Write-Ahead Logs: The Pattern Behind Every Database
How WALs make databases durable, power crash recovery and replication, and why the same pattern still underlies modern systems from PostgreSQL to Kafka to Raft.

Akhil Sharma
April 8, 2026
Write-Ahead Logs: The Pattern Behind Every Database
Your application calls db.commit(). The database returns OK. You trust that the data is safe.
Then the server loses power.
When the database restarts, it reads a log file and replays the last few seconds of operations. Your committed transaction is intact. The transaction that was mid-flight at the moment of the crash is gone — cleanly rolled back, as if it never started. The database's recovery was not luck. It was the write-ahead log: a file that captured every intended change before any data page was touched, making "what happened right before the crash" a question the database can answer with precision.
WAL is the durability mechanism behind every production database — PostgreSQL, MySQL, SQLite, RocksDB, CockroachDB. It's also one of the oldest patterns in systems software, dating back to IBM's System R in the 1970s. The reason it hasn't been replaced is that nothing else solves the crash recovery problem with the same combination of correctness and performance.
The Problem WAL Solves
Without a WAL, a database that commits a transaction must immediately write the updated data pages to disk. This runs into two problems simultaneously.
The performance problem. A single transaction might modify dozens of pages scattered across the data files. Writing those pages immediately means random I/O — each write jumps to a different disk location. Random I/O is orders of magnitude more expensive than sequential I/O, and on a write-heavy system this becomes the bottleneck almost instantly.
The atomicity problem. Writing multiple pages is not atomic at the hardware level. A power failure midway through leaves the database with some pages from before the commit and some from after. The database is now in a state that should never have existed — partially committed, internally inconsistent, and potentially unrecoverable.
WAL resolves both at once. Instead of modifying data pages immediately, the database writes a log record describing the change — sequentially, to a dedicated log file — and calls fsync to ensure it's on durable storage. Then it acknowledges the commit to the client. The actual data pages are updated lazily in memory, and eventually flushed to disk at checkpoint time.
Sequential writes are fast. Data page flushes are deferred and amortized. And if power fails between the fsync and the checkpoint, the log contains a complete record of every committed change — recovery replays it.
How WAL Works: Write the Log First
The write cycle has a strict ordering requirement, known as the Write-Ahead Rule:
A log record must be persisted to durable storage before the corresponding data page can be written to disk.
This is not a suggestion — it's the invariant that makes recovery possible. If a data page makes it to disk without its log record, recovery has no way to know what that page was supposed to contain after the crash.
There's a second rule for transaction commits:
All log records for a transaction must be flushed to durable storage before the transaction is acknowledged as committed.
Together, these two rules mean: durability is established at the moment the WAL is fsynced, not at the moment data pages are written.

The buffer pool (the in-memory cache of data pages) operates independently of the WAL. Pages can stay in memory for minutes, being read and written many times, while their corresponding WAL records pile up in the log. At checkpoint time, the database forces dirty pages to disk and records the checkpoint LSN — after which the WAL segments before that point can be recycled.
The Anatomy of a WAL Record
Every change to the database is described by one or more WAL records. Each record contains:
The Log Sequence Number (LSN) is the key field. In PostgreSQL it's a byte offset into the WAL stream — a 64-bit integer that only ever increases. Every buffer page tracks the LSN of the most recent WAL record that modified it. Recovery uses LSNs to determine which pages are already up-to-date and which need replaying.
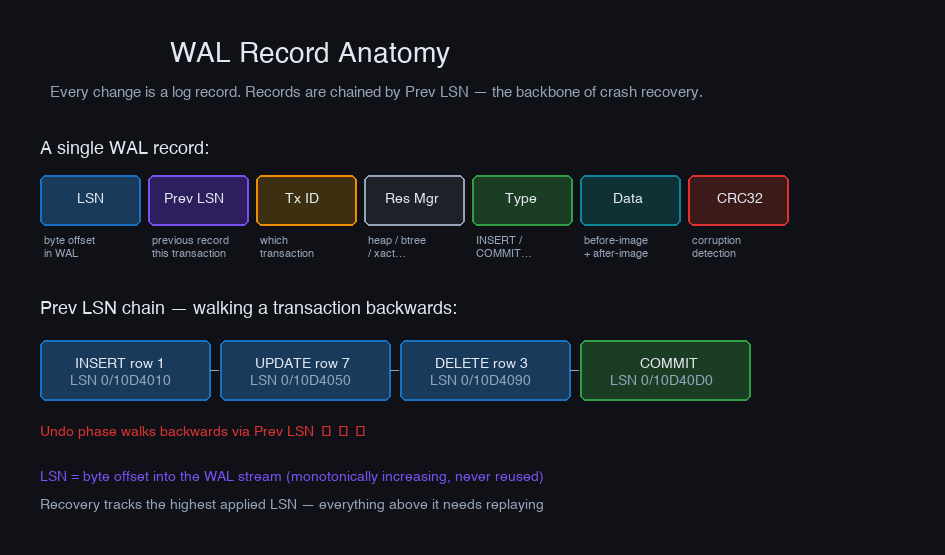
The Prev LSN field chains records within a transaction: each record points to the previous one from the same transaction. Recovery's undo phase uses this backward chain to walk a transaction's history in reverse and roll it back.
