Backpressure Patterns in Distributed Systems
How to detect overload before it cascades, shed load gracefully, and propagate backpressure signals upstream through service chains — from bounded queues to Kafka consumers to gRPC streams.

Akhil Sharma
April 10, 2026
Backpressure Patterns in Distributed Systems
The alert fires at 2:47am. API servers are at 100% CPU, the database connection pool is exhausted, and the message queue has 4 million unprocessed items. Memory is climbing. Three minutes later, pods start OOMKilling. The incident review will call it a "traffic spike."
It wasn't a traffic spike. It was a backpressure failure.
The system accepted work faster than it could process it. Queues had no bounds, so they grew until memory ran out. Nothing signaled the upstream services to slow down. Nothing shed work when the load exceeded capacity. The system had an implicit assumption baked in everywhere: that requests arrive slower than they can be handled. The moment that assumption broke, the whole thing fell over.
Backpressure is the mechanism that prevents this. It's the set of techniques that ensure a system never permanently accepts work faster than it can process it — and when it momentarily does, it controls the consequence gracefully instead of letting it cascade.
What Backpressure Actually Is
In fluid dynamics, backpressure is the literal resistance to flow in a pipe — the pressure that pushes back against the direction of movement when the downstream end is restricted. In software, the concept is the same: a downstream component that cannot keep up with incoming work needs a way to signal upstream producers to slow down, or the buffer between them will fill until something breaks.
The core problem is the producer-consumer speed mismatch:
Any system that doesn't handle this mismatch will eventually accumulate unbounded state. It's not a question of whether it fails — it's a question of when and how badly.
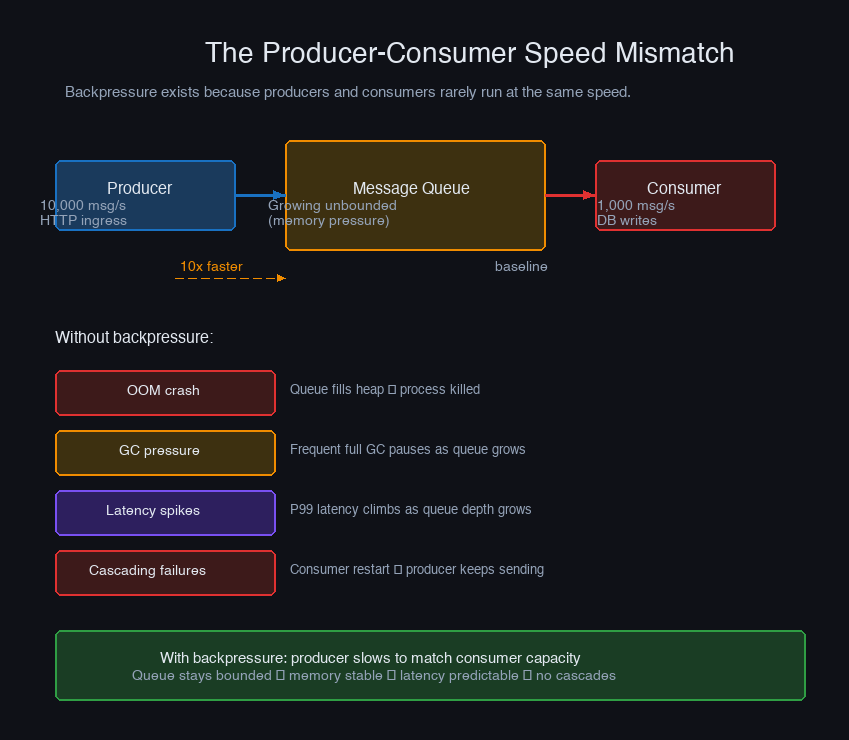
Backpressure isn't one thing. It's a family of techniques that all address the same underlying problem from different angles: detecting overload, controlling what happens to excess work, and propagating the signal upstream so producers adjust their rate. A well-designed system combines several of them.
The Three Ways Systems Handle Overload
When a consumer cannot keep up with its producer, there are exactly three possible responses — everything else is a variation on one of these:
Absorb without limit. Accept all incoming work, buffer what can't be processed immediately, and trust that the consumer will eventually catch up. This is the default behavior of unbounded queues and in-memory buffers. It works when overload is transient and short-lived. When it isn't — when load is sustained or the burst is large enough — the buffer fills until the process runs out of memory and crashes. The failure mode is catastrophic and often takes unrelated parts of the system down with it.
