Byzantine Fault Tolerance

Byzantine Fault Tolerance (BFT): Trusting a System When Some Participants Lie
(CHALLENGE) You are running a high-value distributed service - think payments, asset custody, certificate issuance, or a shared configuration store for critical infrastructure. You already replicate data across nodes to survive crashes. But now you are told a scarier story:
"Some replicas might not just crash. They might lie, equivocate, send different answers to different clients, or actively try to break safety."
That is the Byzantine fault model.
This is an interactive deep dive into Byzantine Fault Tolerance (BFT): what it protects, what it costs, how protocols work in distributed environments, and how real systems use it.
We will build intuition using coffee-shop analogies, decision games, and progressive reveal exercises.
Section 1 - The Coffee Shop Ledger: Why Crashes Are Not the Whole Story
- Scenario / challenge
- Interactive question
- Explanation with analogy
- Real-world parallel
- Key insight box
Scenario
Imagine a chain of coffee shops that share a single "gift card balance ledger." Customers can top up and spend at any location. To avoid downtime, the chain replicates the ledger across multiple shops.
In a crash-fault world, a shop's ledger node might:
- go offline
- restart with stale state
- drop messages
But it will not maliciously change balances.
Now upgrade the story: a compromised shop terminal starts lying:
- It tells Alice her card has $50.
- It tells Bob the same card has $5.
- It tells the network it processed a top-up that never happened.
That is a Byzantine fault: arbitrary behavior.
Pause and think
If you replicate a ledger on 3 nodes, and 1 node lies, can you still trust the ledger?
- A) Yes, majority wins (2 vs 1)
- B) No, because the liar can confuse the honest nodes
- C) It depends on whether nodes can authenticate messages
Pause and think.
Progressive reveal - Answer
C is the best answer.
- If nodes cannot authenticate who said what, a liar can impersonate others and fabricate support.
- If nodes can authenticate (digital signatures / MACs), then with 3 nodes and 1 liar, many simple "majority vote" ideas can work for some tasks - but not for general state machine replication under asynchrony and adversarial scheduling.
BFT protocols are about general replicated state machines (RSM) where:
- every honest node executes the same ordered log of commands
- safety holds even if some nodes lie
- liveness holds under certain timing assumptions
Real-world parallel
- Certificate transparency / logs: you want append-only behavior even if some log servers misbehave.
- Blockchains / consortium ledgers: participants may be rational or malicious.
- Critical configuration: multi-party control of secrets or policy changes.
Key insight
Crash fault tolerance assumes "fail-stop." Byzantine fault tolerance assumes "fail-anything." The difference is not incremental - it changes the required assumptions, quorum sizes, and protocol machinery.
Challenge question: What is the minimum extra assumption you would want to add to make "majority vote" meaningful in a Byzantine setting?
Production insight: the minimum is usually authenticated identities (who said what) plus non-equivocation evidence (signatures over a canonical message). Without that, you cannot even define "a node lied" in a way other nodes can agree on.
Section 2 - What Exactly Is a Byzantine Fault?
Scenario
Your distributed system has 7 replicas. You are told "up to 2 may be Byzantine." What does that include?
Pause and think
Which behaviors count as Byzantine?
- A node crashes and stops responding.
- A node sends conflicting replies to different clients.
- A node selectively delays messages to cause timeouts.
- A node corrupts its local disk and serves random state.
- A node follows the protocol but tries to front-run transactions.
Pause and think.
Progressive reveal - Answer
(1)-(4) are Byzantine in the standard model.
(5) depends on your threat model:
- If the protocol allows the leader to choose ordering arbitrarily, then "front-running" is not a fault from the protocol's perspective; it's a fairness / MEV / incentive issue.
- Some BFT systems add fairness constraints (e.g., encrypted mempools, commit-reveal, ordering rules), but that's beyond basic safety/liveness.
Mental model
Think of Byzantine nodes as adversarial processes. They can:
- coordinate (collude)
- adapt based on observed messages
- send different messages to different recipients
- try to violate safety (agreement / consistency)
- try to violate liveness (stall progress)
Real-world parallel
A compromised service instance behind a load balancer can:
- return inconsistent API responses
- forge audit events
- selectively deny service
Key insight
BFT is about correctness under adversarial participants, not just unreliable infrastructure.
Challenge question: If you assume "nodes can lie," what must you assume about identities and message authenticity to even define "a node lied"?
Clarification: most BFT literature assumes authenticated channels (e.g., signatures or MACs) so recipients can attribute messages to a specific replica identity.
Section 3 - The Core BFT Problem: Replicated State Machine Under Adversary
Scenario
You want a replicated key-value store. Clients send commands like:
- PUT(x=1)
- GET(x)
Your goal: every honest replica applies commands in the same order.
Interactive question
What are the two classic properties you want?
- A) Safety and throughput
- B) Safety and liveness
- C) Liveness and latency
Pause and think.
Answer
B) Safety and liveness.
- Safety: nothing bad happens (e.g., two honest replicas decide different orders).
- Liveness: something good eventually happens (requests eventually commit).
In BFT, safety is usually required under all conditions (even network chaos), while liveness requires some synchrony assumption.
Mental model (restaurant analogy)
Imagine a restaurant with multiple kitchens (replicas) preparing the same orders.
- Safety = all kitchens prepare the same dish sequence for the table.
- Liveness = the table eventually gets served.
A Byzantine kitchen might:
- claim it cooked dish #5 but did not
- tell the waiter dish #5 is "soup" and tell another waiter it is "steak"
BFT protocols are the "order ticket verification process" that ensures honest kitchens stay consistent.
Key insight
BFT state machine replication is consensus plus defenses against equivocation and forgery.
Challenge question: Why is GET tricky in BFT if different replicas might be at different log positions?
Production insight: reads are where many "BFT KV store" designs fail audits. You must decide whether reads are:
- ordered through consensus (simple, slower), or
- served with proofs / quorum reads (faster, more complex).
Section 4 - Quorums and the Famous 3f + 1 Requirement
Scenario
You are designing a cluster. You want to tolerate up to f Byzantine replicas.
Pause and think
Which cluster size is typically required for classic BFT consensus (e.g., PBFT-style) under partial synchrony?
- A) n = 2f + 1
- B) n = 3f + 1
- C) n = 4f + 1
Pause and think.
Progressive reveal - Answer
B) n = 3f + 1 is the classic bound for deterministic BFT consensus in the common model (authenticated channels, partial synchrony).