PostgreSQL exposes WAL records through pg_waldump:
You can see the prev LSN linking the INSERT record (0/10D4050) back to the record before it (0/10D4010), and the COMMIT record pointing to the final INSERT. To roll back this transaction, walk the chain from the COMMIT backwards through all its records and apply the before-images.
Crash Recovery: The ARIES Algorithm
When a database restarts after a crash, it reads the WAL and reconstructs what was in-flight at the moment of failure. The algorithm used by PostgreSQL, SQL Server, DB2, and most other databases is ARIES (Algorithm for Recovery and Isolation Exploiting Semantics), published by Mohan et al. at IBM in 1992.
Recovery happens in three sequential phases:
Phase 1 — Analysis. Scan forward from the last checkpoint record to the end of the WAL. Build two data structures:
- Transaction table — which transactions were active at crash time and what their last LSN was
- Dirty page table — which buffer pages had unflushed modifications, and the earliest LSN that dirtied each one
This phase answers: What was the state of the world when the crash happened?
Phase 2 — Redo. Replay all log records forward from the earliest LSN in the dirty page table (the redo LSN). This brings data pages back to exactly the state they were in at the moment of the crash — including changes from uncommitted transactions.
The counterintuitive part: redo applies uncommitted work too. The goal is to precisely recreate the crash state. Committed data that never made it to disk gets replayed. In-flight data that happened to be in the buffer pool also gets replayed — temporarily.
Phase 3 — Undo. Walk backwards through the log, rolling back every transaction that was active at crash time — the ones with no COMMIT record. Each operation is undone using the before-image stored in the WAL record.
After undo completes, the database reaches a consistent state: every committed transaction is present, every uncommitted transaction is gone.
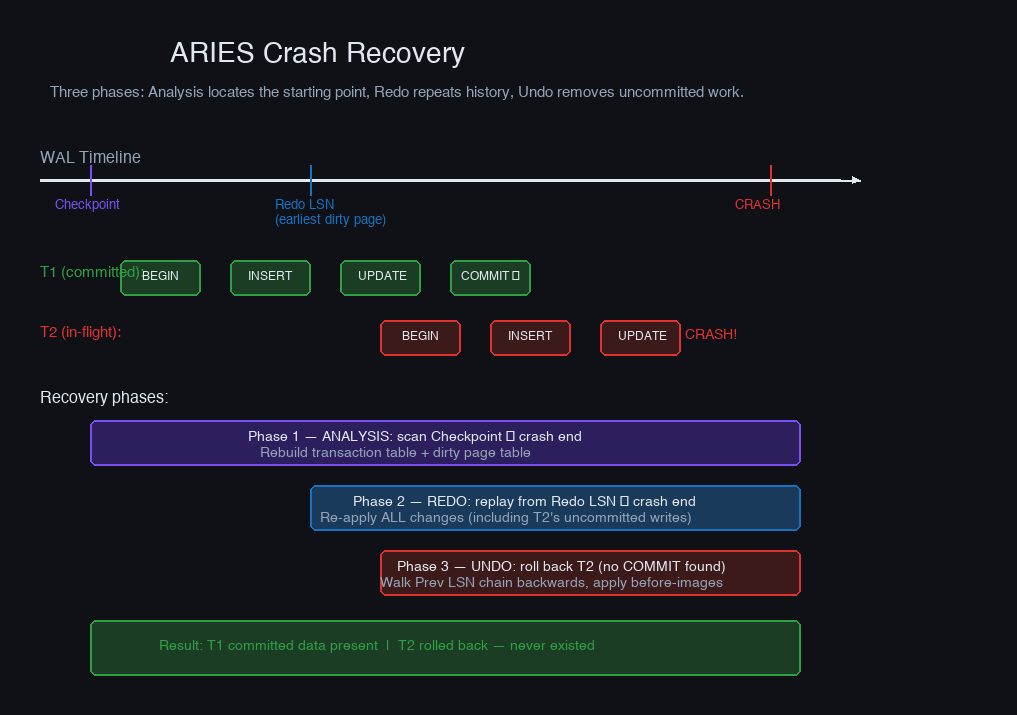
One ARIES property worth internalizing: redo is repeating history, not just applying committed work. This makes redo idempotent — if the database crashes a second time during recovery, the next recovery run applies the same log records and reaches the same result. LSNs make this safe: each log record knows which page it modifies, and the page header tracks which LSN was last applied to it. If the page is already up-to-date, the redo is skipped.
