Designing for Multi-Tenancy at Scale
The real trade-offs between database-per-tenant, schema-per-tenant, and shared schema isolation models — covering noisy neighbor mitigation, row-level security, tenant-aware connection pooling, and the hybrid model most teams eventually land on.

Akhil Sharma
April 9, 2026
Designing for Multi-Tenancy at Scale
Your first 100 customers were easy. Add a tenant_id column to every table, throw a WHERE clause on every query, and call it done. Isolation handled.
Then you hit 2,000 customers and discover three problems arriving at roughly the same time. A database migration that takes 30 seconds on one schema is taking 4 hours because it's running sequentially across every tenant schema. One customer is running an unbounded analytics query that's eating 80% of your database IOPS and causing timeout errors for everyone else. And then, quietly, you discover that a bug from last quarter was missing a tenant filter and has been leaking rows across tenant boundaries for six weeks.
These are the three fundamental failure modes of multi-tenancy at scale: operational overhead, noisy neighbor interference, and data leakage. Every architectural decision you make — isolation model, connection pooling strategy, migration approach — is really about where you're willing to take the hit on each one. You can't eliminate all three simultaneously. The goal is to understand the trade-offs well enough to choose the right pain.
The Multi-Tenancy Spectrum
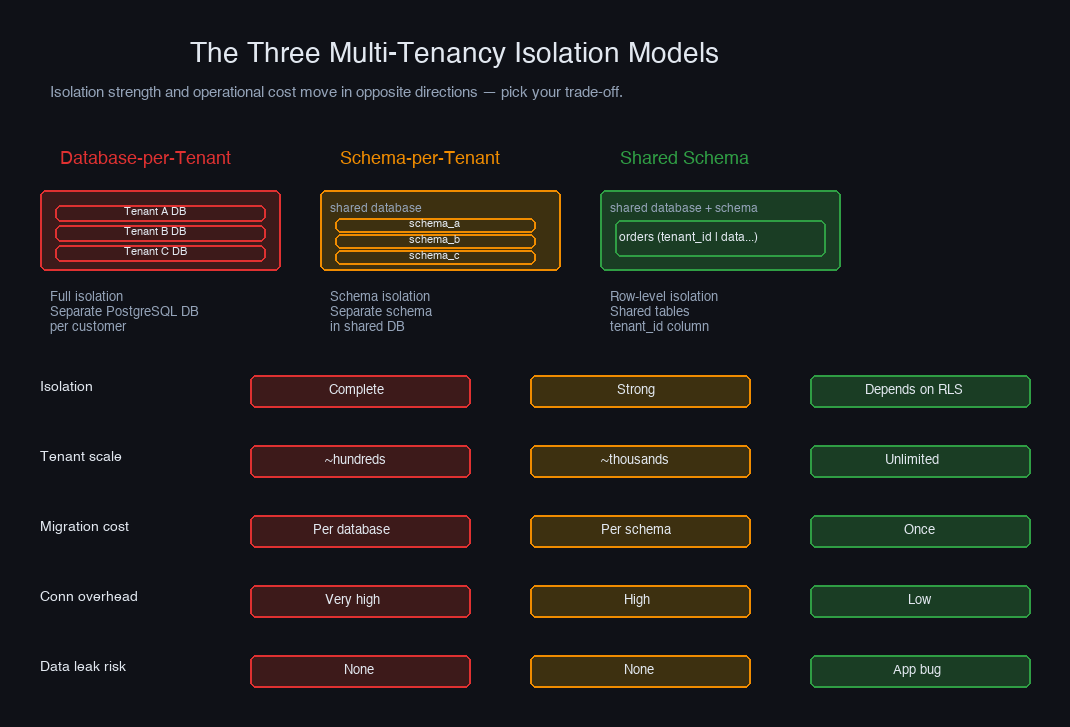
Multi-tenancy exists on a spectrum with isolation strength and operational cost moving in opposite directions. The further you push toward complete isolation, the higher the infrastructure overhead. The further you push toward resource sharing, the more careful your application code needs to be.