Why 3f + 1? (intuitive quorum intersection)
You want quorums big enough that two quorums always overlap in at least one honest node.
In many BFT protocols, a "commit" requires 2f + 1 votes.
With n = 3f + 1:
- Honest nodes >= 2f + 1
- Any two sets of size 2f + 1 intersect in at least f + 1 nodes
- Since at most f are Byzantine, the intersection contains at least 1 honest node
That honest overlap is the "witness" preventing contradictory commits.
Matching exercise
Match the fault model to typical replica count requirement:
| Fault model | Typical requirement | Why |
|---|---|---|
| Crash faults | ___ | ___ |
| Byzantine faults | ___ | ___ |
Pause and think.
Answer reveal:
| Fault model | Typical requirement | Why |
|---|---|---|
| Crash faults | n = 2f + 1 | majority intersection ensures at least 1 correct node overlaps |
| Byzantine faults | n = 3f + 1 | need intersection with at least 1 correct node when liars can vote both ways |
Real-world parallel
In a delivery service, if up to f couriers might forge signatures and claim deliveries they did not make, you need more independent confirmations than in a world where couriers only sometimes fail to show up.
Key insight
The jump from 2f+1 to 3f+1 is the "price of lying." You need enough honest overlap to outvote equivocation.
Challenge question: If you have 10 replicas, what is the maximum f you can tolerate under the 3f+1 rule?
Answer: f = floor((n-1)/3) = floor(9/3) = 3.
CAP note: BFT does not escape CAP. Under a partition, you must choose:
- preserve safety (consistency) and potentially lose availability (halt), or
- preserve availability and risk safety (not acceptable for SMR).
Section 5 - The Adversary's Superpower: Equivocation
Scenario
A leader proposes value v. A Byzantine leader proposes v to half the nodes and v' to the other half.
Pause and think
Why is equivocation uniquely dangerous compared to crash faults?
- A) It breaks confidentiality
- B) It can cause honest nodes to "legitimately" support conflicting outcomes
- C) It only affects performance
Pause and think.
Answer
B.
In crash-fault consensus, a failed leader simply stops sending. Honest nodes do not receive contradictory proposals.
In Byzantine settings:
- honest nodes might each see a plausible story
- they might sign/vote based on what they saw
- the attacker stitches those signatures into conflicting "proofs"
Analogy: Two menus at the same restaurant
A malicious host hands out two different menus:
- Menu A says "Lunch special is $10."
- Menu B says "Lunch special is $25."
Each group of customers agrees to pay based on their menu. Later, the host tries to claim "everyone agreed to $25."
BFT protocols require evidence (quorum certificates, signed messages) that is hard to forge and hard to equivocate without being caught.
Key insight
Equivocation turns local correctness into global inconsistency. BFT protocols are designed so that equivocation cannot produce two valid conflicting commit proofs.
Challenge question: What cryptographic primitive is the most direct defense against equivocation: encryption, signatures, or hashing?
Answer: signatures (or MACs in a fixed membership setting). Hashing helps bind payloads, but does not attribute statements to identities.
Section 6 - Timing Assumptions: FLP, Partial Synchrony, and Why Liveness Is Conditional
Scenario
You deploy BFT across regions. Sometimes the network is slow. Sometimes packets reorder. Sometimes a node is overloaded.
Pause and think
Which statement is true?
- A) BFT guarantees progress regardless of network delays
- B) BFT can guarantee safety regardless of network delays, but liveness needs timing assumptions
- C) BFT needs perfectly synchronous clocks to work
Pause and think.
Answer
B.
- FLP impossibility: in a fully asynchronous network, deterministic consensus cannot guarantee termination if even one node may fail.
- BFT protocols typically guarantee:
- Safety always
- Liveness once the system becomes "well-behaved" (partial synchrony: there exists a time after which message delays are bounded, though the bound is unknown).
Mental model
Think of a group chat where some people may lie. You can always avoid agreeing on two different plans (safety) by refusing to finalize until enough confirmations arrive. But if the chat is extremely laggy and messages arrive unpredictably, you might never finalize (liveness).
Common misconception
"BFT means the system always makes progress, even under attack."
Reality:
- Attackers can often delay liveness by targeting the leader, saturating links, or causing repeated view changes.
- BFT aims to ensure that eventual progress happens when the network and scheduling conditions allow it.
Key insight
BFT is not magic against the network. It is a safety guarantee against lies, and a liveness guarantee under partial synchrony.
Challenge question: If a Byzantine node can delay messages (or the network delays them), how does a protocol decide when to "give up on the leader"?
Clarification: timeouts are heuristic and must be adaptive. Too small -> view-change storms; too large -> slow recovery from a faulty leader.
Section 7 - Decision Game: What Does It Mean to "Commit" in BFT?
Scenario
You are reading a BFT protocol description. It says:
- replicas "prepare" a value
- then they "commit" a value
Decision game
Which statement is true?
- Commit means at least f+1 replicas have seen the value.
- Commit means at least 2f+1 replicas have signed/voted in a way that implies quorum intersection.
- Commit means the leader says it is committed.
Pause and think.
Answer
In classic BFT replication (PBFT-like), committing requires evidence from a supermajority (often 2f+1) so that:
- any other conflicting commit would require overlap
- overlap contains at least one honest replica
- honest replicas will not sign conflicting commits
Analogy: Delivery confirmation
A single courier claiming "delivered" is not enough if couriers can lie. You require confirmations from multiple independent couriers, where the overlap between any two "delivered" claims includes at least one trustworthy courier.
Key insight
"Commit" is a proof object (explicit or implicit) that survives Byzantine behavior via quorum intersection.
Challenge question: If commit requires 2f+1 votes, what is the minimum number of honest votes included in that set?
Answer: at least (2f+1) - f = f+1 honest votes.
Section 8 - PBFT, Explained Like a Busy Cafe (Pre-Prepare / Prepare / Commit)
Scenario
A cafe has a head barista (leader) who calls out orders, and multiple baristas (replicas) who must all make drinks in the same order.
If the head barista is malicious, they might call different orders to different baristas.
