Quorum and Sloppy Quorum

Quorum and Sloppy Quorum (Interactive Deep Dive)
Audience: engineers who already know replication basics and want to reason precisely about quorums, failure modes, and why systems like Dynamo/Cassandra/Riak use sloppy quorums + hinted handoff.
The Coffee Chain That Can’t Agree on Your Order
You run a coffee chain with N = 5 stores in the same neighborhood. Every store keeps a copy of the menu and your customer’s loyalty balance.
A customer buys a coffee at Store A, then immediately tries to redeem points at Store D. Some stores are temporarily offline (construction, network issues). You need a rule that answers:
- When is a write “accepted”?
- When is a read “trustworthy”?
- What happens when some stores are unreachable?
Pause and think: If you wait for all stores for every operation, what happens during even a small outage?
Progressive reveal -> Answer:
- Waiting for all stores gives strong agreement but terrible availability.
- Waiting for some stores gives availability but risks inconsistency.
This is the core tension: consistency vs availability under partitions.
Network assumption (explicit): nodes can crash, messages can be delayed/reordered/dropped, and partitions can occur. Clocks are not perfectly synchronized.
Key insight: A quorum is a rule that says “if enough replicas participate, we can proceed.”
Quorum 101 — The “Enough People Signed” Rule
Scenario
You have replicated data across N replicas. For each operation:
- A write is sent to replicas and considered committed when W replicas acknowledge.
- A read queries replicas and returns after R replicas respond.
Interactive question (pause and think)
If N = 5, what values of R and W ensure that a read is guaranteed to overlap with the latest successful write?
Write down a guess.
Explanation (with analogy)
Think of a restaurant chain that updates its “today’s special.”
- Write quorum (W): how many managers must sign off before the special is official.
- Read quorum (R): how many managers you call before you trust what the special is.
If the set of managers you call always includes at least one manager who signed the latest update, you’ll hear about the latest special.
That’s the overlap rule.
“Overlapping majorities”
A classic quorum condition for single-key replication:
- If R + W > N, then every read quorum intersects every write quorum.
Because two sets of size R and W in a universe of N must overlap if they sum to more than N.
Progressive reveal -> Answer
For N = 5, examples that satisfy R + W > 5:
- R=3, W=3 (3+3=6)
- R=2, W=4 (2+4=6)
- R=1, W=5 (1+5=6)
Key insight: R + W > N gives you an intersection property. Whether that yields “fresh reads” depends on ack semantics, versioning, and read selection.
“R + W > N Means Linearizability”
Misconception
If R + W > N, then the system is linearizable.
Reality
Not necessarily. The overlap property alone doesn’t guarantee linearizability because:
- Writes may be concurrent.
- Replicas may acknowledge writes in different orders.
- Network delays can cause a read quorum to see a newer write at one replica and an older write at another.
- You still need a versioning scheme (timestamps, vector clocks, HLC, etc.) and a conflict resolution policy.
Important correction: Even with versioning + read-repair, leaderless quorums typically provide eventual consistency with tunable staleness, not linearizability. Linearizability generally requires consensus/leader or specialized protocols (e.g., ABD register with strict quorum rules and write-back on reads).
Pause and think: What if a write is acknowledged by W replicas, but a read hits R replicas that include one of those W - yet that replica hasn’t applied the write due to async apply after ack?
Answer: Then your “overlap” doesn’t help. Quorum math assumes acknowledgers have the update durably applied (or at least durably logged) before ack.
Key insight: Quorum math is about set intersection, but correctness depends on what ack means and how versions are compared.
Which Statement Is True?
Choose one. (Pause and decide before revealing.)
- A. If R + W > N, stale reads are impossible.
- B. If R + W > N, stale reads are unlikely but still possible under concurrency.
- C. If R + W > N, stale reads are avoidable if the system uses versioning and read-repair.
Reveal
B is the most generally correct statement for leaderless replication.
- R + W > N ensures intersection with some replica that participated in the last successful write, if acks imply the write is durably recorded.
- But under concurrency, clock skew, partial failures, and non-linearizable conflict resolution (e.g., LWW), you can still observe anomalies.
When can you get stronger guarantees?
- If you implement a linearizable register protocol (consensus-like or ABD-style) with read quorum write-back and strict ordering assumptions, you can avoid stale reads - but that’s no longer “just” Dynamo-style quorum.
Key insight: Quorums help you bound staleness and detect divergence; they don’t automatically impose a single global order.
Quorum Reads and Writes in Practice
Scenario
You’re implementing a key-value store with replication.
- N replicas per key (replication factor)
- Coordinator node routes reads/writes
Interactive question (pause and think)
Suppose:
- N=3
- W=2
- R=2
A write succeeds (2 acks). Immediately after, a read is issued.
What must be true for the read to return the new value?
Explanation
At least one replica in the read quorum must have the new value, and the coordinator must be able to pick the newest version.
If versions are comparable (e.g., LWW timestamps), coordinator selects the max.