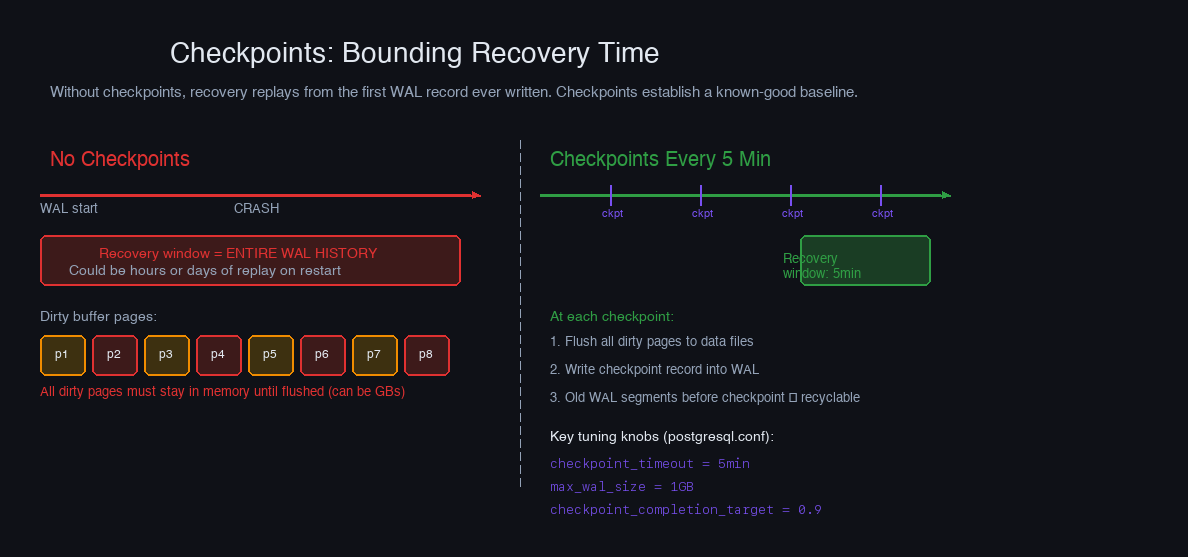
Checkpoints: Bounding Recovery Time
Without checkpoints, recovery must replay the WAL from the very first record ever written — potentially years of history. Checkpoints prevent this by periodically establishing a known-good baseline.
A checkpoint does two things:
- Forces all dirty buffer pages to disk (pages modified by log records up to this point)
- Writes a checkpoint record into the WAL containing the current LSN and the state of the dirty page table
After a checkpoint, recovery only replays from the checkpoint LSN. Everything before it is already reflected on disk.
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts May 10 — 20 seats.
Reserve your spot →PostgreSQL's checkpoint behavior is tuned with three parameters:
checkpoint_completion_target is the most important tuning parameter for I/O smoothness. Without it, checkpoints write all dirty pages as fast as possible — a burst of I/O that shows up as latency spikes during normal query execution. Setting it to 0.9 tells PostgreSQL to pace the checkpoint I/O so it completes in 4.5 minutes of a 5-minute window, smoothing the curve.
The trade-off: less frequent checkpoints mean more WAL segments accumulate between cleanups, increasing disk usage and the worst-case recovery window. On a write-heavy system with checkpoint_timeout = 30min, it's common to see gigabytes of WAL on disk at any moment. Budget storage accordingly and monitor pg_stat_bgwriter to see how often checkpoints are occurring and whether they're triggered by timeout or by max_wal_size.
WAL-Based Replication
Because the WAL is a complete record of every change, it can be shipped to other servers to keep them synchronized. This is the entire foundation of database replication.
PostgreSQL supports two delivery models:
Log shipping. The primary writes completed WAL segment files (16MB each by default) and copies them to standbys via archive_command. Standbys apply segments as they arrive. Simple and reliable, but the standby can lag by up to one full segment — 16MB of undelivered WAL — at any moment.