The three canonical models are:
| Database-per-Tenant | Schema-per-Tenant | Shared Schema | |
|---|---|---|---|
| Isolation | Complete | Strong | Depends on implementation |
| Tenant limit | ~hundreds | ~thousands | Unlimited |
| Migration cost | Per database | Per schema | Once |
| Cross-tenant ops | Complex | Moderate | Simple |
| Connection overhead | Very high | High | Low |
| Data leakage risk | None | None | Application bug |
| Best for | Regulated, enterprise | Mid-market SaaS | High-scale B2C |
No model is universally correct. The right choice depends on your tenant count, regulatory requirements, and how much operational complexity you can absorb. Most serious multi-tenant systems eventually end up with a hybrid — different isolation models for different customer tiers.
Database-per-Tenant: Complete Isolation, Real Costs
In the database-per-tenant model, every customer gets their own PostgreSQL database (or cluster). Data is physically separated: no shared tables, no cross-tenant query risk, no noisy neighbor at the database layer.
This model is correct when correctness and compliance require it. HIPAA, SOC 2 Type II with dedicated environments, financial services with data residency requirements, and enterprise contracts with SLAs that specify physical isolation — these are the scenarios where database-per-tenant isn't overkill, it's the only acceptable answer.
The cost you pay:
Connection overhead alone becomes a serious problem. PostgreSQL spawns a backend process for each connection. At 1,000 tenants with a modest connection pool of 20 per database, you have 20,000 potential connections. Your operating system will object.
PgBouncer can pool connections per database, but you need a PgBouncer instance (or pool configuration) per tenant — which just moves the configuration management problem around. Cross-tenant operations (analytics, billing aggregation, admin dashboards) require application-level joins across databases or a separate ETL pipeline. Schema migrations require a migration runner that iterates across databases and handles failures without leaving tenants on different versions.
Database-per-tenant is operationally tractable at hundreds of tenants. At thousands, the operational burden typically exceeds the isolation benefit for most applications.
Schema-per-Tenant: Isolation Without the Connection Tax
Schema-per-tenant keeps all tenants in a single PostgreSQL database but gives each their own schema — a namespace containing their own copy of every table. A search_path change routes queries to the right schema, and data is logically separated at the schema level.
You get strong isolation (a bug that forgets a tenant filter can't cross schema boundaries), shared connection pools (one database, one PgBouncer), and simpler cross-tenant operations compared to separate databases. This is genuinely the right model for mid-market SaaS with hundreds to a few thousand tenants.
The problem that nobody warns you about is migrations.
Suppose you need to add an index. On one schema, it takes 2 seconds. On 2,000 schemas, it takes 2,000 × 2 = over an hour — in the best case, with perfect parallelism. In reality, you'll run migrations in batches to avoid connection exhaustion, serializing some of the work. And that assumes the migration succeeds on every schema. When it fails on schema 847 out of 2,000, you need to track which schemas are on which version, handle partial failures gracefully, and make sure your application works during the window where some schemas are migrated and some aren't.
You also hit PostgreSQL's practical schema limit around 10,000 schemas per database — not a hard ceiling, but catalog bloat starts affecting performance well before that. If you anticipate surpassing it, shared schema becomes necessary.
Shared Schema: One Table, Every Tenant
In the shared schema model, all tenants share the same tables, differentiated by a tenant_id column. It's the most operationally efficient model: one database, one schema, one migration per change. Migrations take seconds regardless of tenant count. Cross-tenant queries for analytics are just SQL. Connection pooling is straightforward.
The index design deserves attention. Every query that touches a shared table should use tenant_id as the leading index column. Without it, a customer lookup on a 10-million-row orders table scans rows belonging to all tenants to find the ones for the current tenant. With it, the scan is bounded to that tenant's rows — effectively giving you the performance characteristics of a per-tenant table, without the schema proliferation.
The danger in shared schema is data leakage. It takes one missing WHERE clause:
This class of bug is silent, hard to detect in tests, and potentially catastrophic for your customers' trust. Which is exactly the problem row-level security was designed to solve.