Production nuance: If you use LWW, you must define who assigns timestamps (client vs coordinator vs replica) and how you handle clock skew. Many production systems use server-assigned timestamps or HLC to reduce skew-induced anomalies.
Key insight: Quorum reads often work by (1) fetch multiple versions -> (2) pick winner/merge -> (3) optionally repair lagging replicas.
Code: quorum coordinator read/write with versioning + read-repair (toy)
Below is a toy implementation. It is not production-safe (no timeouts, no partial response handling, no durable storage), but it illustrates the control flow.
Key production clarifications added:
- Acks must mean durably recorded (WAL/fsync depending on durability target).
- Read-repair is usually async and often rate-limited.
- LWW is unsafe under clock skew; prefer HLC or vector clocks + merge.
Matching Exercise: Pick R/W for a Goal
Match each goal to a plausible (R, W) choice for N=5.
Goals:
- Max availability for writes (accept writes even if many replicas down)
- Stronger reads (reduce staleness)
- Balanced (typical)
Choices:
- a) R=1, W=3
- b) R=3, W=3
- c) R=1, W=1
- d) R=4, W=1
Pause and think.
Reveal
- 1 -> c) R=1, W=1 (highest availability, weakest consistency/durability)
- 2 -> b) R=3, W=3 (stronger intersection, but less available and higher latency)
- 3 -> a) R=1, W=3 (common: fast reads, safer writes)
What about d)? R=4, W=1 gives strong reads but very weak writes; often a poor choice if you care about durability/propagation.
Performance note: Increasing R or W increases tail latency because you wait for more replicas; the slowest replica among the required set dominates.
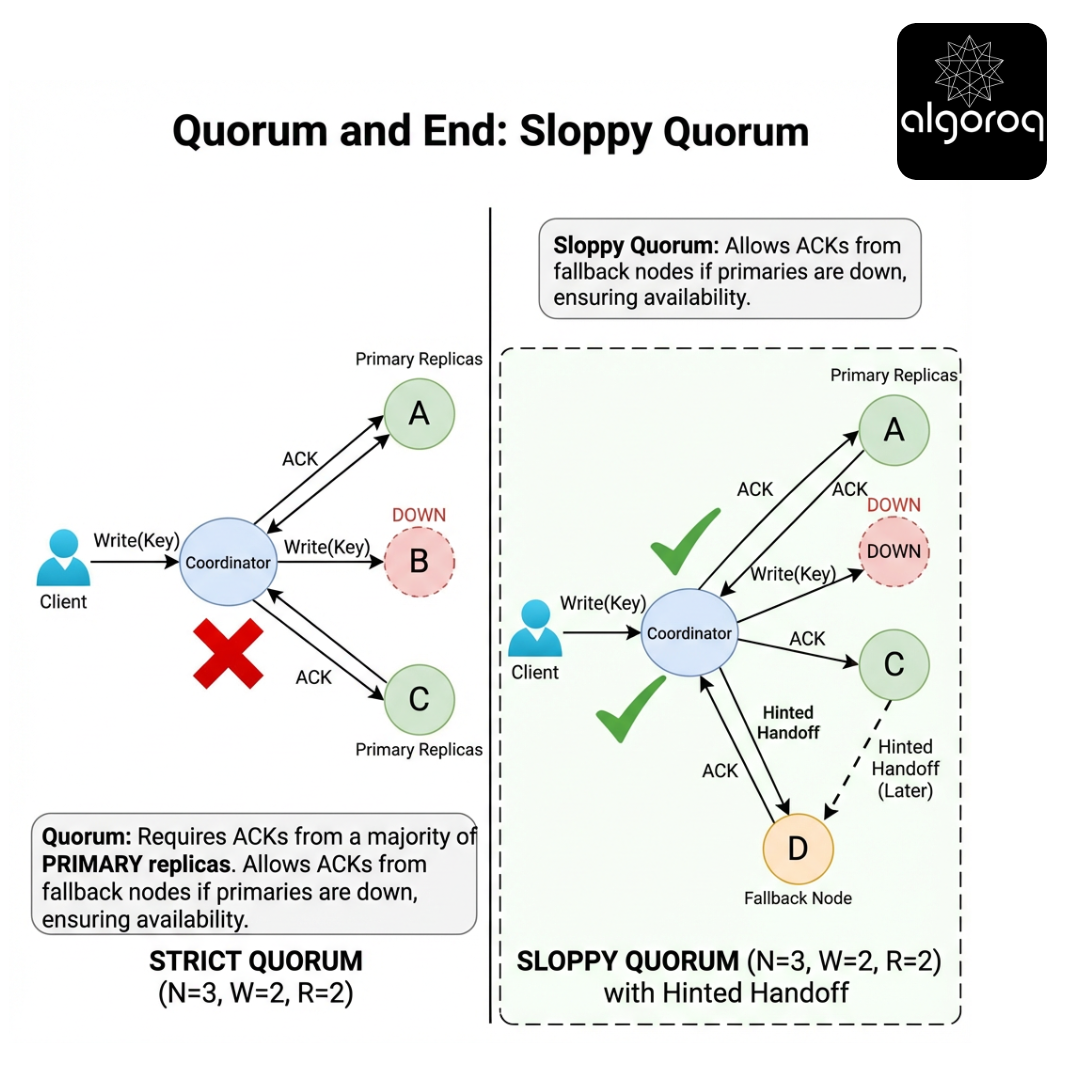
When Quorum Isn’t Enough — The Partition Problem
Scenario
Network partition splits replicas into two groups.
