Distributed Rate Limiting with Redis and Sliding Windows
Implementing distributed rate limiting with token bucket and sliding window algorithms in Redis, including Lua scripts for atomicity and multi-region challenges.

Akhil Sharma
January 3, 2026
Distributed Rate Limiting with Redis and Sliding Windows
Rate limiting sounds simple until you distribute it. A single-process token bucket takes 20 lines of code. A distributed rate limiter that handles multi-region deployments, clock skew, and Redis failover without either dropping legitimate traffic or letting abuse through — that's a systems problem.
Why Local Rate Limiting Fails
If you're running 10 instances of your API server behind a load balancer, a per-instance rate limit of 100 req/min gives an effective limit of 1,000 req/min. Worse, the limit depends on which instance the load balancer routes to — a single user could get 100 requests on each instance.
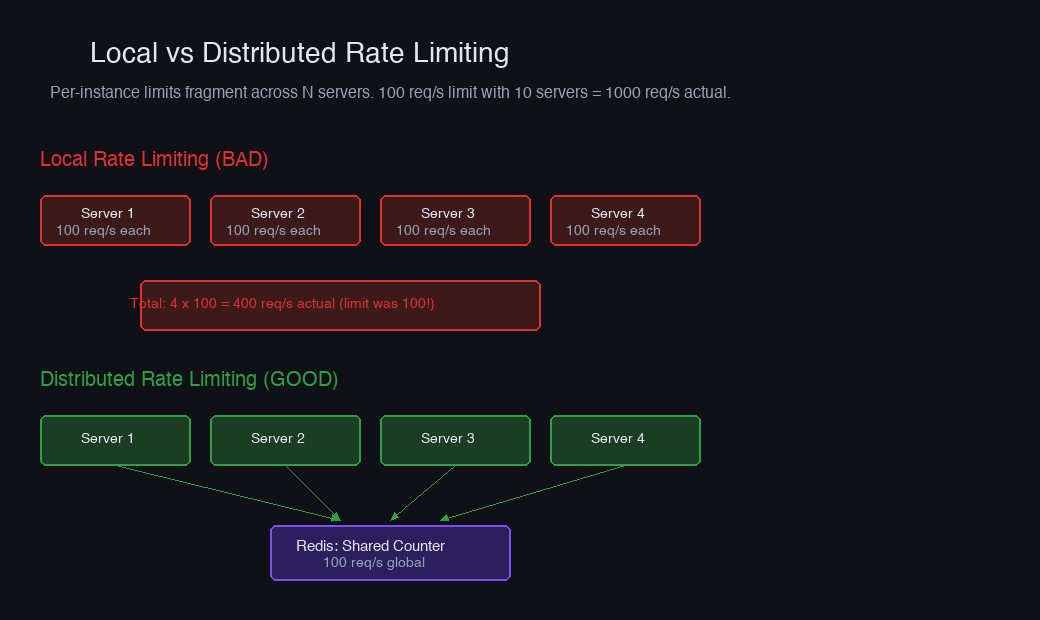
You need shared state. Redis is the standard choice because it's fast (~0.1ms for simple operations), widely deployed, and supports atomic operations via Lua scripting.
Algorithm 1: Fixed Window Counter
The simplest approach. Count requests in discrete time windows (e.g., per minute). When the count exceeds the limit, reject.

The boundary problem: A user can send 100 requests at 12:00:59 and another 100 at 12:01:01 — 200 requests in 2 seconds, despite a 100/minute limit. Fixed windows allow burst at boundaries.
Algorithm 2: Sliding Window Log
Store the timestamp of every request. Count requests within the sliding window. No boundary problem, but memory-intensive.