Streaming replication. The primary streams WAL records to standbys in real time as they're generated, without waiting for segment completion. Standbys typically lag by milliseconds rather than the time to fill a 16MB file. This is what primary_conninfo configures on the standby.

The LSN columns let you trace exactly where in the WAL each standby sits. lag_bytes = sent_lsn − replay_lsn gives you the replication lag in bytes. If your system generates 50 MB/s of WAL and lag_bytes is 500 MB, that standby is running ~10 seconds behind.
Physical vs. logical replication is a separate axis. Physical replication ships raw WAL bytes — fast, zero schema knowledge required, but both sides must be the same PostgreSQL major version and architecture. Logical replication decodes WAL records into row-level changes, making it version-independent and filterable to specific tables. The decoding step costs CPU but enables scenarios physical replication cannot: upgrading major versions with near-zero downtime, replicating selected tables to read replicas, or streaming to non-PostgreSQL systems like Kafka.
Group Commit: Amortizing the fsync Cost
Every COMMIT must fsync the WAL to durable storage before the client gets an acknowledgment. An fsync takes 1–10 ms on SSDs. At 500 transactions/second, that's 500 fsyncs/second — each waiting on disk, serialized. Throughput caps out fast.
Group commit breaks the serialization. When multiple transactions are all waiting to commit, one fsync covers all of them:
PostgreSQL's WAL writer runs as a background process and periodically batches pending WAL records into a single fsync. Under load with many concurrent clients, one fsync can cover dozens of transactions. This is why PostgreSQL throughput scales with concurrency even under synchronous_commit = on.
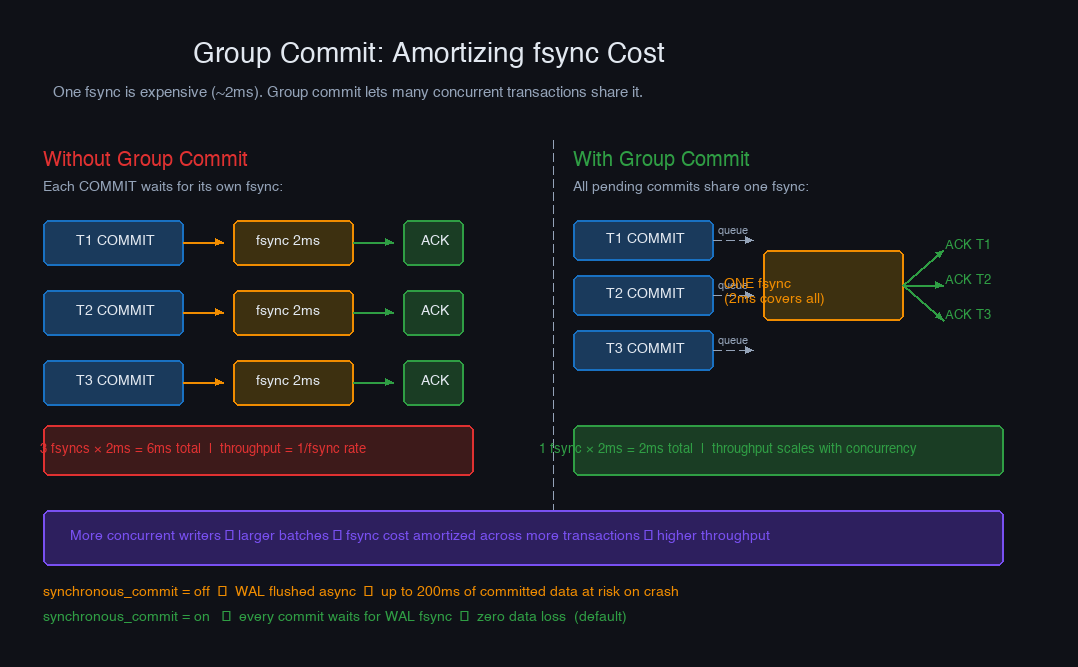
The durability dial for this trade-off is synchronous_commit:
synchronous_commit = off is often the right choice for non-critical workloads. Session state, event counters, analytics writes, and caches can tolerate the theoretical 200ms window of committed-but-not-durable transactions. Financial transactions and anything you'd hate to explain to a customer cannot.
Building Your Own WAL
The WAL pattern shows up wherever you need durable state outside a database. Here's the minimal structure:
The os.fsync() call is the essence of the WAL. Without it, the OS may buffer your writes in memory, report success, and lose them on power failure. flush() drains Python's buffer to the OS; fsync() forces the OS to confirm the hardware has it.
