running the same billing job simultaneously. Double charges, duplicate emails, corrupted aggregations. The distributed job scheduler problem isn't just "how do we avoid single points of failure" — it's "how do we avoid single points of failure without creating duplicate execution."
Those two requirements are in tension. Resolving that tension is where most scheduler designs go wrong.
Why Exactly-Once Scheduling Is a Lie
Before diving into architecture, the expectation to set: exactly-once execution in a distributed system is impossible in the general case. Networks partition. Processes crash after starting work but before confirming completion. The best you can realistically achieve is at-least-once execution with idempotent jobs.
The implications are architectural. Every job in your system needs to be designed to handle being run twice. A job that sends an email needs to check if that email was already sent. A job that processes invoices needs to check if that invoice was already processed. This isn't optional — it's the price of fault tolerance.
Once you accept that, you stop trying to build a scheduler that guarantees exactly-once, and start building one that minimises duplicate execution while handling failures gracefully.
The Single-Node Failure Modes
A naive single-node scheduler fails in three distinct ways that are worth naming, because they each require different design responses:
The dead scheduler. The machine running your cron/scheduler process dies. Jobs don't run. Nothing alerts. You find out from a customer. The response: multiple scheduler nodes with leader election — only one runs jobs at a time, but others are ready to take over.
The slow job. A job is scheduled every 5 minutes. One run takes 7 minutes. The next scheduled run starts while the first is still in flight. Now you have two instances of the same job running concurrently. The response: job locking with heartbeats — a running job holds a lock that prevents re-scheduling until it releases.
The lost job. A scheduler triggers a job, the worker crashes after starting but before completing, and the scheduler marks it done because it got an ACK. No retry. The response: heartbeat-based progress tracking — a job is only marked complete when it sends a completion signal, not when it starts.
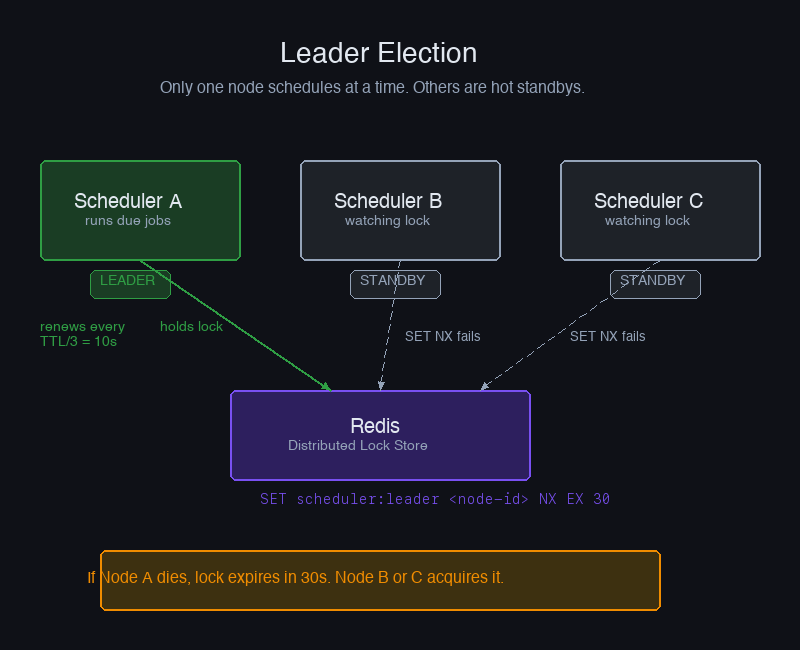
Leader Election: Who Gets to Schedule
With multiple scheduler nodes, you need exactly one of them making scheduling decisions at any time. This is the leader election problem.
The simplest implementation uses a distributed lock with a TTL. The leader holds the lock and renews it periodically. If the leader crashes, the lock expires and a standby node acquires it. The gap between crash and failover is the lock TTL — keep it short (10–30 seconds) but long enough that a momentary network hiccup doesn't trigger unnecessary failover.
The NX flag on SET is the atomicity guarantee — only one node can win the race. The heartbeat renewal at 1/3 of TTL means the leader can miss two renewals before the lock expires, giving it resilience against short network hiccups.