Drop without signal. When the buffer is full, discard incoming work. Simple, fast, and prevents OOM crashes. The problem is that dropping silently is often worse than not dropping at all — the producer has no idea its work was lost, the downstream system has gaps it doesn't know about, and debugging the consequences weeks later is unpleasant. Intentional dropping with proper signaling (metrics, error responses, dead letter queues) is a different story.
Propagate the signal upstream. Tell producers to slow down. This is true backpressure: the consumer's overload state is communicated back to the source, which adjusts its production rate. This is the right approach when you control the full call chain and the producer can actually respond to the signal. It prevents both the OOM crash and the silent data loss.
Most real systems use all three strategies simultaneously: bounded buffers (absorb up to a limit), intentional shedding with proper signaling (drop with acknowledgment), and upstream propagation for components that can receive the signal.
Detecting Overload Before It Becomes a Crisis
You cannot respond to overload you haven't detected. The signals that matter — in roughly the order you should instrument them:
Queue depth and growth rate are the earliest warning. A queue that's growing is a system that's consuming slower than it's producing. The absolute depth matters less than the trend: a queue at 90% capacity and stable is fine; a queue at 30% capacity and growing at 5% per second is a crisis in 14 seconds.
Processing latency percentiles — p99 and p999 in particular — are the second signal. When consumers are overloaded, individual task processing times increase as tasks wait behind other tasks. A latency spike at the p99 without a corresponding spike at the p50 means a subset of work is getting stuck. A spike at both means systemic overload.
Active worker utilization tells you how close you are to processing capacity. If you have 50 workers and 49 are active, you're one burst away from saturation. If all 50 are active and the queue is growing, you've crossed into overload territory.
Error rate is a lagging indicator but useful as confirmation. When your database connection pool exhausts, when timeouts start firing, when downstream services start returning 503s — these are symptoms of overload that's already happening, not approaching.
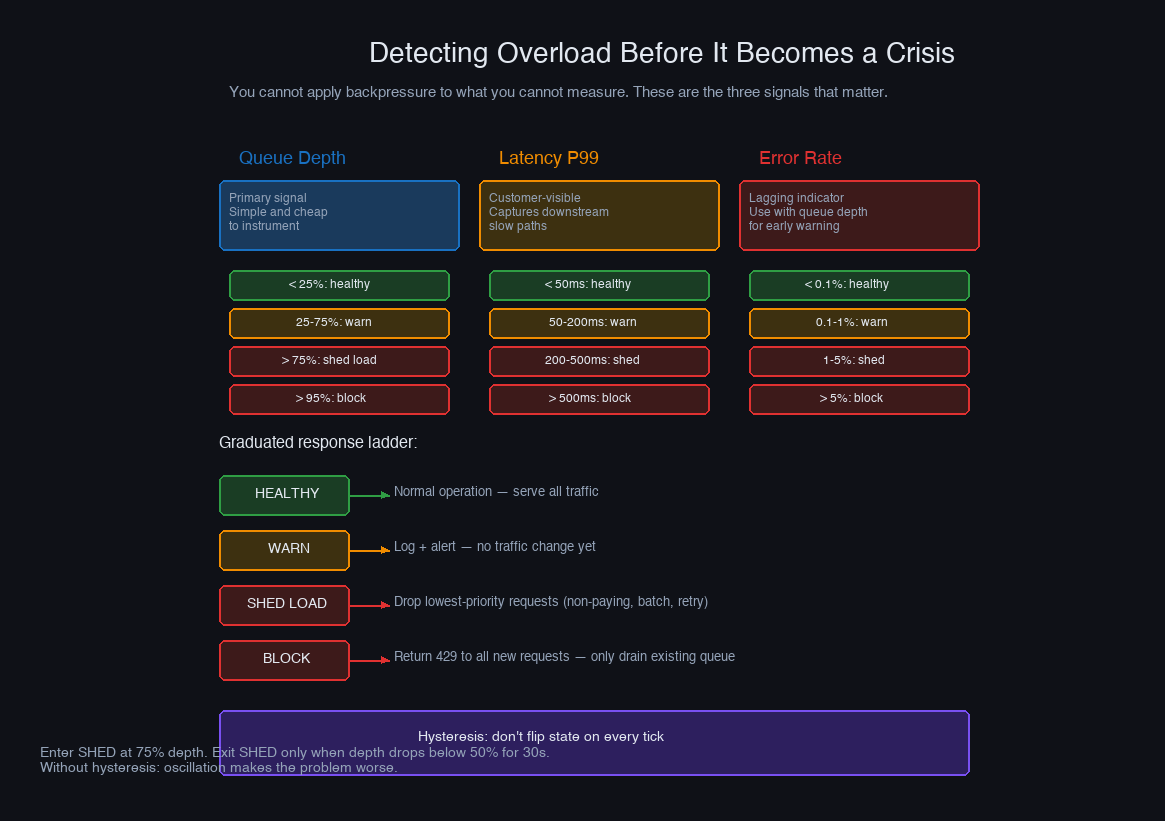
Instrument these signals before you think you need them. Overload that shows up as OOM crashes without prior warning metrics means you had no signal to act on. The goal is to see the watermark rising in time to do something about it.