For N=5, imagine a partition of 2 replicas vs 3 replicas.
Interactive question (pause and think)
If your client is on the side with only 2 replicas reachable, can you still satisfy W=3 writes?
Reveal
No. You can’t gather 3 acknowledgements from only 2 reachable replicas.
So classic quorum systems face a choice:
- Reject writes (favor consistency)
- Accept writes with smaller W (favor availability)
This is where sloppy quorum enters.
CAP framing (rigorous): Under a partition, you must choose between Consistency (reject/limit operations to preserve a single-copy illusion) and Availability (respond to requests). Partition tolerance is assumed.
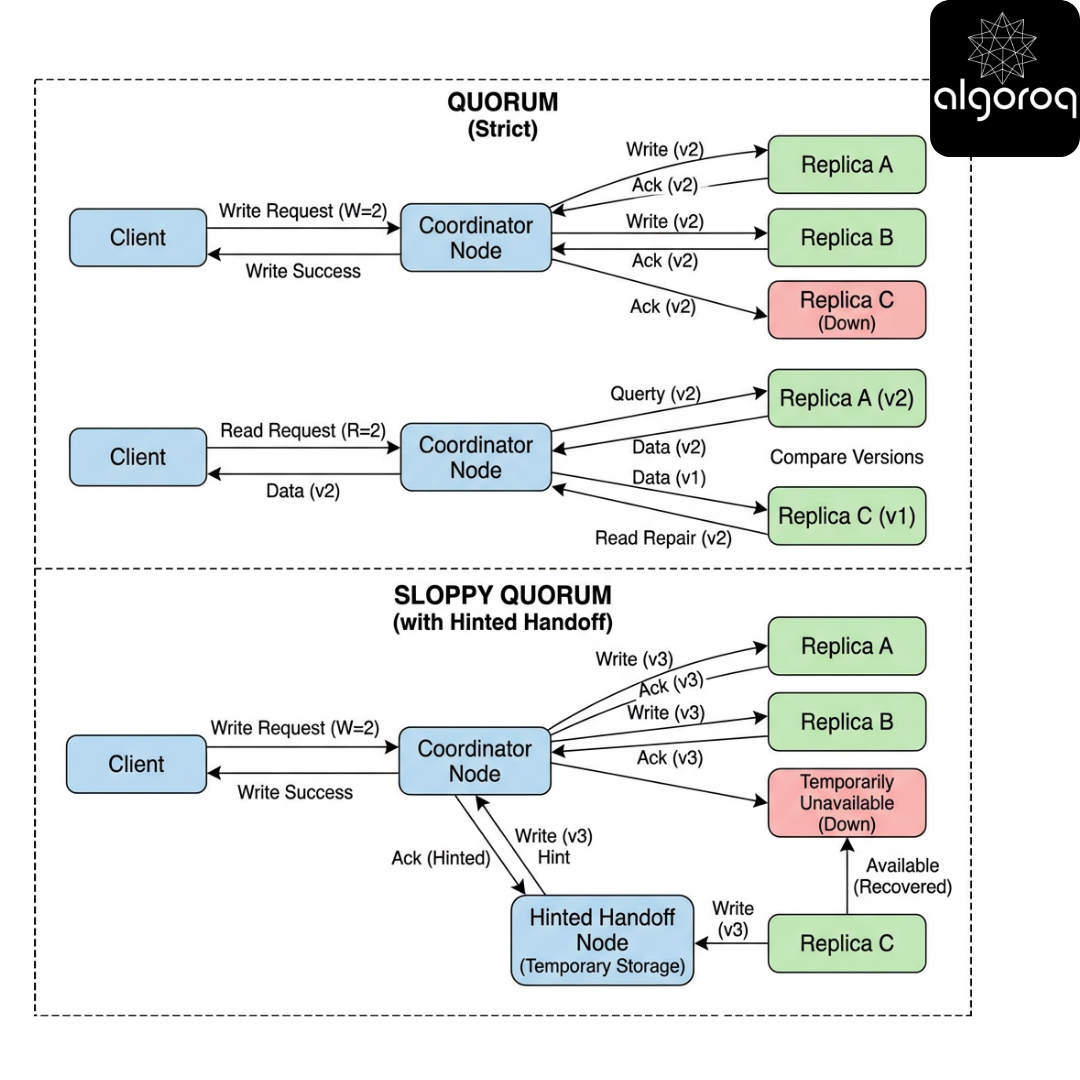
Sloppy Quorum — “Any Nearby Store Can Take Your Order”
Scenario
Some replicas for a key are down/unreachable. But you still want to accept writes.
