Designing a Reliable Webhook Delivery System
How to build a webhook delivery system that handles retries, dead letter queues, and delivery guarantees without hammering failing endpoints or losing events.

Akhil Sharma
April 2, 2026
Designing a Reliable Webhook Delivery System
Sending a webhook looks trivial. Make an HTTP POST, check the status code, done. Then you hit production and discover that your customer's endpoint goes down for 20 minutes during a deploy, your retry logic hammers it with hundreds of requests the moment it comes back, and you've now caused an outage on their side. Congratulations — you built a reliable system that reliably causes cascading failures.
Webhook delivery is an at-least-once messaging problem with an external party on the other end. That last part is what makes it genuinely hard. When your own systems fail, you control the recovery. When your customer's system fails, you're sending requests into a black box and making decisions about their health based only on HTTP status codes and timeouts. Every design decision — retry cadence, circuit breaking, dead letters — is really about how gracefully you behave when things outside your control go wrong.
Why "Just Retry" Isn't a Strategy
The naive approach is: if the request fails, retry it. The problem is that failure is rarely random. Endpoints go down in bulk — a bad deploy takes out an entire customer's infrastructure, and now every webhook destined for that customer is failing simultaneously. If your retry logic fires all of them again at the same interval, you've just turned one customer's deploy into a synchronized thundering herd that hits their endpoint the instant it comes back up.
There's also the question of what "failure" means. A 400 Bad Request is not the same as a 503 Service Unavailable. A 400 means your payload is malformed — retrying will produce the same 400 forever and accomplish nothing except filling your retry queue with garbage. A 503 means their server is temporarily overloaded — retrying with backoff makes sense. Treating all failures identically is one of the most common mistakes in webhook implementations.
The right mental model is: webhook delivery is a distributed system problem, not an HTTP problem. Once you see it that way, the solutions become obvious.
The Delivery Pipeline
The first instinct is to deliver webhooks inline — event happens, HTTP request fires, done. This works until it doesn't, and when it doesn't, you've lost the event. The correct architecture persists the event before attempting delivery, so a process crash never loses a webhook.
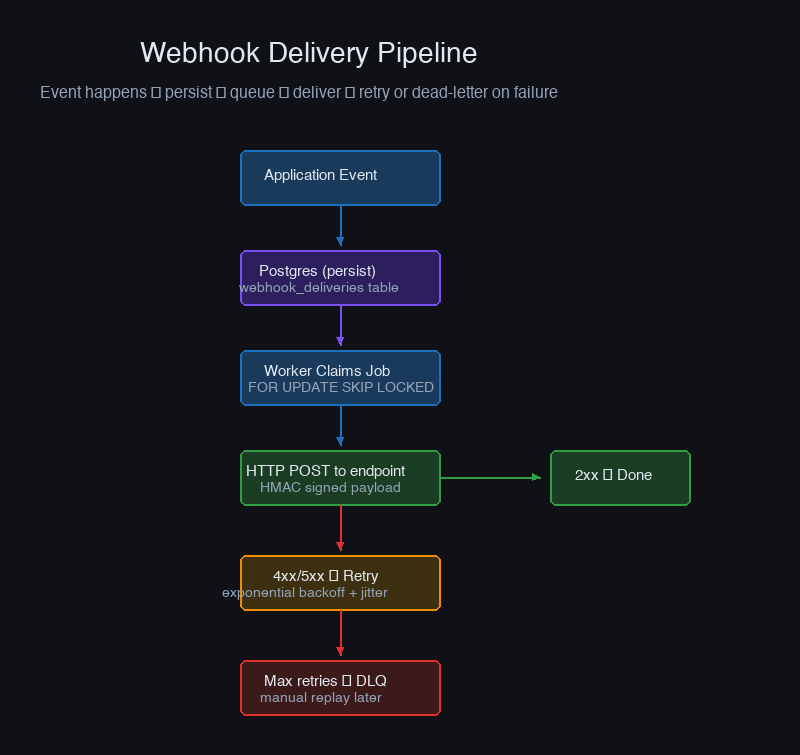
The worker is the heart of the system. It polls the database for deliveries that are due, claims them atomically, attempts delivery, and either marks them delivered or schedules a retry. The key insight here is that the database is the queue — you don't need a separate message broker. Postgres with a good index handles tens of thousands of pending deliveries without breaking a sweat.
The schema that supports this:
The partial index (WHERE status = 'pending') is the detail that keeps this performant at scale. The worker only cares about pending deliveries — indexing all statuses would bloat the index with millions of delivered rows that the worker never needs to read.