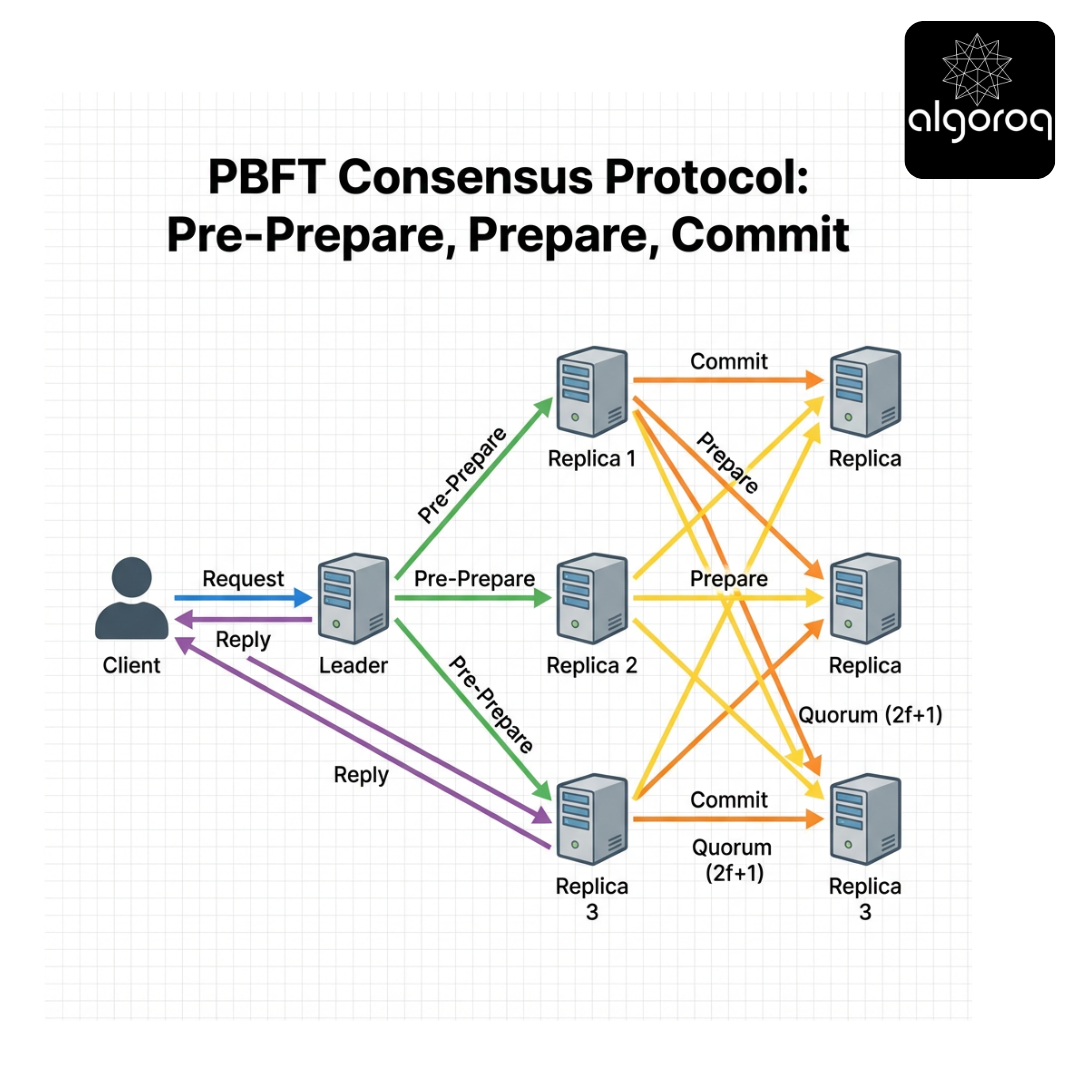
Interactive walk-through
Assume n = 3f + 1 replicas. Let f = 1, so n = 4.
Replicas: R0 (leader), R1, R2, R3.
A client sends request op.
Step 1: Pre-prepare
Leader assigns a sequence number s and broadcasts:
- PRE-PREPARE(view=v, seq=s, digest=H(op))
Pause and think: What is the leader's opportunity to cheat here?
Answer reveal:
- It can send different op (or different digests) under the same (v, s) to different replicas.
Step 2: Prepare
Each replica that accepts the pre-prepare broadcasts:
- PREPARE(v, s, digest) signed
A replica is "prepared" when it has:
- the pre-prepare
- plus 2f matching prepare messages from others (so total 2f+1 including itself)
Pause and think: Why not commit immediately after pre-prepare?
Answer reveal:
- Because only the leader spoke. You need the group to confirm they saw the same proposal.
Step 3: Commit
Prepared replicas broadcast:
- COMMIT(v, s, digest) signed
A replica commits when it has 2f+1 matching commit messages.
Then it executes op at position s and replies to the client.
Why two echo phases?
- Prepare phase ensures replicas converge on the same proposal for (v, s).
- Commit phase ensures enough replicas know that enough replicas know (a "knowledge" escalation) to make the decision stable across view changes.
Real-world parallel
In a restaurant:
- Head chef calls a ticket number and dish.
- Each station repeats the ticket aloud ("I heard ticket #42: ramen").
- Only after enough stations confirm does anyone start plating.
Key insight
PBFT's phases are about turning a leader's proposal into a quorum-backed fact that survives leader replacement.
Challenge question: In PBFT, why does the client typically wait for f+1 matching replies (not just 1)?
Clarification: waiting for f+1 matching replies ensures at least one reply is from an honest replica. However, it does not by itself prove global commit unless the protocol ensures honest replicas only reply after commit.
Section 9 - Common Misconception: "BFT Is Just Paxos With Signatures"
Misconception
"If I add signatures to Raft/Paxos messages, I get BFT."
Why it is wrong
Crash-fault protocols rely on assumptions that break under Byzantine behavior:
- A leader will not equivocate.
- Followers will not send conflicting votes.
- Log matching properties assume honest behavior.
With Byzantine nodes:
- a follower can vote for multiple candidates/leaders
- a leader can propose conflicting log entries for the same index
- nodes can fabricate "I got this entry earlier" stories
Mental model
Crash-fault consensus is like a meeting where people might leave early. Byzantine consensus is like a meeting where some people might actively forge minutes and misquote others.