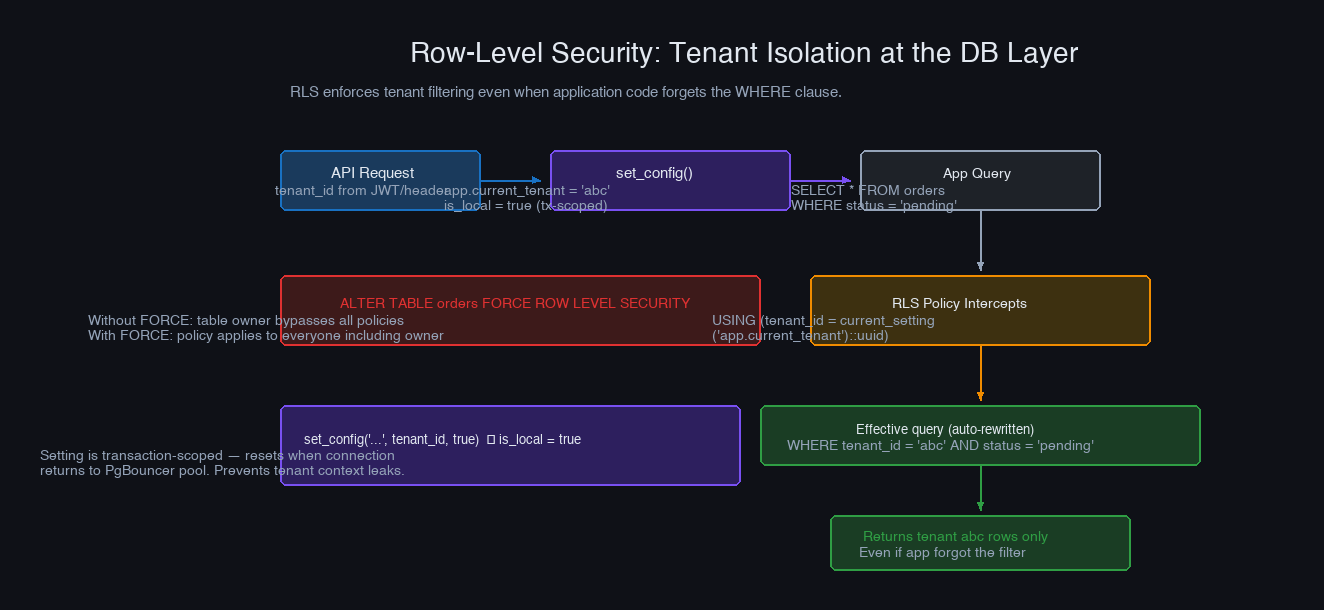
Row-Level Security: Isolation You Cannot Accidentally Bypass
PostgreSQL's Row-Level Security (RLS) lets you define policies at the database level that restrict which rows a session can see — regardless of what the application query says. Even if a query has no WHERE tenant_id = ... clause, the policy adds it automatically.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts May 10 — 20 seats.
Reserve your spot →-- The same policy applies to INSERT, UPDATE, DELETE unless overridden -- For INSERT, use WITH CHECK instead of USING: CREATE POLICY tenant_insert ON orders AS PERMISSIVE FOR INSERT WITH CHECK (tenant_id = current_setting('app.current_tenant')::uuid);
Two subtleties that cause production pain if you miss them:
FORCE ROW LEVEL SECURITY is not optional. Without it, the table owner (the role your application uses) bypasses RLS entirely. Every application database role that accesses tenant data should be a non-owner role with only the permissions it needs.
set_config with is_local = true sets the parameter for the current transaction only, not the session. This is the correct behavior when using PgBouncer in transaction mode — the connection returns to the pool after the transaction, and the next transaction starts without any tenant context, which is exactly what you want. Using is_local = false with transaction mode pooling means the next transaction on that connection inherits the previous tenant's context.
For admin queries that genuinely need to access all tenants — reporting, billing, operations tooling — use a separate database role that bypasses RLS, and be explicit about it:
The Noisy Neighbor Problem
Shared infrastructure means one tenant's behavior affects everyone else. A customer running a poorly written analytics query — no index, no LIMIT, joining five tables — can hold database locks, exhaust IOPS, and spike CPU for every other tenant in the system.