Bounded Queues: The Foundation
An unbounded queue is a silent promise to process all work eventually — a promise the system cannot keep under sustained overload. A bounded queue makes the constraint explicit and forces a decision at the point where work cannot be accepted.
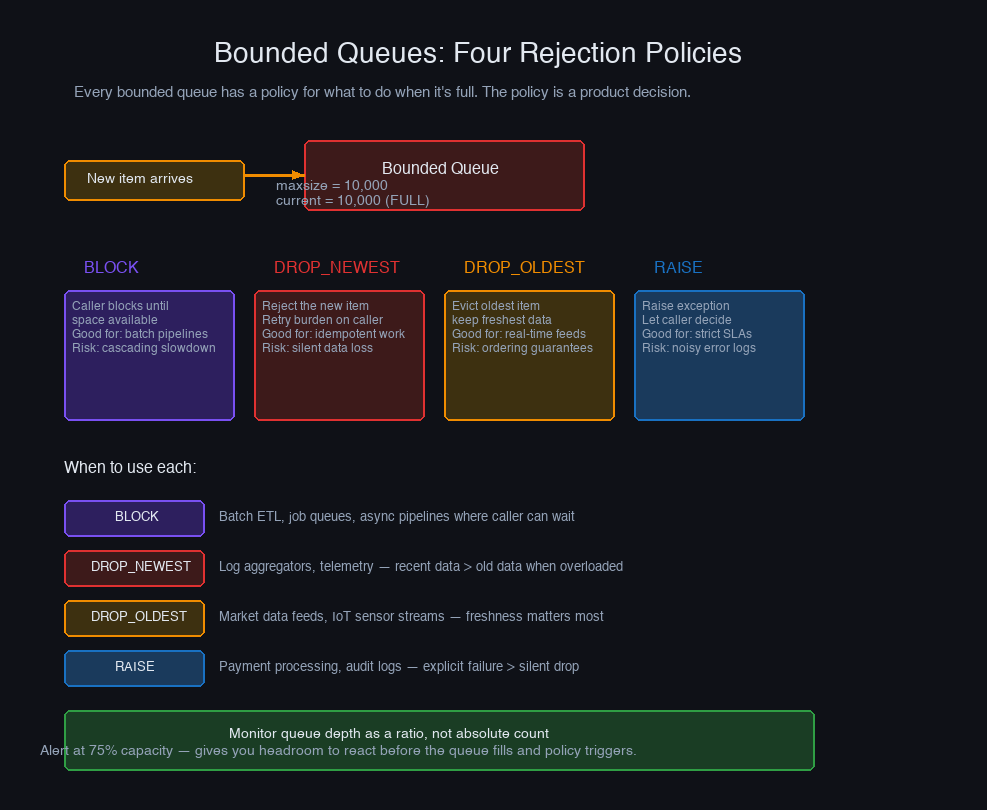
The choice of policy depends on the semantics of the work. For user-facing request queues, DROP_NEWEST is usually correct: the incoming request is the newest and most likely to already have a client timeout looming. For time-series event pipelines where recent data is more valuable than old data, DROP_OLDEST preserves freshness. For safety-critical work that must never be dropped, BLOCK forces the producer to wait.
The BLOCK policy is true backpressure: the consumer's full queue directly slows the producer by blocking it. The producer doesn't need any special knowledge of the consumer's state — the block signal is automatic. This only works when the producer can safely block without causing a deadlock, which rules out some async frameworks.