Key differences (comparison table)
| Feature | Crash fault (Raft/Paxos) | Byzantine fault (PBFT/HotStuff/Tendermint) |
|---|---|---|
| Fault behavior | stop/omit | arbitrary, equivocation |
| Typical replicas for f faults | 2f+1 | 3f+1 |
| Quorum size | f+1 majority | 2f+1 supermajority |
| Identity/authentication | helpful but not essential | essential |
| View change complexity | moderate | often heavy |
| Client confirmation | often 1 leader reply | often f+1 matching replies or proof-carrying replies |
Key insight
BFT is not "signatures on Raft." It is a different quorum geometry and a different set of invariants.
Challenge question: Which part is harder to adapt from crash-fault to Byzantine: leader election, log replication, or membership changes? Why?
Production insight: membership changes are usually the hardest because they combine safety proofs, key management, and operational workflows (who is allowed to join/leave and how that is authorized).
Section 10 - View Change: Replacing a Potentially Malicious Leader
Scenario
Your current leader is slow - or maliciously stalling progress. Replicas need to switch leaders without breaking safety.
Pause and think
What is the danger in switching leaders too eagerly?
- A) It leaks secrets
- B) It can cause two different values to be committed for the same log position
- C) It only increases CPU usage
Pause and think.
Answer
B.
A leader change is where many BFT protocols are most subtle.
If some replicas believe entry x is committed at index s, and others believe y is committed at s, you have lost safety.
So view change protocols must ensure:
- the new leader learns the "most safe" value to propose for each sequence number
- Byzantine replicas cannot trick the leader into choosing a conflicting value
Analogy
A new manager takes over mid-shift. They must reconcile which orders were actually confirmed and paid for, not just what one cashier claims.
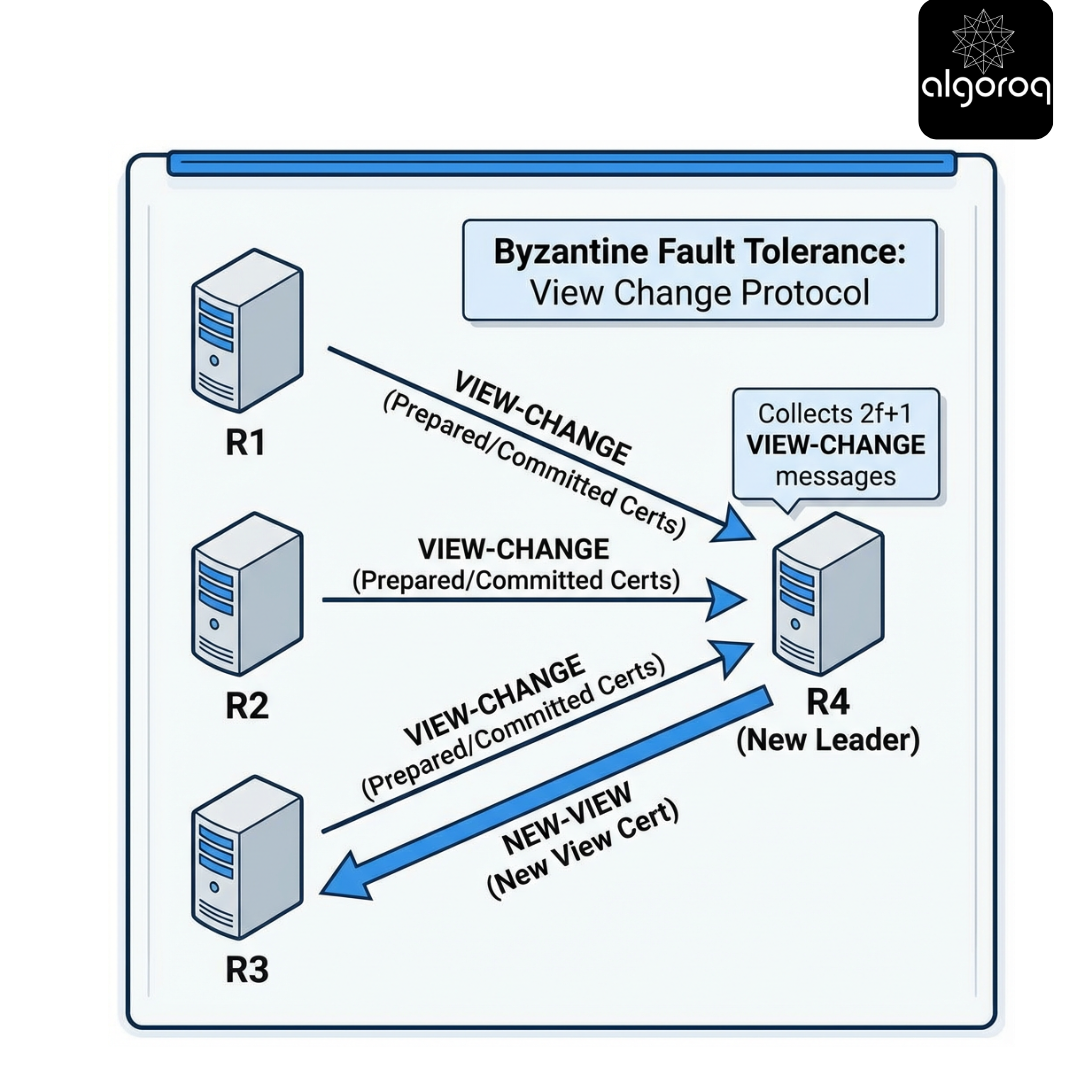
Key insight
View change is "state transfer of safety evidence." It is not just picking a new leader; it is picking a leader who can prove what is safe to continue.
Challenge question: Why does the new leader need to collect 2f+1 view-change messages, not just f+1?
Answer: with only f+1, the set could be dominated by Byzantine nodes and omit the honest evidence that some value was already prepared/committed.
Section 11 - Modern BFT: From PBFT to HotStuff (Why People Changed the Design)
Scenario
PBFT works, but engineers complain:
- message complexity is high
- view changes are complex
- multi-datacenter latency hurts
So modern protocols evolved.
Big idea: Quorum certificates (QCs)
Many newer protocols (e.g., HotStuff) structure consensus around a chain of blocks/commands where each step is backed by a quorum certificate: a set of 2f+1 signatures on a proposal.
This makes safety easier to reason about and view changes more uniform.
Comparison table: PBFT vs HotStuff-style
| Aspect | PBFT | HotStuff (high-level) |
|---|---|---|
| Core object | per-slot messages (prepare/commit) | chained proposals with QCs |
| Message pattern | O(n^2) broadcast phases | often O(n) with aggregation (e.g., threshold sigs) |
| View change | specialized, heavy | more uniform (QC carries safety) |
| Latency (happy path) | typically 3 phases | typically 3 phases; can pipeline |
| Implementation complexity | high | still high, but cleaner core proof story |
Key insight
Modern BFT tries to make "the proof of safety" a first-class artifact (QC) that naturally transfers across leaders.