Instead of writing only to the key’s home replicas, you write to fallback nodes (often chosen deterministically, e.g., “next nodes on the ring”) so you can still collect W acknowledgements.
This is sloppy quorum.
Interactive question (pause and think)
What do you lose by writing to “wrong” replicas?
Progressive reveal -> Answer
You lose the guarantee that a read quorum intersects the set of replicas that accepted the write within the intended replica set.
So you need extra mechanisms to converge:
- Hinted handoff (temporary custody + later delivery)
- Anti-entropy (Merkle trees / streaming repair)
- Conflict detection/merge (siblings via vector clocks, CRDTs, or application merge)
Key insight: Sloppy quorum buys availability by relaxing membership, then relies on repair to restore intended placement.
Production insight: sloppy quorum is bounded
Real systems bound sloppiness to avoid unbounded “temporary replica set expansion”:
- limit how far you walk the ring for fallbacks
- limit hinted handoff queue size / age
- shed load or fail writes when the system is too degraded
“Sloppy Quorum Means Anything Goes”
Misconception
Sloppy quorum is just writing to random nodes; consistency becomes meaningless.
Reality
Sloppy quorum is structured:
- You still target the key’s primary replicas.
- If they’re unavailable, you pick fallback nodes in a deterministic order.
- You attach hints so that data can be moved back.
It’s not chaos; it’s controlled degradation.
Key insight: Sloppy quorum is “write to the next best replicas with a plan to fix it later.”
Hinted Handoff — The Delivery Receipt You Keep
Scenario
Replica R2 is down. Coordinator writes the update to fallback node F.
F stores:
- the value
- metadata (version, write id)
- a hint: “this update is intended for R2”
When R2 returns, F forwards the update.
Interactive question (pause and think)
What happens if fallback node F crashes before handing off the hint?
Reveal
Then the hint is lost unless:
- it was replicated (hints stored redundantly)
- the system has another repair path (anti-entropy)
This is why sloppy quorum often pairs with periodic repair.
Key insight: Hinted handoff improves availability but can weaken durability unless hints are treated as durable data.
Production considerations for hinted handoff
- Durability: hints should be written to a local WAL; otherwise a restart loses them.
- Backpressure: if a node is down for hours, hints can grow without bound; enforce TTL/size limits.
- Hot keys: hinted handoff can amplify load when a popular key’s primary is down.
- Security/tenancy: hints may contain user data; treat them like normal replicated data (encryption, access controls).
Quorum vs Sloppy Quorum Under Failure
Setup
Replication factor N=3, W=2.
Replica set for key K: {A, B, C}.
C is down.
Question: Which behavior matches classic quorum vs sloppy quorum?
Statements:
- S1: Write must be acknowledged by two of {A,B,C}; if only A reachable, fail.
- S2: Write can be acknowledged by A and some fallback D; succeed, and later transfer to C.
Reveal
- Classic quorum -> S1
- Sloppy quorum -> S2
Key insight: Classic quorum constrains membership; sloppy quorum relaxes membership to preserve availability.
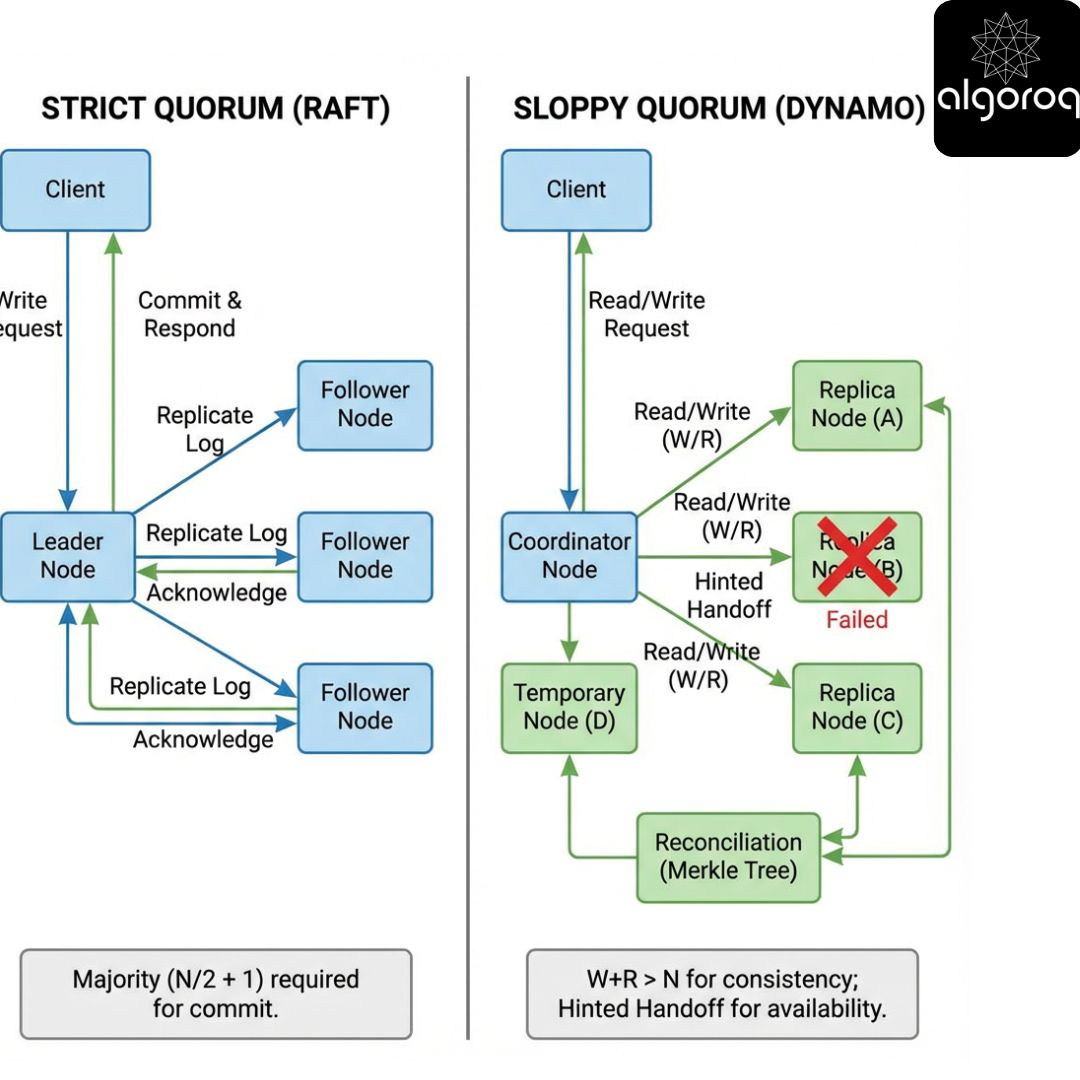