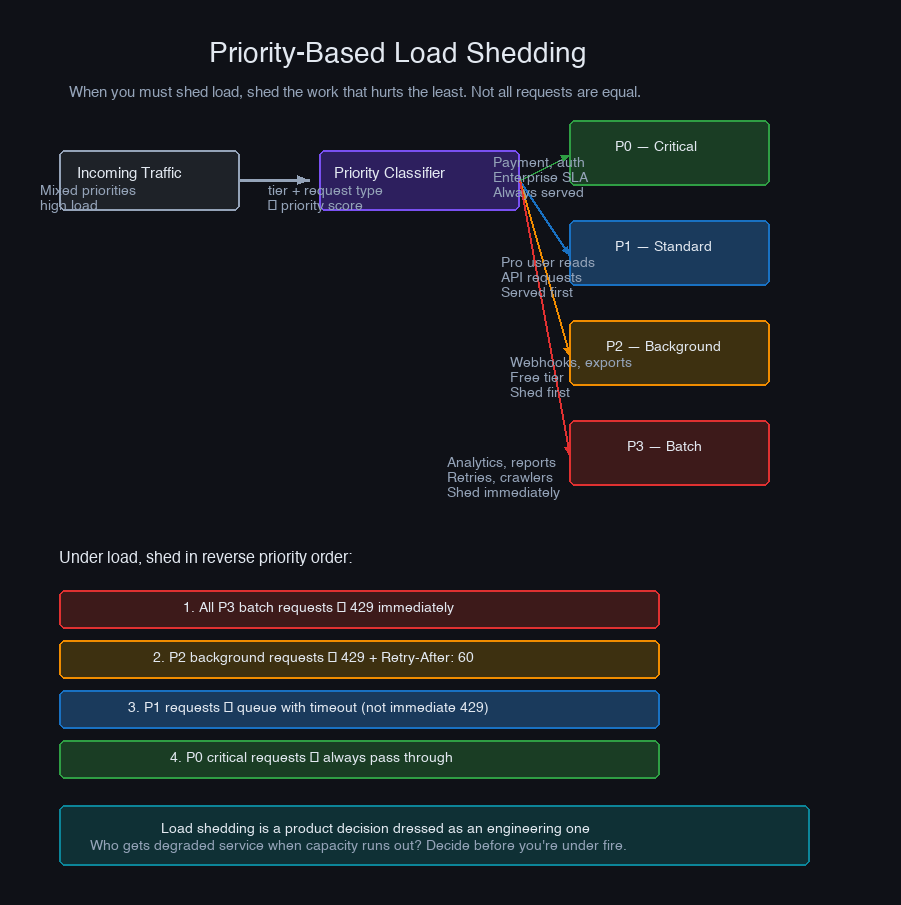
Load Shedding: Choosing What to Drop
When you must shed load — when the queue is full and you cannot block the producer — the question is not whether to drop work, but which work to drop. Random dropping is fair but wasteful: you're equally likely to drop a health check as a payment transaction.
Priority-based load shedding keeps critical work flowing when the system is saturated:
Advanced System Design Cohort
We build this end-to-end in the cohort.
Live sessions, real systems, your questions answered in real time. Next cohort starts May 10 — 20 seats.
Reserve your spot →@property def depth(self): return len(self.heap)
Under normal load, everything gets processed. Under saturation, BATCH jobs get dropped first, then LOW priority, and so on. CRITICAL work — the things that have to succeed for the system to function — is the last to be shed, and only in the most extreme scenarios.
There is a failure mode to watch for: priority starvation. If CRITICAL work continually floods the queue, LOW and BATCH tasks may never run. Add age-based priority boosting — a task that has waited more than N seconds gets its priority bumped — to prevent any tier from starving indefinitely.
Pull-Based Flow Control: Letting Consumers Lead
Push-based systems put the producer in control: it sends work when it has it. The consumer takes what arrives and does its best. When the consumer falls behind, the queue fills.
Pull-based systems invert this: consumers request work when they're ready to process it. The producer sends nothing until asked. The consumer's processing capacity is the natural rate limiter — it can only request as fast as it finishes.
The semaphore is the backpressure mechanism. worker_count concurrent tasks in flight means the source can never have more than worker_count × batch_size unacknowledged items outstanding. The producer knows exactly how much in-flight work exists at any time.