Challenge question: Why might threshold signatures be attractive in BFT (bandwidth/verification), and what new trust assumptions do they introduce (DKG, key management)?
Clarification: threshold signatures reduce QC size from O(n) signatures to O(1) aggregated signature, but require:
- distributed key generation (DKG) or a trusted dealer
- careful share rotation / resharing
- robust handling of share compromise (a single node leaking its share can be catastrophic depending on threshold and adversary)
Section 12 - Failure Scenarios: What BFT Handles (and What It Does Not)
Scenario
You are asked: "If we use BFT, are we safe against everything?"
Decision game: Which statement is true?
- A) BFT prevents data loss, corruption, and denial-of-service.
- B) BFT prevents safety violations from up to f Byzantine replicas, but does not inherently prevent DoS or client-side compromise.
- C) BFT only works if attackers are non-colluding.
Pause and think.
Answer
B.
BFT protects agreement and integrity of the replicated state machine under bounded Byzantine faults.
It does not automatically solve:
- DoS: attackers can flood the network or exhaust CPU verifying signatures.
- Client compromise: a compromised client can submit validly signed but harmful transactions.
- Key theft: if an attacker steals private keys of more than f replicas, your fault bound is exceeded.
- Side channels: timing leaks, metadata leaks.
Failure scenario catalog
- Equivocating leader
- Defense: prepare/commit phases or QCs ensure equivocation cannot yield two commits.
- Byzantine follower sending conflicting votes
- Defense: quorums are sized so conflicting quorums intersect in honest nodes.
- Network partition
- Safety: preserved (no two commits) if protocol is correct.
- Liveness: may halt until synchrony/majority connectivity returns.
- Slow replica / straggler
- Usually tolerated; it just does not participate in quorums.
- Replay attacks
- Defense: include view/sequence numbers, nonces, and digests.
Key insight
BFT is primarily about integrity under adversarial replicas, not about availability under unlimited network-level attack.
Challenge question: In your system, what is the most realistic way an attacker might exceed the assumed f Byzantine nodes?
Production insight: correlated compromise (shared image, shared CI/CD, shared cloud account) is the #1 way BFT assumptions fail in practice.
Section 13 - Trade-offs: The Cost of Being Byzantine-Resilient
Scenario
Your team debates whether to use BFT or crash-fault replication.
Pause and think
What costs do BFT protocols typically impose compared to crash-fault protocols?
- A) More replicas
- B) More CPU (crypto)
- C) More network traffic
- D) More operational complexity (keys, membership)
- E) All of the above
Pause and think.
Answer
E.
Trade-off table
| Dimension | Crash fault tolerant (CFT) | Byzantine fault tolerant (BFT) |
|---|---|---|
| Replicas to tolerate f faults | 2f+1 | 3f+1 |
| Message complexity | often O(n) per step | often O(n^2) unless optimized |
| Crypto | optional | mandatory (auth, often signatures) |
| Latency | lower | higher (extra phases, verification) |
| Membership changes | already tricky | harder (must be Byzantine-safe) |
| Threat model | accidents, outages | compromise, insider risk |
Mental model
CFT is like "we assume staff are honest but sometimes absent." BFT is like "some staff might be bribed and will forge receipts."
You need more witnesses, more paperwork, and stricter identity checks.
Key insight
BFT is chosen when the cost of a safety failure is catastrophic or when participants are not fully trusted.
Challenge question: If you control all machines in one cloud account, is BFT still valuable? Under what compromise scenarios?
Trade-off analysis: if your primary risk is operator / insider compromise or supply-chain compromise, BFT can still help - but only if you also split admin domains and keys. If everything is under one root credential, BFT adds cost without meaningfully reducing risk.
Section 14 - Interactive Exercise: Compute Quorums and Client Wait Conditions
Scenario
You run a BFT cluster with n replicas.
Exercise A: Fault tolerance
Fill in the blanks.
- If n = 4, then f = ___ (max) under 3f+1.
- If n = 7, then f = ___ (max).
- If you want f = 2, you need n = _.
Pause and think.
Answer reveal:
- f = 1
- f = 2 (since 3*2+1=7)
- n = 7*
Exercise B: Quorum sizes
For f = 2:
- commit quorum size (typical) = ___
- minimum honest votes inside = ___
Pause and think.
Answer reveal:
- commit quorum size = 2f+1 = 5
- minimum honest votes inside = (2f+1) - f = f+1 = 3
Exercise C: Client replies
Many BFT SMR systems have clients wait for f+1 matching replies.
Pause and think: Why f+1 and not 2f+1?
Answer reveal:
- If up to f replicas can lie, then f+1 matching replies guarantees at least one is honest.
- The client does not need a full commit certificate; it needs confidence the operation was executed by at least one honest replica that will not lie about the committed state.
- Some systems do require stronger client-side proofs (e.g., QC) depending on API and threat model.
Key insight
Replica quorums and client confirmation thresholds are different knobs, chosen based on what the client must be able to prove.
Challenge question: In a read-heavy system, how would you design a BFT "read" path that is fast but safe?
Section 15 - Reads Are Hard: Linearizability, Fast Reads, and Proof-Carrying Data
Scenario
A client asks GET(x) right after another client did PUT(x=1).
In a linearizable system, the read must reflect the latest committed write.
Pause and think
Why are reads trickier in BFT than in a single-leader CFT system?
- A) Because signatures make reads slow
- B) Because a Byzantine replica can return a plausible but stale or fabricated value
- C) Because GET is not a replicated command
Pause and think.
Answer
B (and C is a common trap).