What “Quorum” Means Depends on the Replication Model
Scenario
You hear “quorum” and assume “majority vote.” But systems use quorums in different replication models:
- Leader-based replication (Raft/Paxos): quorum is about committing an ordered log.
- Leaderless replication (Dynamo-style): quorum is about intersecting replica sets and reconciling versions.
Interactive question (pause and think)
If a system uses Raft, is “R + W > N” the rule for correctness?
Reveal
No. In Raft, correctness depends on:
- leader election by majority
- log replication and commit index rules
Reads/writes are constrained by the leader and the committed log, not by arbitrary R/W tuning.
Key insight: In leader-based consensus, quorum ensures a single history. In leaderless quorum systems, quorum ensures overlap for reconciliation.
Failure Scenarios You Must Be Able to Reason About
We’ll walk through failure cases and ask “what does quorum guarantee?”
Case 1: Replica crash after ack
A replica acks a write, then crashes before persisting.
Does quorum still protect you?
Only if ack implies durability (WAL/fsync). If ack is “received in memory,” quorum math is meaningless for durability.
Production insight: define durability levels explicitly (e.g., Cassandra commitlog_sync, fsync interval). Your W is only as good as your weakest ack semantics.
Case 2: Coordinator failure mid-write
Coordinator sends write to A and B, gets ack from A, then dies before B acks.
Did the write “happen”?
Depends on client semantics:
- If client didn’t receive success, it may retry.
- Some replicas may have partial state.
This creates duplicates and conflicts unless operations are idempotent or use unique write IDs.
Production pattern: include a write_id (UUID) and have replicas dedupe; otherwise retries can create multiple versions.
Case 3: Network partition + sloppy quorum
Key’s replicas {A,B,C}. Partition isolates {A} alone; {B,C} together.
- Client near A wants to write.
- With sloppy quorum, A can write to fallback D and succeed with W=2 (A + D).
What happens when partition heals?
You now have divergent versions across {A,D} and {B,C}. Repair must reconcile.
Key insight: Sloppy quorum increases the number of places divergence can occur; repair is not optional.
Comparison Table: Classic vs Sloppy Quorum
| Property | Classic Quorum | Sloppy Quorum |
|---|---|---|
| Write targets | Fixed replica set for key | Prefer fixed set; fall back to other nodes |
| Availability under replica outage | Lower | Higher |
| Read/write intersection guarantee | Stronger (set-based) | Weaker (membership may differ) |
| Requires repair mechanisms | Helpful | Essential |
| Typical systems | Some quorum-based stores, some sharded DBs | Dynamo, Riak, Cassandra (variants) |
| Risk profile | Blocks under partitions | Accepts divergence, heals later |
Key insight: Classic quorum is “correctness first,” sloppy quorum is “service continuity first.”
Tuning Knobs and Trade-offs (N, R, W)
Scenario
You’re choosing replication parameters for a user profile service.
Constraints:
- Must remain writable during a single node failure.
- Reads should be fast.
- Inconsistency is tolerable for a few seconds (eventual consistency ok).
Interactive question (pause and think)
For N=3, what would you pick?