Reactive Streams (the Java specification behind Project Reactor and RxJava) formalizes this pattern with the concept of demand: a subscriber explicitly signals how many items it can handle with request(n). The publisher sends at most N items before waiting for another request(n) signal. No items are sent until demand is expressed. This is the strictest form of pull-based backpressure, and it makes the flow contract explicit in the type system.
Propagating Backpressure Upstream
Within a single process, bounded queues and semaphores propagate backpressure mechanically — a full queue blocks the producer, the producer blocks its caller, and the signal travels up the call chain automatically. Across service boundaries, you have to do this work explicitly.
Consider a three-service pipeline: Service A → Service B → Service C. Service C is slow. Service B's queue fills. If Service B just drops requests silently, Service A doesn't know to slow down and continues sending work that will be dropped. The solution is for Service B to propagate the signal back to Service A in a form it can act on.
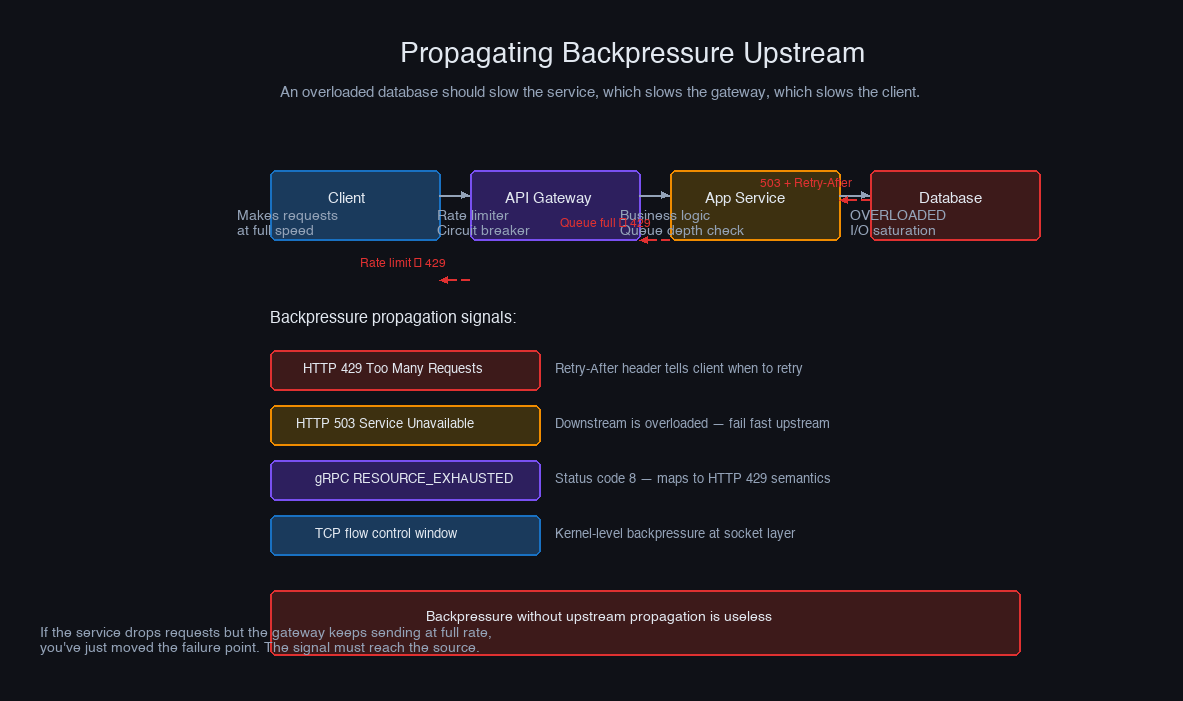
The server side of this pattern:
The critical property of this pattern: the 429 response includes a Retry-After header. A client that respects this header backs off for exactly the right duration — not too short (hammering a recovering server), not too long (needlessly delaying legitimate work). Clients that don't respect it need a circuit breaker on the server side.
Backpressure Over gRPC and HTTP/2
gRPC inherits HTTP/2's flow control, which provides backpressure at the protocol level. Every HTTP/2 connection and stream has a flow control window measured in bytes. When the receiver's window is exhausted, the sender is blocked at the transport layer — automatically, without any application-level code.
