Gossip Protocols

Gossip Protocol (Epidemic Dissemination)
Audience: advanced distributed systems engineers
Your cluster needs “word of mouth” communication
You are on call for a service running 10,000 nodes across multiple regions. Membership is dynamic: nodes come and go, networks partition, and failures are messy.
You need answers to questions like:
- Which nodes are alive right now?
- How do we spread configuration changes or feature flags quickly?
- How do we do this without a centralized coordinator that becomes a bottleneck or single point of failure?
A teammate proposes: “Let’s use a gossip protocol. It’s like how rumors spread in a coffee shop.”
Pause and think:
- What do you expect gossip to be good at?
- What do you expect it to be bad at?
We will build a rigorous mental model, then pressure-test it with failure scenarios, trade-offs, and real-world patterns.
[KEY INSIGHT] Gossip protocols trade strong consistency for scalability and resilience: information spreads probabilistically with bounded overhead per node, converging eventually under reasonable assumptions.
0 — Network + failure model assumptions (state them explicitly)
Gossip designs are only “correct” relative to assumptions. For this article we assume:
- Crash faults (nodes can stop, restart, pause), not Byzantine behavior by default.
- Asynchronous network: unbounded delay, reordering, duplication, and loss are possible.
- Partitions happen: the communication graph may become disconnected.
- Eventual connectivity (for eventual convergence): partitions heal and the graph becomes connected “often enough.”
If you violate these (e.g., adversarial nodes, permanent partitions), you must add additional mechanisms.
1 — What is Gossip, really?
Scenario
You are in a busy cafe. You learn that the espresso machine is broken. You tell two people. Each of them tells two more. Soon, most people know, without any announcement system.
That is the essence of gossip: periodic, pairwise exchanges of information that cause epidemic spread.
Interactive question (pause and think)
If each person tells exactly 2 new people per minute, how fast does the news spread?
- A) Linear (adds 2 people per minute)
- B) Exponential (multiplies)
- C) Does not spread reliably
Pause and think.
Progressive reveal — Answer
B) Exponential, at least initially, until you saturate the population and repeats dominate.
In distributed systems, this exponential early spread is why gossip can disseminate updates quickly even at large scale.
Explanation with analogy
- People = nodes
- Rumor = state update (membership, config, metrics)
- Conversation = gossip round (push/pull)
- Repeats = redundant messages (inevitable)
[KEY INSIGHT] Gossip is not broadcast. It is many small exchanges that collectively approximate broadcast, without central coordination.
Challenge question
If gossip spreads exponentially early on, why does it not melt your network at 10,000 nodes?
(We will answer with bounded per-node fanout and fixed periodicity.)
2 — The core promise: scalable dissemination with bounded cost
Scenario
You need to propagate a “node X is suspected dead” event. You could:
- Have node X report to a central registry (but X is dead)
- Have all nodes ping all nodes (O(n^2) madness)
- Use gossip: each node talks to a few peers periodically (O(n) total traffic)
Interactive question (pause and think)
Which is the key scaling property of gossip?
- A) Total messages per round stays constant
- B) Messages per node per round stays constant
- C) Messages per node per round decreases as cluster grows
Pause and think.
Progressive reveal — Answer
B) Messages per node per round stays constant.
In typical gossip, each node contacts k peers per interval (k is small, like 1–5). So traffic per node is bounded; total traffic scales linearly with n.
[KEY INSIGHT] Gossip scales because each node does constant work, and the system’s capacity grows with the number of nodes.
Production insight: “bounded” must be enforced
In real systems, “bounded per node” requires explicit limits:
- Max bytes per message (MTU-aware)
- Max updates piggybacked per round
- Backpressure when CPU/network is saturated
- Fairness so one hot node doesn’t dominate dissemination
3 — Three gossip flavors: push, pull, push-pull
Scenario
Two baristas exchange updates:
- Barista A: “I will tell you what I know.” (push)
- Barista B: “Tell me what you know.” (pull)
- Both: “Let’s swap.” (push-pull)
Decision game: Which statement is true?
- Push gossip is best when most nodes already know the update.
- Pull gossip is best when most nodes already know the update.
- Push-pull is always strictly better than both.
Pause and think.
Progressive reveal — Answer
- Pull gossip is best when most nodes already know the update.
- Push is efficient early: few informed nodes can infect many uninformed nodes.
- Pull is efficient late: uninformed nodes actively seek missing info.
- Push-pull often performs well across phases, but can cost more per exchange (bigger payloads or more metadata).