The Thundering Herd Problem (and How Jitter Solves It)
Imagine 500 webhooks all failing at 2:00pm because a customer's endpoint went down. With a fixed 60-second retry interval, all 500 will retry at 2:01pm. The endpoint just came back up — and now it receives 500 simultaneous requests. If it can't handle that burst, it goes down again. Your retries just caused the second outage.

Exponential backoff alone doesn't fully solve this. If all 500 failed at the same time, exponential backoff without jitter still causes all 500 to retry at the same exponentially-increasing intervals — just synchronized bursts instead of a single burst.
The fix is full jitter: instead of delay = base * 2^attempt, use delay = random(0, base * 2^attempt). This randomizes each delivery's retry across the entire window, so instead of 500 requests hitting at 2:01pm, they spread across a 2-minute window.
What this looks like in practice for a delivery that keeps failing:
| Attempt | Window | What's happening |
|---|---|---|
| 1 | 0–60 sec | Fast first retry — transient failures often self-heal |
| 2 | 0–2 min | Still probably transient |
| 3 | 0–4 min | |
| 5 | 0–16 min | Endpoint is probably having a real problem |
| 10 | 0–1 hour | Backing off significantly |
| 15 | 0–1 hour (capped) | Final attempts before dead letter |
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
This schedule gives fast recovery for transient failures (a blip that lasts 30 seconds will be retried promptly) while backing off aggressively for sustained outages (a broken deploy that lasts 2 hours won't be hammered constantly).
Claiming Work Without Contention
Running multiple worker processes is essential for throughput and redundancy. The problem: how do two workers avoid claiming the same delivery? Distributed locks are one answer. A better answer is FOR UPDATE SKIP LOCKED — a Postgres feature designed exactly for this pattern.
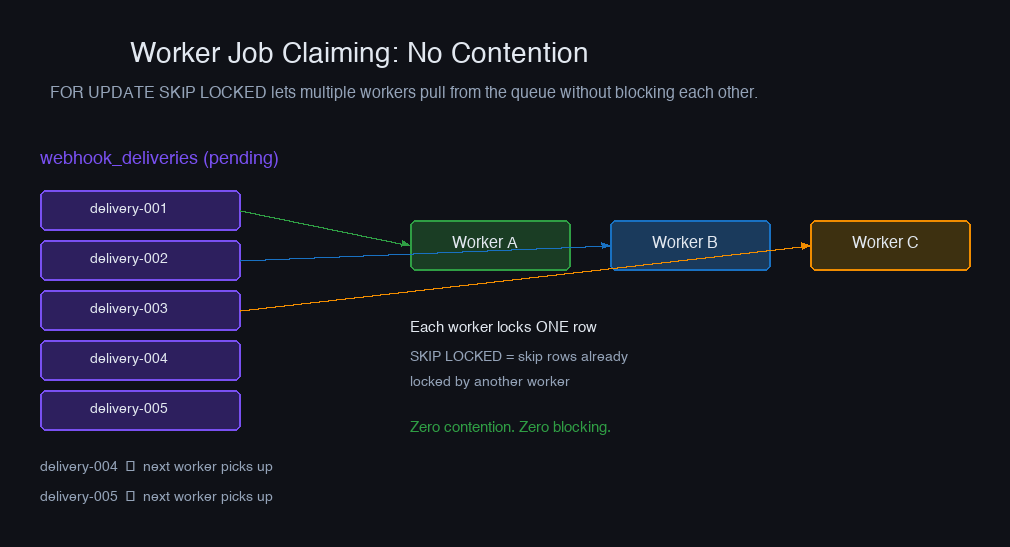
SKIP LOCKED turns what would be a blocking operation (waiting for another worker's lock to release) into a non-blocking one (skip that row, take the next available one). Ten workers can each claim a batch of 50 without any coordination overhead — Postgres handles the contention entirely.
The in_flight status is important here. If a worker claims a batch and then crashes, those deliveries are stuck in in_flight forever. A background process should periodically reset deliveries that have been in_flight for longer than your worker's maximum expected processing time (say, 5 minutes).
Signatures: Don't Skip This
An unsigned webhook is an HTTP POST from an unknown sender to your customer's public endpoint. Any attacker who discovers the URL can forge events. HMAC-SHA256 signatures give receivers a way to verify the payload came from you:
The receiver verifies it like this:
Two details that teams get wrong. First: sign the raw bytes, not the parsed JSON. If you parse and re-serialize, field ordering differences can cause signature mismatches. Receivers should verify against the raw request body before parsing. Second: hmac.compare_digest instead of ==. A naive string comparison returns early on the first differing character, which leaks timing information that an attacker can use to probe for valid signatures.