Even if GET is "read-only," a Byzantine replica can:
- lie about the value
- lie about the commit index
- lie about whether a write was committed
So BFT systems often use one of these approaches:
-
Read from quorum
- query multiple replicas
- wait for f+1 matching replies (or more)
- optionally require proofs (signatures/QCs)
-
Leader-based reads
- route reads through the current leader
- ensures ordering with writes
- but leader might be Byzantine; you still need client-side verification or replica confirmations
-
Proof-carrying reads
- replica returns value + a QC / commit proof
- client verifies proof without trusting the replica
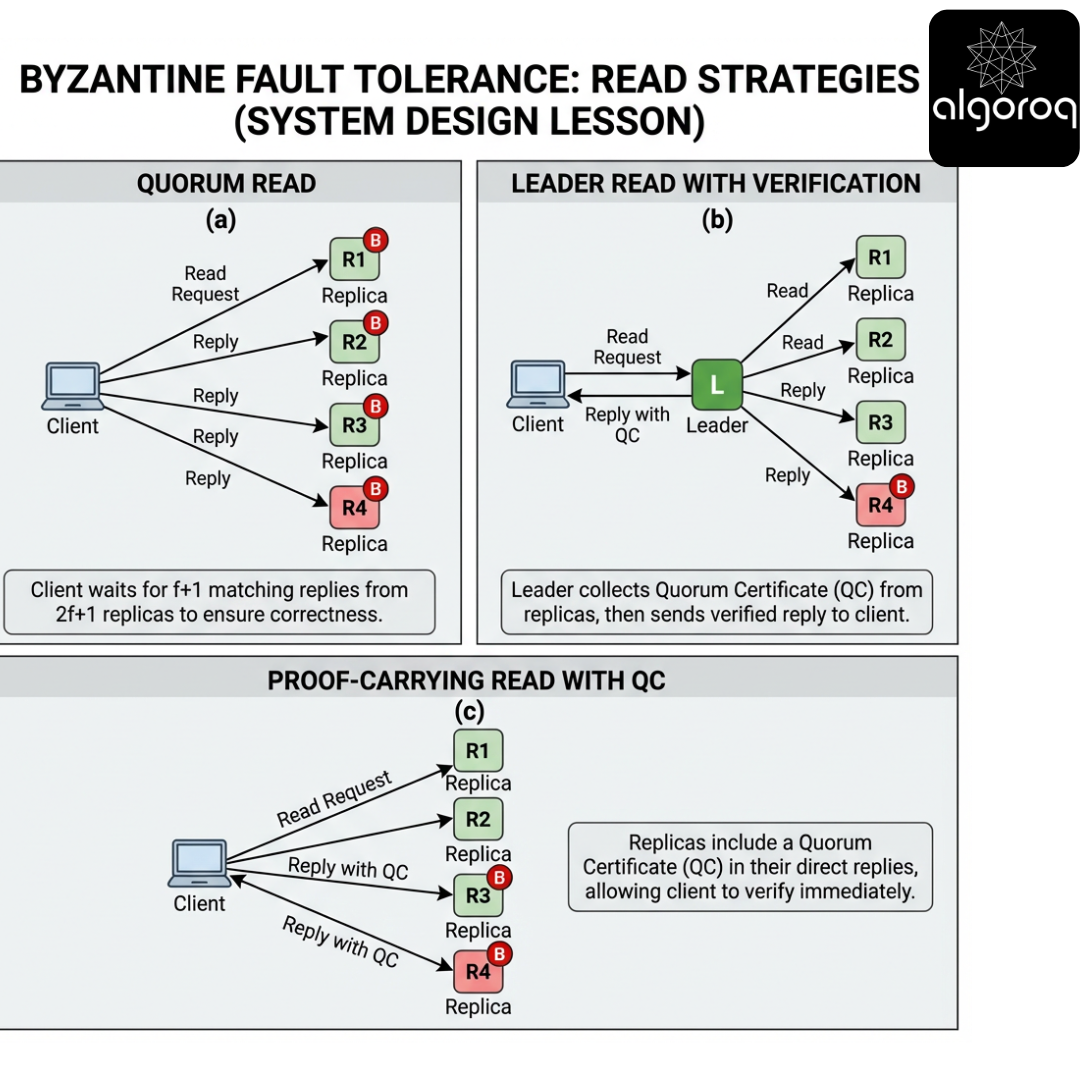
Key insight
In BFT, a "fast read" usually requires either multiple replicas or a cryptographic proof that binds the read to the committed log.
Challenge question: If clients can verify commit proofs, what does that do to the trust boundary between clients and replicas?
Production insight: proof-carrying reads shift trust from "replica honesty" to "cryptographic verification + correct membership roots." This is great for untrusted clients, but increases proof distribution and verification costs.
Section 16 - Common Misconception: "BFT Means Stronger Consistency Than CFT"
Misconception
"If it is Byzantine fault tolerant, it must be 'more consistent' than Raft."
Reality
BFT is about tolerating a stronger failure model, not necessarily providing stronger consistency semantics.
- Both CFT and BFT systems can provide linearizability.
- Both can provide weaker models if configured that way.
- BFT's differentiator is that safety holds even when some replicas actively try to violate it.
Mental model
Consistency is the "rules of the game." Fault tolerance is "how many cheaters you can handle without breaking the rules."
Key insight
BFT does not automatically mean "stronger semantics." It means "same semantics under a harsher adversary."
Challenge question: Can you design a BFT system that is only eventually consistent? Why might someone do that?
Answer: yes - e.g., a geo-replicated system might accept weaker semantics for availability/latency, while still using Byzantine-resilient techniques to prevent forgery or equivocation in anti-entropy.
Section 17 - Membership and Key Management: The Operational Reality
Scenario
You want to add/remove replicas. In BFT, this is not just autoscaling - membership defines who is allowed to vote.
Pause and think
What is the biggest operational risk unique to BFT?
- A) Disk space
- B) Key compromise and identity management
- C) CPU cache misses
Pause and think.
Answer
B.
If keys are stolen:
- an attacker can impersonate replicas
- your assumed f bound may be silently exceeded
Key management concerns
- provisioning identities (certificates)
- secure storage (HSMs, enclaves, offline roots)
- rotation without breaking quorum assumptions
- threshold signature setup (distributed key generation)
Key insight
In BFT, "who can sign" is part of the correctness argument. Operations and security engineering are inseparable.
Challenge question: If you rotate keys for a replica, how do you prevent a Byzantine node from using both old and new keys to double-vote?
Production pattern: treat key rotation as a membership update with an epoch number; replicas reject votes signed by keys not valid for the current epoch, and the epoch transition itself is decided by consensus.
Section 18 - Real-World Usage: Where BFT Shows Up (and Why)
Scenario
You are deciding whether BFT is worth it. Where is it actually used?
Examples (patterns, not endorsements)
-
Permissioned / consortium blockchains
- Participants are known organizations.