Using this WAL for crash recovery in a simple key-value store:
What a production WAL adds on top: log rotation (splitting into fixed-size segments so old ones can be deleted), log recycling (PostgreSQL pre-allocates and reuses segment files to avoid the cost of file creation), page-level checksums (detecting torn writes), and full-page writes (writing the entire page image on the first modification after a checkpoint, protecting against partial page corruption on crash).
WAL in the Wild
The same pattern appears throughout modern infrastructure, often without being called a WAL:
Kafka's log. Kafka partitions are append-only log files. Producers append records; consumers track their position by offset — the Kafka equivalent of an LSN. Durability is controlled by acks and min.insync.replicas, which mirror synchronous_commit's trade-offs exactly. Kafka isn't a database, but its core is a distributed WAL.
Raft's log. The Raft consensus algorithm centers on a replicated log. The leader appends entries, followers replicate them, and an entry is "committed" once a majority has written it durably. The distributed consistency problem Raft solves is, at its core, the problem of agreeing on a shared WAL.
SQLite. SQLite's WAL mode writes after-images of modified pages to a WAL file rather than immediately overwriting the database file. Readers see a consistent snapshot; the WAL is periodically checkpointed back into the main file. The default journal mode uses a different approach (before-images in a rollback journal) but follows the same write-before-modify principle.
RocksDB. RocksDB uses a WAL to log writes before applying them to the in-memory MemTable. When the MemTable fills, it flushes to SST files on disk — the same deferred flush pattern as PostgreSQL's buffer pool. The WAL lets RocksDB acknowledge writes without immediately touching SST files, which are immutable and expensive to modify.
What Kafka, Raft, SQLite, and RocksDB have in common isn't a shared codebase or lineage — they independently arrived at the same answer to the same problem. If you need to survive a crash, write the evidence before you act on it.
The Decisions That Actually Matter
After everything above, the practical choices reduce to a short list.
synchronous_commit — the default is on, which is correct for anything you'd be uncomfortable explaining to a user. Turn it to off per-transaction or per-session for workloads that genuinely don't need durability: ephemeral session state, analytics counters, non-critical event streams. Never flip it globally unless you've thought through exactly what you're willing to lose.
checkpoint_completion_target — leave it at 0.9. The old default of 0.5 caused visible I/O spikes mid-checkpoint on every busy PostgreSQL server in the world. 0.9 spreads the dirty-page writes across 90% of the checkpoint interval and makes checkpoint I/O nearly invisible in production metrics. There's rarely a reason to go lower.
max_wal_size — the default of 1 GB is conservative. On a write-heavy system, WAL size will trigger checkpoints long before checkpoint_timeout fires. Raising it to 2–4 GB on fast NVMe storage reduces checkpoint frequency, smooths I/O, and modestly improves write throughput — at the cost of a slightly longer worst-case recovery window. Know which side of that trade-off your availability requirements sit on.
Replication mode — streaming replication to your primary standby, always. Log shipping for cold standbys or cross-region copies where segment-level lag is acceptable. If your standby needs to survive a primary crash with zero data loss, set synchronous_commit = remote_write. If it needs to be instantly readable after every commit, use remote_apply and accept the added latency on the write path.
Full-page writes — leave them on. Yes, they increase WAL volume on write-heavy workloads (the first modification to a page after a checkpoint includes the full 8 KB page image). Turning them off is only safe if your storage layer guarantees atomic 8 KB page writes — most production storage doesn't, and the failure mode if you're wrong is silent corruption.
What to monitor — pg_stat_bgwriter tells you how often checkpoints are firing and whether they're hitting max_wal_size before checkpoint_timeout (a sign your WAL size is too small). pg_stat_replication gives you per-standby LSN positions and lag. WAL write rate in bytes per second tells you how hard your write path is working. When something goes wrong, pg_waldump lets you read the actual log records.
Most WAL problems in production are tuning problems, not correctness problems. The durability guarantees hold. What tends to break is checkpoint I/O eating into query latency, or replication lag growing under write spikes, or disk space filling up because WAL segments aren't being recycled fast enough. All of these show up in metrics before they cause outages — if you're watching.
The WAL doesn't ask much operationally. In exchange, it gives you crash recovery, replication, and point-in-time restore essentially for free. That's a good trade.
More in System Design
Backpressure Patterns in Distributed Systems
How to detect overload before it cascades, shed load gracefully, and propagate backpressure signals upstream through service chains — from bounded queues to Kafka consumers to gRPC streams.
Designing for Multi-Tenancy at Scale
The real trade-offs between database-per-tenant, schema-per-tenant, and shared schema isolation models — covering noisy neighbor mitigation, row-level security, tenant-aware connection pooling, and the hybrid model most teams eventually land on.