- Option 1: R=1, W=1
- Option 2: R=1, W=2
- Option 3: R=2, W=2
Reveal
Often Option 2 (R=1, W=2) is a pragmatic choice:
- Writes require 2 replicas -> better durability and propagation.
- Reads can be served from 1 replica -> low latency.
- Still available under 1 node failure.
But if you need stronger reads (less staleness), choose R=2, W=2 at a latency/availability cost.
Tail-latency note: W=2 means you wait for the second-fastest replica; if one replica is slow, you still might succeed quickly, but tail latency increases under load or GC pauses.
Key insight: Raising W improves write durability/visibility; raising R improves read freshness/consistency.
Versioning and Conflict Resolution (Because Quorum Isn’t Magic)
Scenario
Two clients write concurrently:
- Client 1 writes value X at replica A and B.
- Client 2 writes value Y at replica B and C.
With leaderless replication, both can “succeed” depending on timing.
Interactive question (pause and think)
If later a read queries A and C (R=2), what might it see?
Reveal
It might see X from A and Y from C. The coordinator must decide:
- choose one (LWW)
- return both (siblings) and force application-level merge
- merge automatically (CRDT)
“Quorum gives you evidence, not truth”
A quorum read gives you a sample of replicas. If they disagree, you need a merge rule.
Key insight: In leaderless systems, correctness is a combination of quorum + versioning + reconciliation.
Production caveat: vector clocks can grow with the number of writers; many systems prune/compact them, which can reintroduce ambiguity.
“Read Repair Fixes Everything Immediately”
Misconception
If you do read repair, replicas will quickly become consistent.
Reality
Read repair only runs on reads, and only for keys that are accessed.
Cold keys can remain inconsistent for a long time unless you run:
- background anti-entropy
- periodic full repairs
Key insight: Read repair is opportunistic; anti-entropy is systematic.
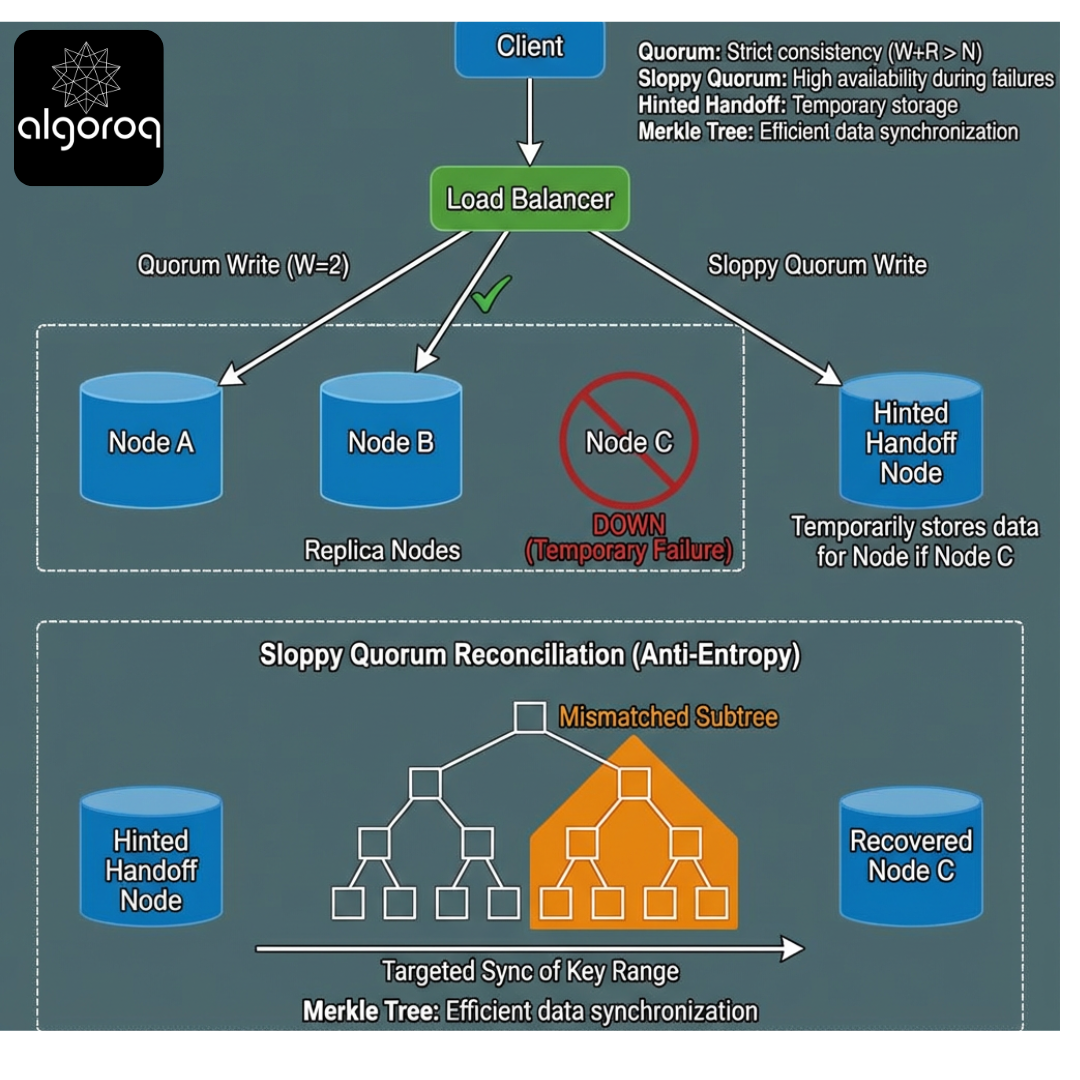
Anti-Entropy and Merkle Trees (Why Repair Scales)
Scenario
Two replicas may diverge across millions of keys. You can’t compare everything key-by-key each time.