For server-streaming RPCs, this means a slow client automatically slows down the server:
For bidirectional streaming, the flow control window applies in both directions. A client that is slow to read responses naturally throttles the server's send rate. This is the most transparent form of backpressure — the protocol enforces it without any application awareness.
The configurable parameters to tune in production:
Larger windows allow more in-flight data before blocking, which improves throughput on high-latency networks but increases the buffering before backpressure kicks in. Tune these based on your network latency × bandwidth product and the latency tolerance for overload detection.
Backpressure in Kafka Consumers
Kafka's consumer model is naturally pull-based: consumers poll for batches of records at their own pace. The producer (the Kafka broker) never pushes records — the consumer fetches when it's ready. Consumer lag — the number of unprocessed records between the consumer's current offset and the end of the partition — is the queue depth metric.
The settings that control consumer-side backpressure:

The common failure mode is violating max.poll.interval.ms. A consumer that processes records too slowly between poll calls exceeds the interval, Kafka treats it as dead, triggers a group rebalance, and reassigns its partitions — which causes the other consumers to pause processing during the rebalance. The fix is either to reduce max.poll.records (smaller batches, faster processing), increase max.poll.interval.ms (give more time), or move slow processing off the poll loop into a separate async worker:
Consumer lag monitoring belongs in your alerting stack, not just as an incident indicator. A consumer that's growing lag by 10,000 records/minute needs attention within minutes, not after it's 24 hours behind.
Circuit Breakers: Backpressure for Downstream Failures
A circuit breaker is a specific form of backpressure for a failure pattern that bounded queues don't handle: a downstream service that is slow or unreliable, causing requests to pile up waiting for responses that take 30 seconds to time out.
Without a circuit breaker, 100 concurrent requests to a slow downstream service each wait 30 seconds. Your thread pool is exhausted. New requests queue behind them. Your service is now effectively down, not because of high incoming load, but because you're waiting on a dependency that isn't going to respond quickly.
The circuit breaker breaks this cycle: after N consecutive failures, it stops sending requests to the failing service and returns errors immediately. Your thread pool clears. Your service recovers. The circuit breaker periodically probes the downstream service to check if it's recovered, and reopens when it does.
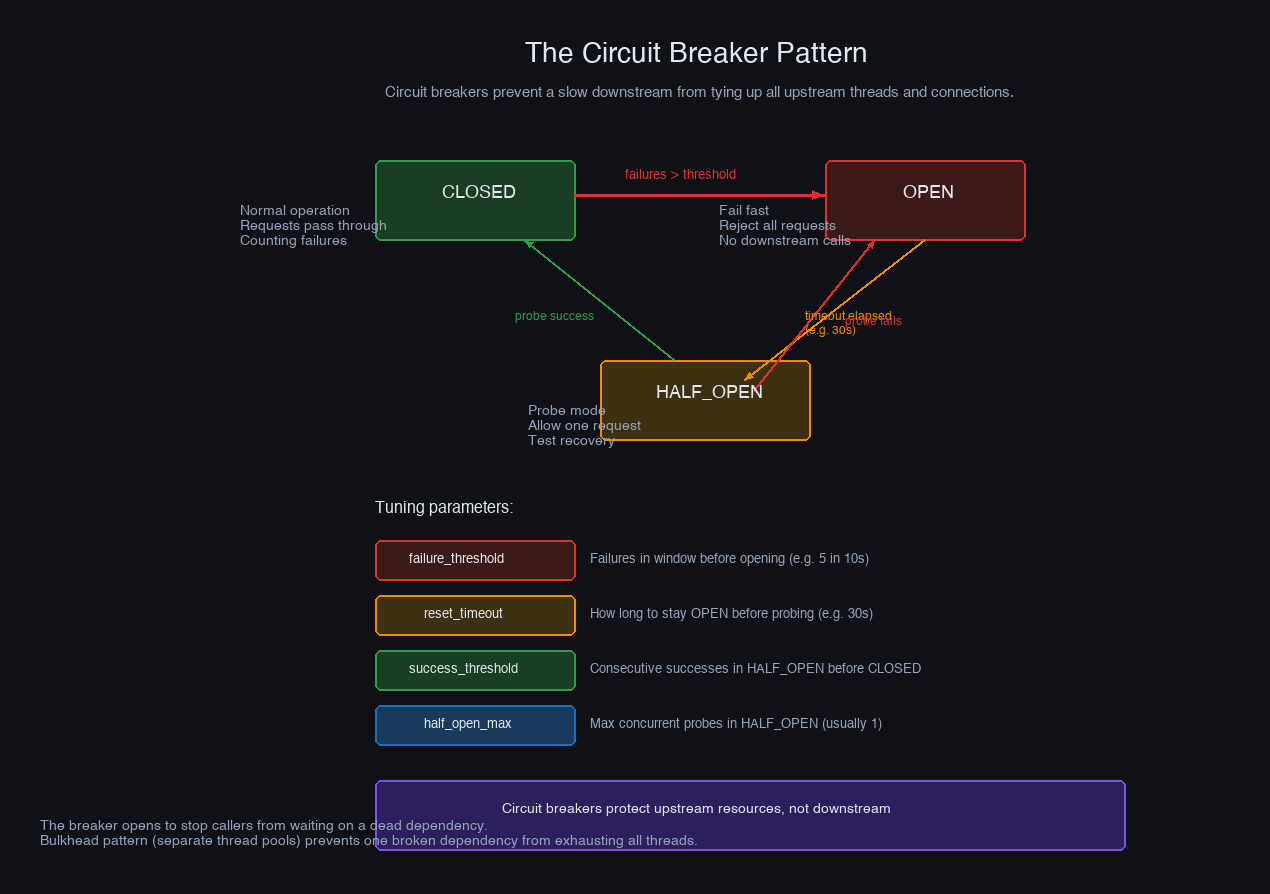
The circuit breaker decouples your system's health from the health of its dependencies. When a downstream service degrades, the circuit opens, fast-fails requests, and lets your thread pool drain. The dependency gets a recovery window without being hammered by retry storms. Your SLA is protected by a graceful degradation path rather than a cascade.