- BFT provides safety even if some orgs misbehave.
- Often chosen for finality (no probabilistic forks) and governance.
-
Critical coordination services
- Small clusters managing high-value configuration.
- BFT protects against insider compromise.
-
Secure logging / append-only systems
- BFT or related techniques ensure logs cannot be rewritten by a minority.
-
Multi-party custody / governance
- Not always "consensus," but BFT ideas appear: quorum approvals, threshold signatures.
Decision checklist
BFT is most compelling when:
- the cost of a safety failure is extreme
- participants are not fully trusted
- compromise is plausible (insiders, supply chain)
- you can afford extra replicas and complexity
BFT may be overkill when:
- you control all nodes in a single trust domain
- your main risk is outages, not compromise
- you need massive scale with minimal latency
Key insight
BFT is a risk decision as much as a technical decision.
Challenge question: What is your system's "Byzantine story"? Who might cheat, and how?
Section 19 - Implementation Notes: Message Authentication, Digests, and State Transfer
Scenario
You are implementing a BFT protocol. What are the practical building blocks?
Building blocks
- Authenticated channels: TLS with mutual auth, or message-level signatures.
- Digests: hash of request payload to avoid resending large messages.
- Replay protection: view numbers, sequence numbers, nonces.
- State transfer: catching up slow replicas with checkpoints and log segments.
- Checkpointing: periodic snapshots agreed by quorum.
Common pitfall
"We verified signatures, so we are safe."
But you also need:
- correct domain separation (what exactly is signed)
- canonical serialization (avoid ambiguous encodings)
- anti-replay logic
- careful handling of partial state transfer (do not accept unproven snapshots)
Key insight
The protocol proof assumes perfect authentication and correct message parsing. Real implementations must make those assumptions true.
Challenge question: What is the worst thing that can happen if two implementations serialize the same message differently before signing?
Answer: you can get consensus splits where different replicas believe they signed/verified different bytes for "the same" logical message.
Section 20 - Quiz: Spot the BFT Bug
Scenario
A teammate proposes a simplified commit rule:
"If a replica receives f+1 commit messages for digest D, it commits."
Pause and think
Is this safe?
- A) Yes, because at least one is honest
- B) No, because f Byzantine replicas can trick different honest replicas into committing different values
- C) Yes, if we use SHA-256
Pause and think.
Answer
B.
f+1 only guarantees at least one honest participant, but it does not guarantee quorum intersection strong enough to prevent conflicting commits.
To prevent two different values from both committing, you typically need a threshold like 2f+1 for commit evidence.
Key insight
"At least one honest" is not enough to prevent split-brain decisions. You need quorum intersection that forces shared honest witnesses.
Challenge question: Construct a scenario with n=4, f=1 where two honest replicas could each see f+1 commits for different digests.
Example sketch:
- Byzantine leader equivocates: sends digest D to R1, digest D' to R2.
- Byzantine replica R3 sends COMMIT(D) to R1 and COMMIT(D') to R2.
- R1 sees commits from {R1, R3} and commits D.
- R2 sees commits from {R2, R3} and commits D'.
Section 21 - Performance Engineering: Where the Time Goes
Scenario
Your BFT prototype is correct but slow.
Where overhead comes from
- Signature generation and verification
- O(n^2) broadcasts
- cross-region RTT per phase
- view changes under load
- state transfer and checkpoint verification
Techniques
- Batching: combine many client requests into one proposal.
- Pipelining: overlap phases for consecutive slots.
- Signature aggregation: threshold signatures to reduce bandwidth and verification cost.
- Hardware acceleration: HSMs, crypto offload.
- Careful networking: UDP + retransmit vs TCP; kernel bypass in some designs.
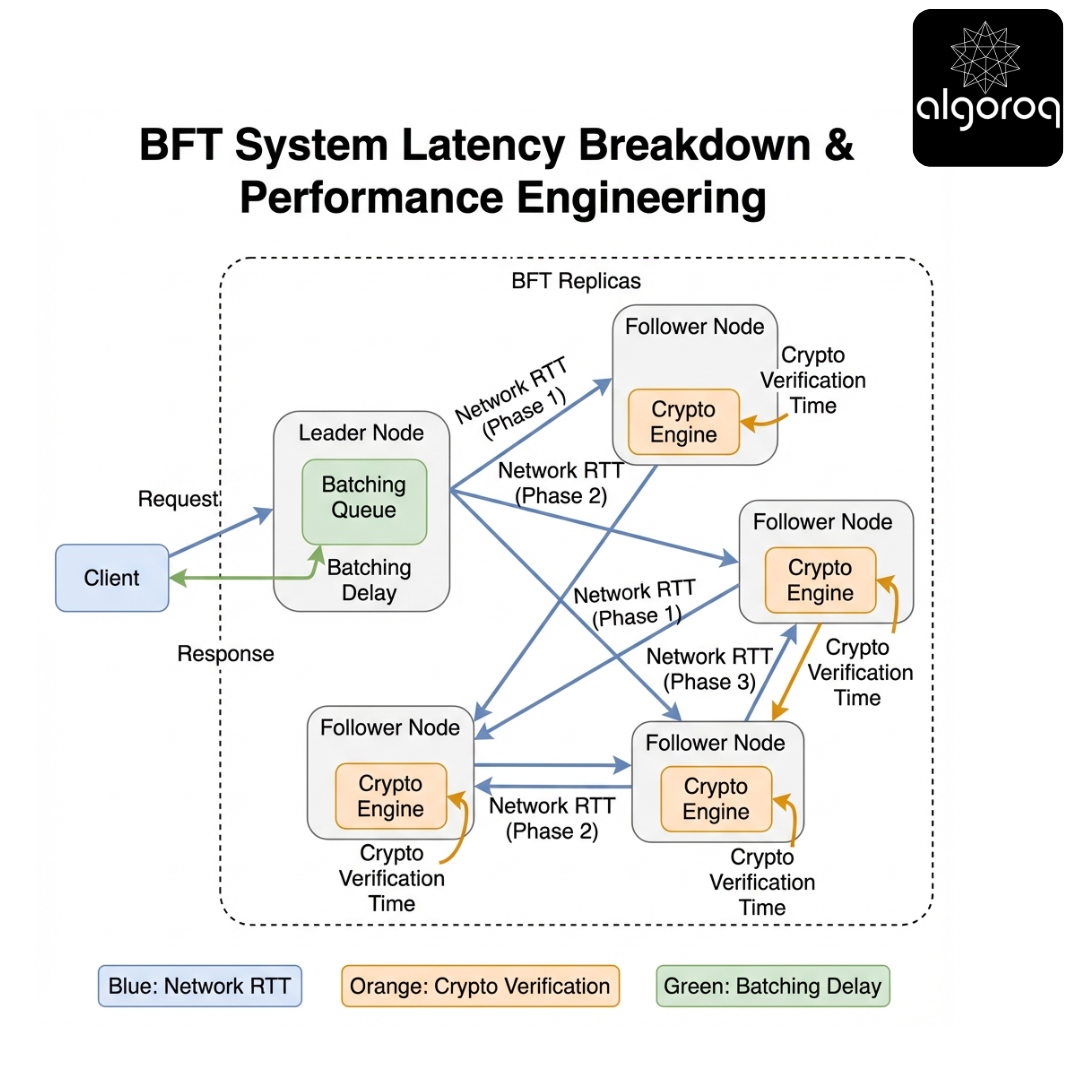
Key insight
BFT performance is dominated by "phases x RTT" and "signatures x n." Most optimizations target one of those multipliers.