How it works
A Merkle tree hashes ranges of keys:
- If root hashes match -> data in that range matches (with high probability)
- If not -> compare children hashes and recurse
Interactive question (pause and think)
Why is this better than scanning all keys?
Reveal
Because you transfer O(changed ranges) metadata instead of O(total keys) data.
Key insight: Sloppy quorum needs scalable repair; Merkle trees make divergence detection efficient.
Pick the Best Strategy
Scenario
You operate a multi-region store with occasional inter-region partitions.
You must choose one:
- Strategy A: Classic quorum across regions (writes require W across WAN)
- Strategy B: Sloppy quorum within region + async cross-region replication
Which statement is true?
- A always gives lower latency.
- B usually gives lower latency and higher availability, but weaker cross-region consistency.
- A and B have identical failure behavior.
Reveal
2 is true.
- WAN quorums add latency and reduce availability.
- Regional sloppy quorum keeps service alive locally but accepts eventual convergence across regions.
Key insight: Quorum scope (intra-DC vs inter-DC) is as important as R/W values.
Concrete Walkthrough — N=3, W=2, R=2 With and Without Sloppiness
Setup
Replicas for key K: A, B, C.
Step 1: Normal write
Client writes v1.
- Coordinator sends to A, B, C.
- A and B ack quickly -> write succeeds (W=2).
- C is slow but eventually applies.
Challenge question: If C never applies, can reads still return v1?
Answer: With R=2, reads hitting A and B will return v1. But if A fails and reads hit B and C (where C is stale), you may see divergence; versioning helps.
Step 2: C is down
Client writes v2.
- Classic quorum: need 2 acks from {A,B,C}. If A and B up, ok.
- Sloppy quorum: same outcome here; no need for fallback.
Step 3: B is down, C is down
Only A is reachable.
- Classic quorum with W=2 -> write fails.
- Sloppy quorum -> coordinator writes to A and fallback D, gets 2 acks, succeeds.
After healing, which replicas are “authoritative” for K?
A and D have v3; B and C may have v2 or v1. Repair must move v3 to B and C and possibly delete temporary copy on D.
Key insight: Sloppy quorum allows progress but can create temporary replica set expansion.
Trace the Read Path
Problem
N=3, R=2, sloppy quorum enabled.
Key K’s primaries: A,B,C.
A and B are up, C down.
A write is stored on A and fallback D (because B was briefly unreachable during write).
Now a read occurs and queries A and B.
Pause and think: What values might it see?
Reveal
- A has the new value.
- B might be stale.
Coordinator returns A’s value (newest version) and triggers read repair to B.
Follow-up challenge: What if read queries B and C (but C is down) and times out?
- If it can’t reach R=2, it may fail or degrade depending on configuration.
Key insight: Even with sloppy quorum, reads still have quorum thresholds - unless you also make reads sloppy.
Sloppy Reads? (Yes, Sometimes)
Scenario
Some systems also allow reads to be served from fallback nodes if primaries are unavailable.
This can increase availability but makes it harder to reason about freshness.
Interactive question (pause and think)
If you read from a fallback node, what is the biggest risk?
Reveal
You might read a value that:
- never made it back to primaries (hint lost)
- is a divergent sibling
- is older/newer than what primaries would return
Key insight: Sloppy reads trade correctness for availability even more aggressively than sloppy writes.
The Subtle Part — What Does “W Acks” Mean?
Scenario
Replica receives a write.
Possible ack semantics:
- Ack after writing to in-memory memtable
- Ack after appending to WAL
- Ack after fsync WAL to disk
- Ack after applying to SSTable and compaction (rare)
Interactive question (pause and think)
Which ack semantics are compatible with “W gives durability”?
Reveal
You need at least (2) or (3), depending on how you define durability.
- If you care about crash safety on power loss, (3) matters.
- If you accept losing the last few milliseconds/seconds on crash, (2) may be acceptable.
Key insight: Quorum numbers are meaningless without precise durability semantics.