Not All Failures Are Retryable
This is where most webhook systems get sloppy. There are two fundamentally different kinds of failure:
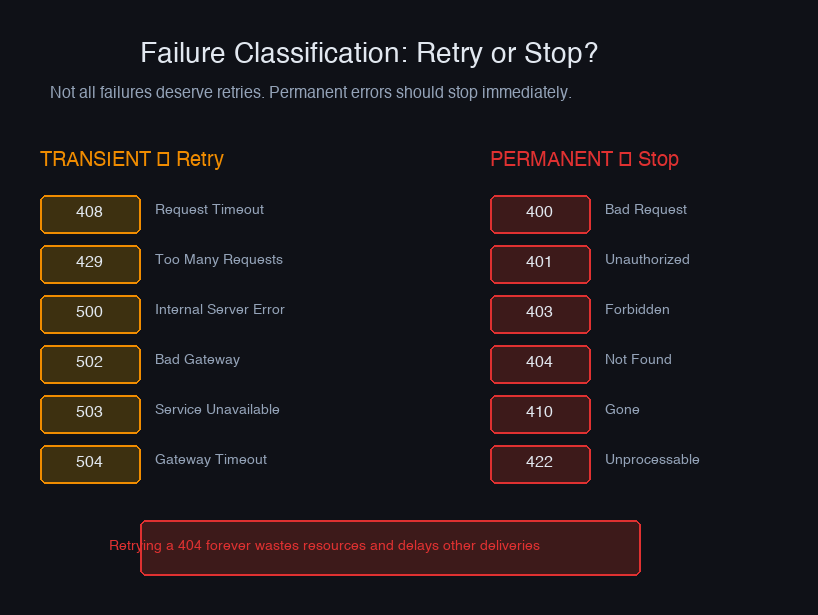
Transient failures — the endpoint is temporarily unavailable. The right response is to retry with backoff. 5xx errors, timeouts, and connection errors fall here.
Permanent failures — something is structurally wrong. No amount of retrying will fix it. The right response is to stop immediately and alert.
Retrying 400s is surprisingly common in the wild. It wastes queue capacity, inflates your retry metrics, and makes it impossible to distinguish real transient failures from misconfiguration. When you get a 400, log the payload, alert the team, and mark the delivery permanently failed. Same for 401 — if the customer's secret rotated and you haven't updated it, no number of retries will ever succeed.
Circuit Breaking Per Endpoint
Retries are per-delivery. Circuit breaking is per-endpoint. The distinction matters.
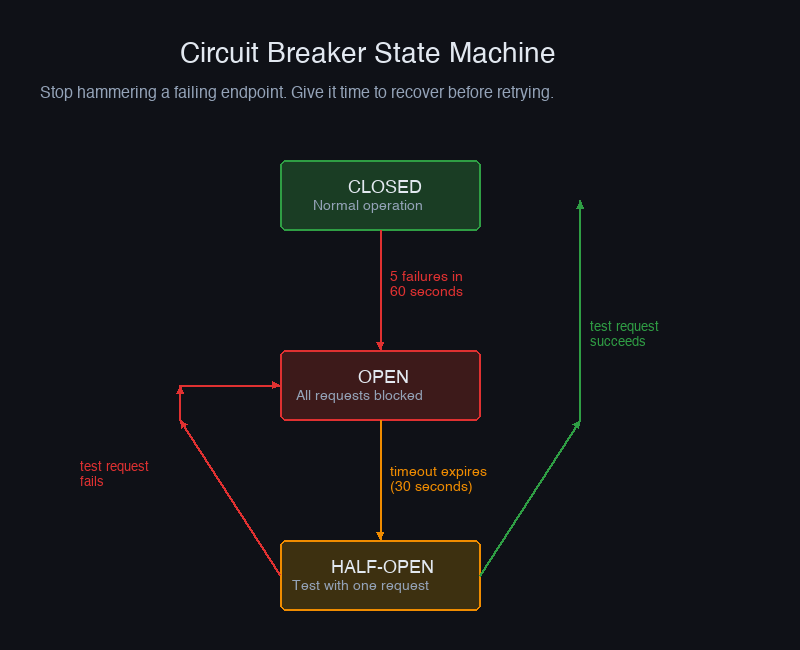
If a customer's endpoint has been failing for 24 hours straight, retrying individual webhooks at hourly intervals is not useful — the endpoint is clearly broken in a sustained way. A per-endpoint circuit breaker detects this and temporarily suspends delivery entirely, which does two things: it stops wasting your worker resources, and it prevents a sudden surge of retries when the endpoint finally recovers.