Challenge question: If your replicas are in 3 regions with 50ms RTT, what is the best-case commit latency for a 3-phase protocol without pipelining?
Answer: roughly 3 RTTs ~= 150ms (plus crypto + queuing). In practice, cross-region tail latency and batching often dominate.
Section 22 - Threat Modeling: When BFT Assumptions Fail
Scenario
You built for f Byzantine faults. What if reality is worse?
Pause and think
Which assumption is most fragile in practice?
- A) The hash function is collision-resistant
- B) At most f replicas are compromised at the same time
- C) TCP delivers packets in order
Pause and think.
Answer
B.
Compromise can be correlated:
- a shared vulnerability
- a stolen deployment credential
- a compromised CI/CD pipeline
- a cloud control-plane incident
If more than f replicas are Byzantine, safety can fail.
Mitigations
- diversity (OS, cloud, hardware)
- independent admin domains
- strong key isolation
- monitoring for equivocation (audit logs)
- rapid incident response and membership reconfiguration
Key insight
BFT's guarantees are only as good as your compromise independence. "3f+1" assumes failures are not perfectly correlated.
Challenge question: What operational practices would you adopt to make "independent failures" more realistic?
Section 23 - Design Patterns: Choosing Between CFT, BFT, and Hybrid Approaches
Scenario
You need a replicated control plane for a platform.
Decision game
Which approach would you pick?
- A) Pure CFT (Raft) + strong perimeter security
- B) Pure BFT (PBFT/HotStuff) for everything
- C) Hybrid: CFT for most operations, BFT/threshold approvals for the most critical actions
Pause and think.
Answer
Often C is the pragmatic choice.
Examples:
- Use Raft for routine config replication.
- Require threshold signatures / multi-party approvals for:
- key rotations
- policy changes
- large transfers
This reduces the surface area where full BFT cost applies.
Key insight
You can apply Byzantine-resilience selectively. Not every byte needs BFT; the highest-risk decisions often do.
Challenge question: Identify one action in your system that would benefit most from a threshold approval model.
Section 24 - Final Synthesis Challenge: Design a BFT Service You Would Actually Ship
(CHALLENGE) Synthesis scenario You are building a multi-organization configuration registry for critical infrastructure. Three companies jointly operate it. They do not fully trust each other. The registry stores:
- service endpoints
- certificate pins
- feature flags for safety-critical rollouts
Requirements:
- linearizable writes
- reads must be verifiable by clients
- tolerate up to f Byzantine replicas
- multi-region deployment
Part 1 - Pick parameters
- You want to tolerate f = 1 Byzantine replica. How many replicas do you deploy?
- What quorum size do you require for commit proofs?
Pause and think.
Answer reveal:
- n = 3f + 1 = 4
- commit quorum = 2f + 1 = 3
Part 2 - Choose a read strategy
Pick one:
- A) Query 1 replica (fastest)
- B) Query f+1 replicas and require matching replies
- C) Query 1 replica but require a QC/commit proof attached
Pause and think.
Answer reveal:
- A is unsafe under Byzantine faults.
- B is safe but increases latency and load.
- C is often best for "verifiable reads," but requires the system to produce and distribute proofs.
Part 3 - Failure drill
A leader is suspected Byzantine (equivocating). What do replicas do?
Pause and think.
Answer reveal:
- Trigger a view change after timeout.
- Collect 2f+1 view-change messages.
- New leader proposes safe continuation based on highest prepared/committed evidence.
Part 4 - Operational plan
List two operational controls you implement to keep "at most f compromised replicas" realistic.
Pause and think.
Answer reveal (examples):
- Run replicas in independent admin domains / separate cloud accounts.
- Use HSM-backed keys + strict rotation + audit trails.
Final reflection
If you had to explain to an auditor why your system remains safe with one malicious operator, what artifacts would you present?
- protocol spec and safety proof sketch
- logs showing signed votes / QCs
- key management policy
- incident response and membership change procedures
Key insight
Shipping BFT is not just implementing a protocol. It is aligning threat model, cryptography, operations, and performance into a coherent story.
Appendix A - Quick Reference Cheatsheet
- Byzantine fault: arbitrary behavior (lies, equivocation, corruption)
- Typical bound: tolerate f Byzantine with n = 3f + 1 replicas
- Typical commit quorum: 2f + 1
- Safety: no two honest replicas decide differently
- Liveness: progress under partial synchrony
- Client confirmation: often f+1 matching replies or proof-carrying responses
- [CODE: Rust, implement threshold signature aggregation stub and QC verification interface.]
Closing challenge: If you could change one assumption (synchrony, authentication, membership, or fault bound), which would you change to make BFT cheaper - and what new failure would that allow?
Key Takeaways
- Byzantine faults are when nodes behave arbitrarily (including maliciously) — sending conflicting information to different peers
- BFT requires 3f+1 nodes to tolerate f Byzantine failures — a 4-node system can tolerate 1 malicious node
- PBFT (Practical Byzantine Fault Tolerance) enables consensus despite Byzantine nodes — but requires O(n^2) messages per consensus round
- BFT is essential for blockchain and financial systems — where participants may not trust each other
- Most distributed systems assume crash-stop failures, not Byzantine — BFT is expensive and only needed when trust is absent