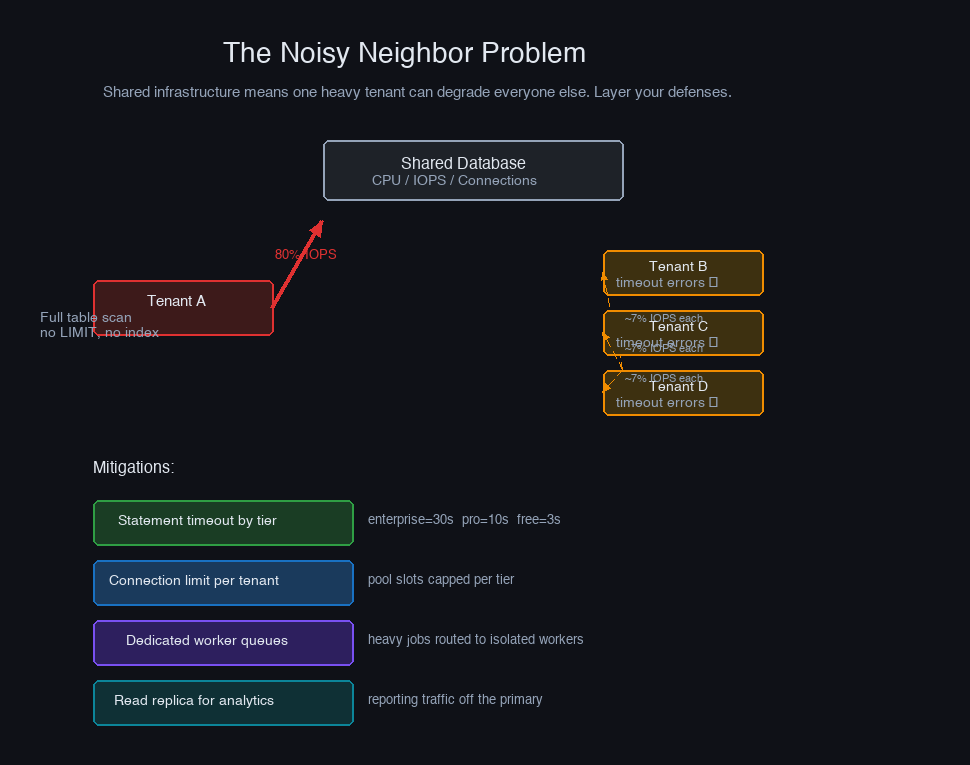
The mitigation is layered:
Statement timeouts prevent any single query from running indefinitely. Set them per tenant tier rather than globally — enterprise customers may have legitimate long-running reports, while free-tier users almost certainly don't:
Connection limits per tenant prevent a single tenant from holding all connections in your pool. PostgreSQL supports per-role connection limits; map each tenant to a role, or enforce limits at the application layer by tracking active connections per tenant and rejecting new ones past a threshold.
Work queue isolation for async jobs is often more important than connection limits. If your system processes background jobs from a shared queue, one tenant submitting 10,000 export jobs can starve every other tenant's jobs for hours. Partition your worker pools: a general pool for routine jobs, and per-tenant or per-tier pools for jobs from customers who have demonstrated heavy usage.
Read replicas for analytics are the cleanest solution for reporting-heavy tenants. Route their analytics queries to a read replica that serves only reporting traffic. This gives them the resources they need without competing with transactional workloads on the primary.
Tenant-Aware Connection Pooling
Connection pooling in multi-tenant systems has a subtle problem: the tenant context you set at the start of a request must not leak to the next request that reuses the connection.
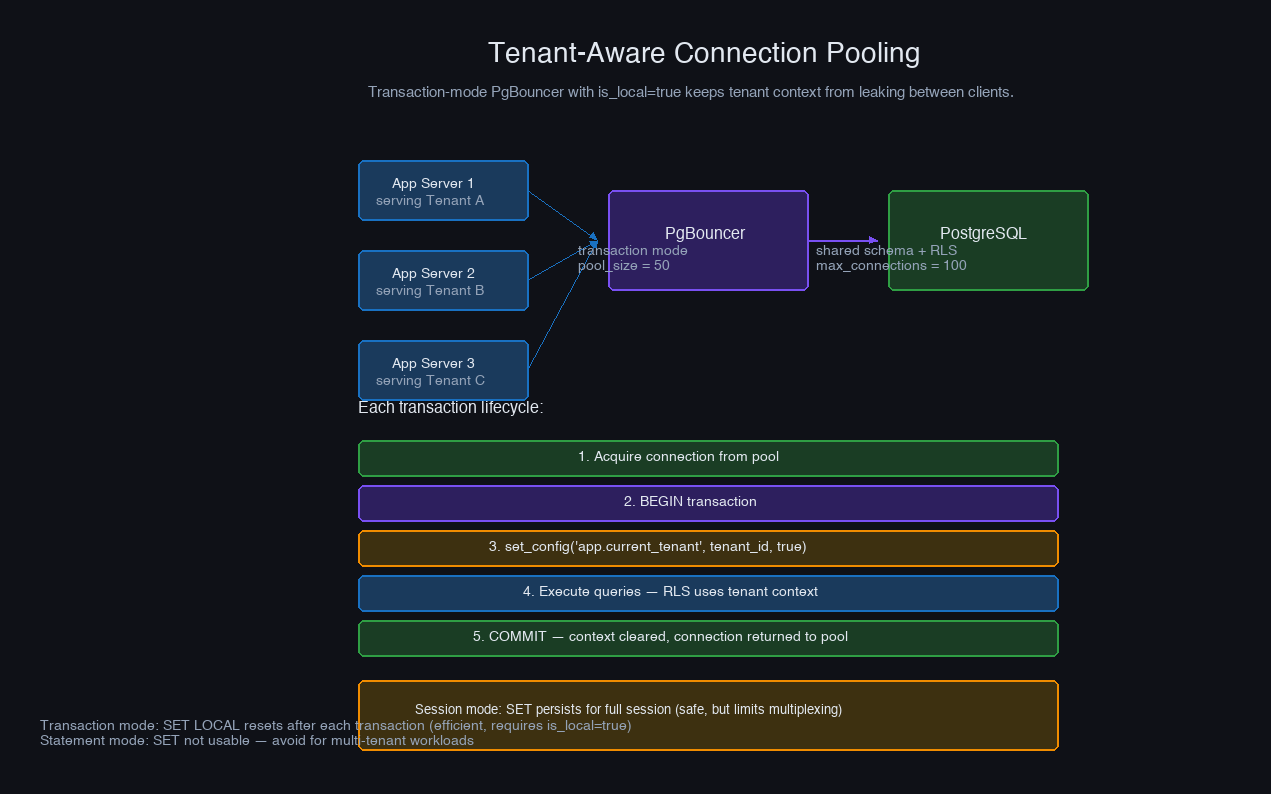
With PgBouncer in session mode, each client holds a backend connection for the entire session. Tenant context set with SET app.current_tenant = ... persists for the connection's lifetime. This is safe — the connection stays with one client — but it severely limits multiplexing. One long-lived application connection holds a PostgreSQL backend for its entire duration.
With PgBouncer in transaction mode, the backend connection is released after each transaction ends and returned to the pool. This is far more efficient (one backend can serve many application clients), but any SET commands issued outside a transaction are lost when the connection returns to the pool. The pattern that works:
One PgBouncer pitfall specific to multi-tenancy: prepared statements. When PgBouncer operates in transaction mode, prepared statements created by one client can be reused by another client that gets the same backend connection. If you're using per-session state to set tenant context, a prepared statement may execute in a context it wasn't prepared in. The fix is to either disable prepared statements (PREPARE threshold to 0 in your ORM), use named prepared statements that include the tenant context in the plan, or use PgBouncer's statement mode for applications that rely heavily on prepared statements.
Migrations at Scale
Migration strategy differs fundamentally between the three isolation models, and this is often the factor that tips a decision.
Shared schema migrations are the simplest: one ALTER TABLE, a few seconds, done. The only complexity is ensuring your application code handles both the pre-migration and post-migration schema during the rollout window — standard expand-contract.
Schema-per-tenant migrations are where teams consistently underestimate the operational complexity. Beyond the batching pattern shown earlier, the key properties you need:
Zero-downtime with schema-per-tenant requires treating the migration window as a first-class operational concern. Your application must support two states simultaneously: tenants on version N and tenants on version N+1. Column additions are safe. Column removals or renames require the expand-contract pattern executed across potentially thousands of schemas.
Database-per-tenant migrations carry the same challenges as schema-per-tenant but also require managing connection strings per tenant, coordinating across potentially different database hosts, and handling version skew between databases that might be on different versions of PostgreSQL itself.
The Hybrid Model: Tier-Based Isolation
Most B2B SaaS products eventually converge on a hybrid model: shared schema for small and free-tier customers, schema-per-tenant for paying customers, and dedicated databases for enterprise customers with isolation requirements.