One subtlety: when a node loses leadership (renewal fails), it must immediately stop scheduling. A node that's still running as leader while a new leader is being elected will cause duplicate job execution. The is_leader = False line is critical — it must happen before any further scheduling decisions.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
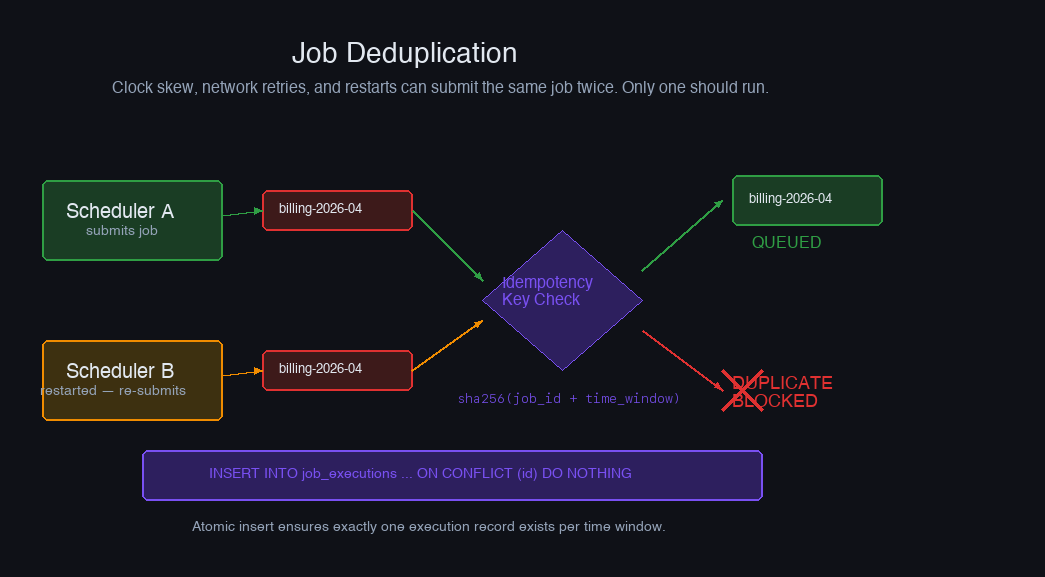
Job Deduplication: The Same Job Submitted Twice
Leader election prevents two scheduler nodes from running jobs simultaneously. It doesn't prevent the same job from being triggered twice by the same leader — for example, if a clock skew causes a job to appear due twice in the same second, or if a network retry causes the job submission to be received twice.
The standard pattern is an idempotency key per scheduled execution:
The idempotency key includes the scheduled time window so that the same job can run again in a later window — you're deduplicating within a scheduling period, not forever.
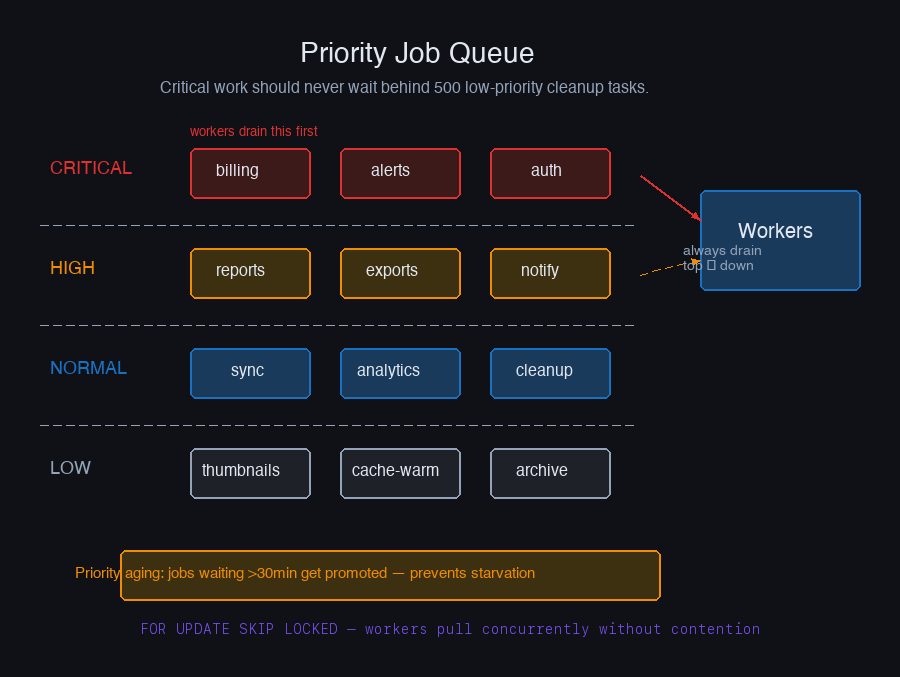
Priority Queues: Not All Jobs Are Equal
A flat queue processes jobs in arrival order. That's fine until your critical billing job is stuck behind 500 low-priority cleanup tasks that all got queued simultaneously after a backlog built up.
Separate queues per priority level are the standard solution. Workers check high-priority queues first, falling through to lower-priority queues only when the high-priority queues are empty.