When an endpoint is in the OPEN state, don't just silently drop deliveries — surface this in your dashboard. The customer needs to know their endpoint is broken and that events are queuing up. Which brings us to the dead letter queue.
The Dead Letter Queue Is Not a Graveyard
Dead letters are deliveries that exhausted all retry attempts. The instinct is to treat this as a loss — the event couldn't be delivered, move on. That's wrong.
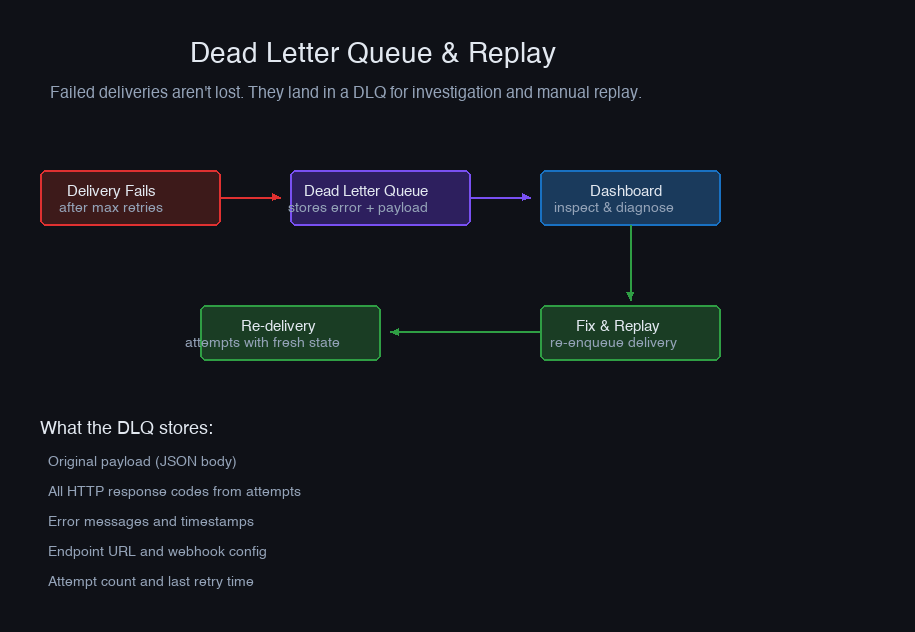
A dead letter queue should be a first-class feature of your webhook system, visible to customers through your dashboard. When their endpoint comes back up and they fix whatever was broken, they need to be able to replay the missed events. Without replay, a 2-hour outage on their side means 2 hours of events permanently lost from their perspective — and that erodes trust faster than any bug.
Expose this through your API and dashboard. The ability to say "your endpoint was down between 2pm and 4pm, here are the 847 events that failed, click replay to reprocess them" is a genuinely powerful feature. It turns a support escalation ("we missed events") into a self-service action.
Ordering and Idempotency: Set Expectations Clearly
Two properties your customers will ask about, and you should be honest about both.
Ordering: webhooks are not ordered. A retry of event #5 can arrive after event #6, because the retry delay for #5 might be longer than the initial delivery of #6. Don't promise ordering. Include an event_sequence field and a timestamp in every payload so receivers can detect and handle out-of-order delivery if they need to. If a customer tells you ordering is critical, help them build a consumer that buffers and reorders — don't promise a guarantee you can't keep.
Idempotency: webhooks are at-least-once. A successful retry means the receiver got the event twice. Include a stable delivery_id in every request header and payload:
Receivers should use this to deduplicate. Document this in your API docs. The delivery ID doesn't change across retries — it identifies this specific delivery, not this specific attempt.
Monitoring: What to Watch
Metrics that tell you the system is healthy:
- First-attempt success rate — should be >98%. If it's lower, your payload format or authentication might be broken for certain endpoints.
- p99 delivery latency — time from event creation to first delivery attempt. Should be under 5 seconds for most systems.
- Retry queue depth by attempt number — a spike in attempt-3+ deliveries means a customer has a sustained outage.
- Dead letter queue depth — should trend toward zero. A growing DLQ means events are being permanently lost and customers haven't triggered replay.
- Circuit-opened endpoints — alert immediately when an endpoint opens. This is a customer-facing issue.
The metric most teams skip is attempt distribution. If your p50 is attempt 1 (most deliveries succeed first try), your system is healthy. If p50 is attempt 3, something systemic is wrong — either with your payloads, your customers' infrastructure, or your own reliability.
Webhook delivery is a support surface as much as a technical system. Every dead letter is a potential support ticket. Every retry storm is a potential customer complaint. Build it like you'll be on call for it — because you will.
More in System Design
Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.
Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.