The Decisions That Actually Matter
Backpressure is a cross-cutting concern that needs to be designed in, not bolted on. Every component that accepts work needs an answer to: "What happens when I can't keep up?" The answer cannot be "nothing" — that's how you get 4am pages.
Start with bounded queues everywhere. Before adding sophisticated backpressure mechanisms, make every queue and buffer in your system bounded. An unbounded queue is a deferred OOM crash. Size the bounds based on your worst-case tolerable latency: queue_size = throughput × max_acceptable_latency_seconds. A 5,000 item queue at 1,000 items/second means at most 5 seconds of queued work — usually acceptable. A 5,000,000 item queue is a 5,000-second backlog, which is a catastrophe.
Separate your load shedding by criticality. Not all work is equal. Define priority tiers for your task types before you hit saturation, not during. The conversation "should we drop billing retries or user profile updates first?" is much easier before the incident than during it. Map your tiers to business impact, encode them in your queue configuration, and test that critical work survives simulated overload.
Make backpressure visible. Queue depth, consumer lag, 429 response rates, circuit breaker state, and worker utilization should all be in your primary dashboard. An overload that has no metrics is an overload that you'll only notice by its consequences. Set alerts on queue growth rate — not just queue depth — so you have warning time before you're in crisis.
Respect Retry-After headers from your dependencies. A 429 without a backoff is just a retry storm with extra steps. When your services emit 429s with Retry-After, ensure every client that calls you actually respects the header. Clients that ignore it turn your backpressure mechanism into a thundering herd generator.
Test overload conditions explicitly. The usual advice about testing the happy path applies doubly to backpressure: your shedding logic, your bounded queue behavior, and your circuit breakers will only work in production if they've been exercised before production. Add load tests that saturate the system past its intended capacity, verify that critical-priority work survives, and confirm that recovery is clean — no stuck queues, no cascading rejections — after load drops.
The goal is not a system that never gets overloaded. The goal is a system whose behavior under overload is well-defined, bounded, and recoverable. That's what separates a service that has occasional traffic spikes from one that has occasional outages.
More in System Design
Designing for Multi-Tenancy at Scale
The real trade-offs between database-per-tenant, schema-per-tenant, and shared schema isolation models — covering noisy neighbor mitigation, row-level security, tenant-aware connection pooling, and the hybrid model most teams eventually land on.
Write-Ahead Logs: The Pattern Behind Every Database
How WALs make databases durable, power crash recovery and replication, and why the same pattern still underlies modern systems from PostgreSQL to Kafka to Raft.