The risk with strict priority queues is starvation — if CRITICAL is always non-empty, LOW jobs never run. In practice you handle this with priority aging: a job that's been waiting longer than a threshold gets its priority bumped.
FOR UPDATE SKIP LOCKED again — same pattern as webhook delivery workers. Multiple workers can pull from the queue concurrently without contention.
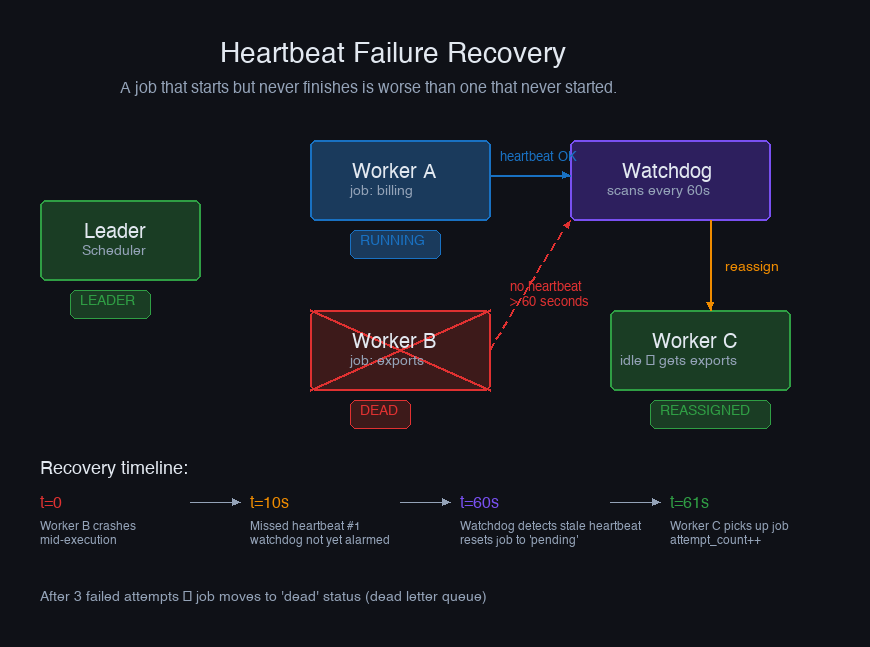
Heartbeats and Failure Recovery
A job starts running. The worker executes half of it and dies — OOM kill, network partition, machine failure. The job record in the database says status = 'running'. Nobody will ever set it to completed or failed. It's stuck.
Heartbeats solve this. A running job sends periodic updates to the database. A watchdog process scans for jobs that haven't sent a heartbeat recently and marks them as failed for retry.
The watchdog timeout should be longer than your heartbeat interval by a comfortable margin — if the heartbeat fires every 10 seconds, a timeout of 60 seconds gives the worker 5 missed heartbeats before being declared dead. Too tight and you'll prematurely reap healthy workers that are just slow on a particular execution.
The Schema That Ties It Together
Two partial indexes: one for the worker queue poll (pending jobs ordered by priority and run time), one for the watchdog (running jobs to check heartbeat freshness). Both are filtered to their specific status so they stay small and fast.
When to Reach for Temporal Instead
This architecture handles the common case well. Where it breaks down:
Long-running workflows. If a job takes 4 hours and has multiple checkpointed stages, polling a heartbeat every 10 seconds and retrying from scratch on failure is wasteful. Temporal and AWS Step Functions are designed for durable multi-step workflows with fine-grained checkpointing.
High fan-out. A job that spawns 10,000 sub-tasks, waits for all of them, and then aggregates results requires coordination that a simple job queue doesn't handle cleanly. Temporal's child workflows and Celery's chord primitive exist for this pattern.
Cross-service orchestration. When a "job" is really a sequence of API calls to external services with compensating transactions on failure, you're in saga territory — a job scheduler is the wrong abstraction.
For everything else — scheduled cron-style jobs, background processing queues, retry-with-backoff pipelines — the Postgres-backed distributed scheduler described above handles millions of jobs per day without exotic infrastructure. The leader election adds one Redis call per heartbeat interval. The watchdog is a simple polling query. The total operational surface is small: one database, one Redis, and worker processes you already know how to run.
The hardest part isn't the engineering. It's accepting that exactly-once is off the table, designing every job to be idempotent, and building the observability to know when a job was executed twice before anyone notices the consequences.
More in System Design
Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.
Designing a Reliable Webhook Delivery System
How to build a webhook delivery system that handles retries, dead letter queues, and delivery guarantees without hammering failing endpoints or losing events.