Trade-off: Accurate but stores one sorted set member per request. At 1,000 req/min, that's 1,000 entries per user per minute. For high-volume APIs, memory consumption becomes significant.
Algorithm 3: Sliding Window Counter (The Sweet Spot)
Combines fixed window counting with weighted interpolation. Uses two adjacent fixed windows and weights them by how far into the current window we are.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts 2nd July 2026 — 20 seats.
current_key = f"ratelimit:{user_id}:{current_window}" previous_key = f"ratelimit:{user_id}:{current_window - 1}"
Trade-off: Flexible burst control. A bucket with rate=10/s and capacity=50 allows bursts of up to 50 requests, then sustains 10/s. Good for APIs where occasional bursts are acceptable but sustained abuse isn't.
Race Conditions and Atomicity
All the Lua scripts above execute atomically in Redis — this is why they're Lua scripts and not multi-step Redis commands. A naive implementation using GET then SET has a race window:
Lua scripts in Redis are atomic. Both threads can't interleave within the script. This is non-negotiable for correctness.
Multi-Region Challenges
When your API runs in multiple regions, each with its own Redis, the rate limit fragments:
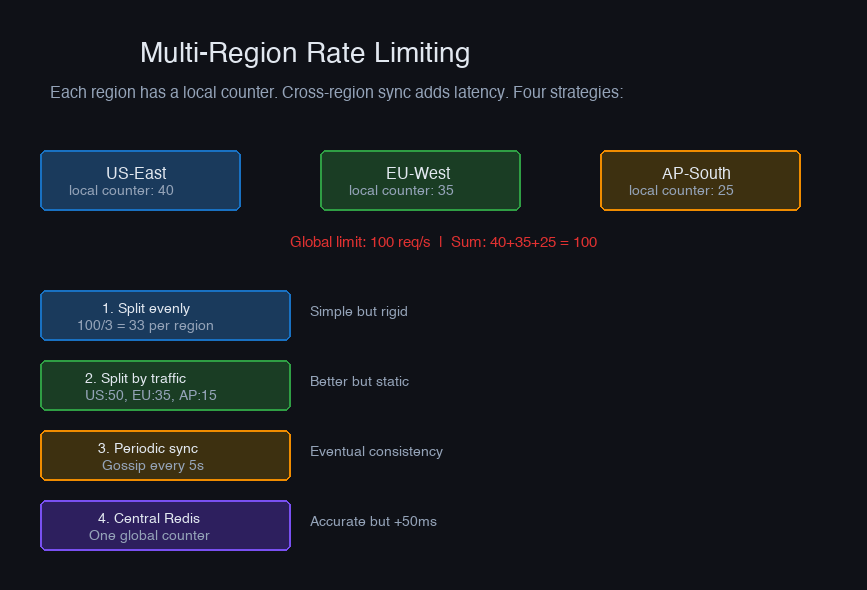
Options:
1. Global Redis (single region): All rate limit checks go to one Redis. Simple but adds cross-region latency (50-150ms). Acceptable for server-to-server APIs, not for user-facing endpoints.
2. Local Redis with reduced limits: Each region gets limit/N. Simple but wastes capacity when traffic is uneven (US gets 80% of traffic but only 50% of the budget).
3. Gossip-based synchronization: Each region maintains a local counter and periodically shares counts with other regions. Allows brief over-limit bursts (between sync intervals) but distributes the limit proportionally.
4. CRDTs (Conflict-free Replicated Data Types): Use a G-Counter CRDT where each region increments its own counter and the global count is the sum. Redis doesn't natively support CRDTs for this, but you can implement it:
Redis Failover
What happens when Redis goes down? You have two choices:

Fail open: Allow all requests when Redis is unavailable. Your API stays up but rate limiting is disabled. Acceptable for non-critical rate limits, dangerous for abuse prevention.
Fail closed: Reject all requests when Redis is unavailable. Protects against abuse but causes an outage. Use this only for rate limits that protect critical resources.
Practical approach: Use a local in-memory fallback. When Redis is unreachable, fall back to a per-instance rate limit with a conservative threshold. It won't be perfectly accurate, but it prevents both total abuse and total outage.
Response Headers
Always include rate limit information in response headers so clients can self-regulate:
This isn't just good practice — it reduces the load from well-behaved clients that check headers before retrying. Poorly behaved clients will hammer your endpoint regardless, but at least you've given good clients the information they need.
The choice between these algorithms depends on your tolerance for boundary bursts, memory constraints, and whether you need burst control. For most APIs, sliding window counter gives the best accuracy-to-cost ratio. Add token bucket when you need explicit burst parameters. And always use Lua scripts for atomicity — the race condition isn't theoretical, it will cause real over-limit admissions under load.
More in System Design
Building a Distributed Job Scheduler
Why single-node job schedulers silently fail in production, and how to build a distributed scheduler with leader election, task deduplication, and failure recovery.
Consistent Hashing in Practice
Why modulo hashing silently nukes your cache every time you scale, and how consistent hashing solves the rebalancing problem that takes down databases.