The routing layer sits in front of all database access and selects the isolation model based on tenant tier:
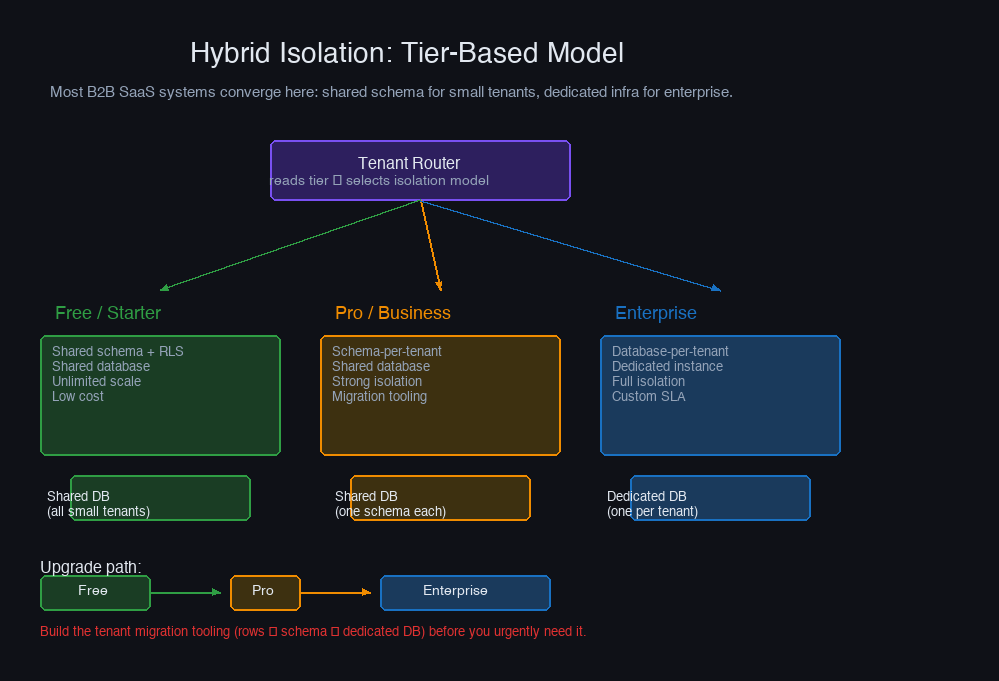
The hybrid model solves the sales problem cleanly: you can genuinely tell enterprise prospects "your data lives in a dedicated database on dedicated infrastructure" without that being true for the 95% of customers who don't need it and wouldn't pay for it. The complexity cost is real — you're maintaining three operational models simultaneously — but it's paid for by the pricing power and deal velocity it enables.
One practical note: plan the migration path from shared to dedicated before you need it. When a customer grows from free to enterprise, you need to export their rows from the shared table, import them into a dedicated database, set up replication or a cutover window, and update the routing configuration — ideally without downtime. Building this migration tooling reactively, under pressure from a customer's legal team, is painful.
Observability: Metrics Per Tenant
Multi-tenancy adds a dimension to your observability stack that doesn't exist in single-tenant systems: everything that matters needs to be broken down by tenant.
The metrics you need per tenant:
- Query count and latency — which tenants are generating the most load?
- Error rates — are timeouts hitting specific tenants?
- Storage consumption — which tenants are growing fastest?
- Connection usage — is anyone holding a disproportionate share of the pool?
Add tenant_id as a label to every application metric you emit. Latency histograms, error counters, cache hit rates — all of them become dramatically more useful when you can filter to a specific tenant who is reporting problems, rather than seeing aggregate averages that hide their experience entirely.