Real-World Usage Patterns
Dynamo-style systems (Riak, Cassandra-inspired designs)
- Leaderless replication
- Tunable consistency: choose R/W per request
- Sloppy quorum to remain available during node outages
- Hinted handoff + read repair + anti-entropy
Cassandra specifics (high-level)
- Replication factor per keyspace
- Consistency levels like ONE, QUORUM, LOCAL_QUORUM
- Hinted handoff exists but is bounded/controlled
Interactive question (pause and think)
Why do these systems often default to LOCAL_QUORUM in multi-DC deployments?
Reveal
To avoid WAN latency and partitions affecting availability. You get stronger consistency within a DC and eventual across DCs.
Key insight: “Quorum” is often scoped: local quorum is a pragmatic compromise.
“Quorum Writes Prevent Lost Updates”
Misconception
If W is a quorum, updates can’t be lost.
Reality
Lost updates can still happen due to:
- concurrent writes with LWW (last write wins) overwriting
- clock skew if timestamps decide winners
- coordinator retries causing reordering
Preventing lost updates requires:
- compare-and-set (CAS)
- conditional writes with version checks
- CRDTs or application merges
Key insight: Quorum is about replication overlap, not application-level concurrency control.
Clock Skew and LWW
Question
In a leaderless quorum system using LWW timestamps, two clients write concurrently:
- Client A’s clock is 5 minutes ahead.
- Client B writes later in real time but with a smaller timestamp.
Pause and think: Which value will “win”?
Reveal
Client A’s value may win incorrectly, causing a lost update.
Mitigations:
- use hybrid logical clocks (HLC)
- use server-assigned timestamps
- avoid LWW for critical merges
Key insight: Version comparison is a correctness lever just as important as R/W.
Designing With Quorums — A Checklist
When you say “we use quorum,” you must specify:
- Replication model: leaderless vs leader-based
- Replica selection: fixed set vs sloppy fallback
- Ack semantics: memory vs WAL vs fsync
- Versioning: LWW, vector clocks, HLC, etc.
- Conflict handling: return siblings, merge, CRDT
- Repair: read repair, hinted handoff, anti-entropy
- Timeout policy: what happens when quorum can’t be met
- Client semantics: retries, idempotency, write IDs
Key insight: “Quorum” is a family of design choices, not a single feature.
Run the Neighborhood Coffee Chain
The game
You operate a 5-node cluster (N=5) storing loyalty points.
- Target: 99.99% availability for writes
- Reads should be “usually fresh” within 2 seconds
- Network partitions happen
- You can tolerate occasional conflict resolution, but not frequent customer-visible rollbacks
Your tasks
1) Choose parameters
Pick N, R, W and whether you enable sloppy quorum.
Pause and think: What do you pick and why?
2) Handle this failure
A partition isolates 2 nodes with 60% of your clients. The other 3 nodes are healthy.
- Do you allow writes on the 2-node side?
- If yes, where do they go?
3) Reconciliation plan
When partition heals, how do you ensure:
- all loyalty updates converge
- customers don’t lose points
Progressive reveal (one possible strong answer)
- Parameters:
- N=5 (replication factor)
- W=3 (durable propagation)
- R=1 or R=2 (latency vs freshness)
- Enable sloppy quorum for writes
- During partition:
- On the 2-node side, classic quorum W=3 would block writes.
- With sloppy quorum, accept writes by writing to the 2 reachable nodes plus fallback nodes reachable in that partition.
- Reconciliation:
- Use write IDs for idempotency.
- Use HLC or vector clocks to detect concurrent updates.
- Prefer additive CRDT for loyalty points (e.g., G-Counter / PN-Counter) to avoid lost updates.
- Run anti-entropy plus hinted handoff.
Challenge questions (answer in your own words)
- If you must avoid lost updates, why is LWW a risky choice for loyalty points?
- What operational signals tell you hinted handoff is falling behind?
- If you raise W from 3 to 4, what happens to availability during a 2-node outage?
- In what scenario does sloppy quorum increase tail latency?
Key insight: Quorum is a knob; sloppy quorum is an availability escape hatch; correctness comes from the whole stack: durability + versioning + merge + repair.
What You Should Be Able to Explain After This Article
- Why R + W > N creates intersection, and what assumptions it hides
- How leaderless quorum systems differ from consensus-based quorums
- What sloppy quorum changes (membership) and why it needs repair
- How hinted handoff, read repair, and anti-entropy work together
- Which failure scenarios break naive quorum reasoning
Appendix: Quick Reference
- N: replication factor
- W: write acknowledgements required
- R: read responses required
- Classic quorum: write/read only to the key’s replica set
- Sloppy quorum: write/read may use fallback nodes when primaries unavailable
- Hinted handoff: temporary storage + later delivery to intended replica
- Anti-entropy: background reconciliation (often Merkle-tree based)
Key Takeaways
- Quorum requires W+R > N for strong consistency — ensuring at least one node overlaps between reads and writes
- Sloppy quorum writes to any N available nodes, not specific replicas — improving availability at the cost of consistency guarantees
- Hinted handoff stores writes temporarily on nearby nodes — forwarding them to the correct replica when it recovers
- DynamoDB and Cassandra use sloppy quorum with hinted handoff — prioritizing availability and partition tolerance (AP systems)