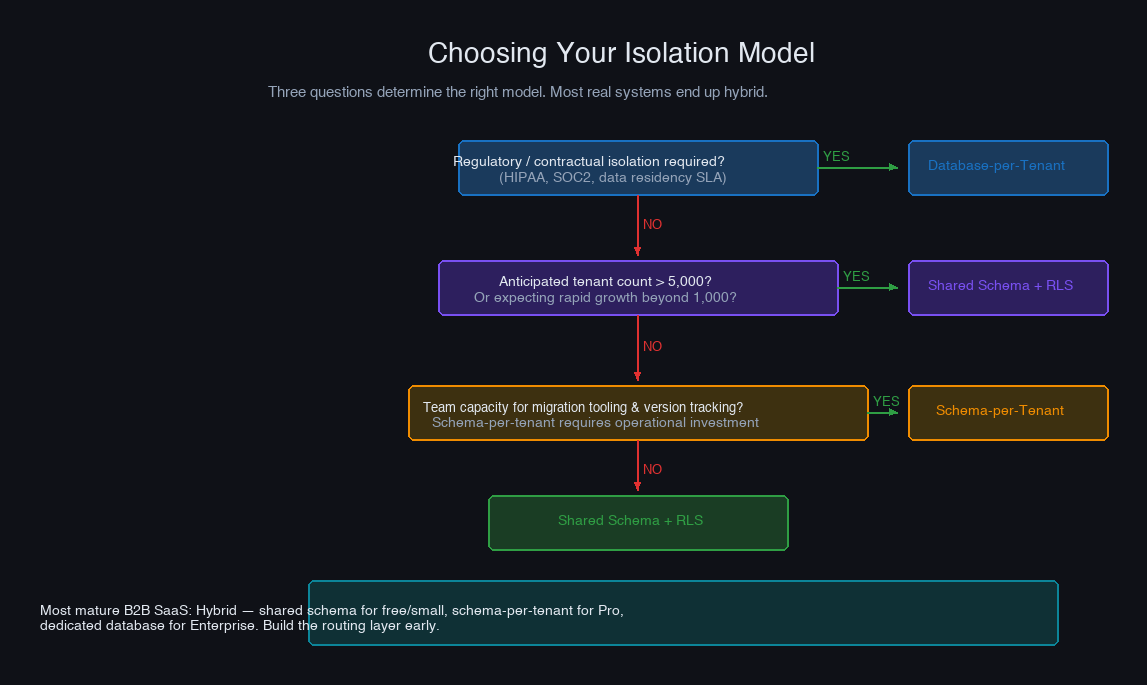
Choosing Your Model
Before deciding, answer three questions:
Do you have regulatory or contractual isolation requirements? If yes, database-per-tenant for those customers. The cost is real, but non-compliance is worse.
What is your anticipated tenant count? Under 500: any model works. 500–5,000: schema-per-tenant is viable but migration tooling becomes a real investment. Above 5,000: shared schema is the only model that scales operationally.
What is your team's operational capacity? Schema-per-tenant requires migration runners, version tracking, and careful deployment coordination. Database-per-tenant requires infrastructure automation and connection management at scale. If your team is small, shared schema with RLS offers the best operational story even if the isolation ceiling is lower.
The Decisions That Actually Matter
The isolation model is the first decision, but the implementation details are where multi-tenancy actually breaks in production.
Always lead index columns with tenant_id in shared schema. A query that doesn't hit the tenant prefix scans the full table. This is the difference between a 1ms lookup and a 2s full scan, and it degrades with every new customer you onboard.
Use RLS even if your application code already filters by tenant. Application-level filtering is correct until there's a refactor, a new developer, a raw query in an admin tool, or a library that generates queries you didn't write. RLS is the enforcement layer that makes correctness unconditional.
Test the migration runner before you need it at scale. Running a migration across 50 schemas in staging and 2,000 in production are very different operations. Measure the actual time, account for failures, and have a rollback plan before you need one at 2am.
Set statement timeouts by tier, not globally. A global 10-second timeout will hit legitimate enterprise queries. A 3-second timeout for free-tier users will feel generous once you've seen what they try to run. Differentiate from day one — retrofitting it is more work than building it in.
Build the tier upgrade migration path early. Moving a tenant from shared schema to a dedicated database sounds straightforward until you're mid-execution with an anxious customer on the phone. The tooling for this is worth building before you have an urgent deal depending on it.
Multi-tenancy done well is mostly invisible — customers get their data, fast and reliably, with no awareness of who they share infrastructure with. Multi-tenancy done poorly surfaces in support tickets about slowness, incidents about data visibility, and engineering weeks spent untangling migration debt. The architecture choices made in the first year have a long half-life.
More in System Design
Backpressure Patterns in Distributed Systems
How to detect overload before it cascades, shed load gracefully, and propagate backpressure signals upstream through service chains — from bounded queues to Kafka consumers to gRPC streams.
Write-Ahead Logs: The Pattern Behind Every Database
How WALs make databases durable, power crash recovery and replication, and why the same pattern still underlies modern systems from PostgreSQL to Kafka to Raft.