Comparison table
| Mode | How it works | Best phase | Common downside |
|---|---|---|---|
| Push | Informed nodes send updates | Early (few informed) | Wastes messages late (push to already-informed) |
| Pull | Nodes ask peers for what they are missing | Late (many informed) | Slow early if nobody knows anything |
| Push-Pull | Exchange summaries plus missing updates | Broadly good | More complex; bigger exchanges |
Push vs Pull vs Push-Pull (ASCII)
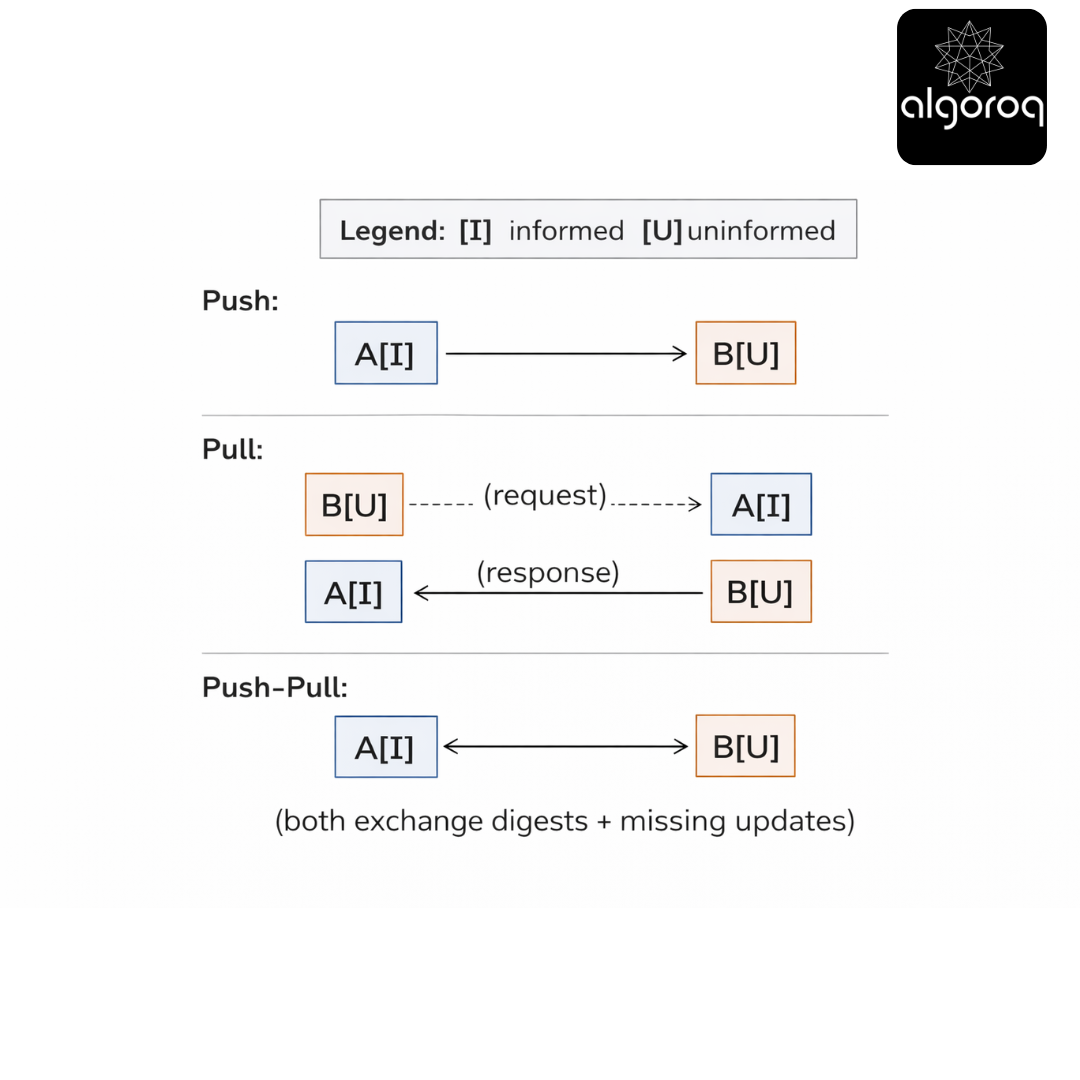
[KEY INSIGHT] Push is broadcasting, pull is subscribing, push-pull is syncing. The best choice depends on what fraction of nodes already have the info.
4 — What exactly is being gossiped? State, deltas, and summaries
Scenario
In the cafe, people do not repeat the entire history of everything they have heard. They exchange:
- The latest news and
- Sometimes a quick summary (“here is what changed since you arrived”).
In systems, gossip payloads tend to be one of:
- State-based: send full state (or a large subset)
- Delta-based: send only changes since last time
- Digest/summaries: send compact metadata first, then fetch missing parts
Interactive matching exercise
Match each approach to its best fit:
A) State-based B) Delta-based C) Digest plus fetch
Use-cases:
- Small cluster or small state; simplest correctness
- High churn updates; bandwidth-sensitive; needs ordering/versioning
- Large state; want bounded per-round size; tolerate extra round trips
Pause and think.
Progressive reveal — Answer
- A -> 1
- B -> 2
- C -> 3
[KEY INSIGHT] The payload strategy determines bandwidth, convergence speed, and complexity. Digest-based designs are common for large-scale membership and anti-entropy.
Clarification: why delta-only is riskier under loss
Delta-only designs can permanently miss an update if:
- the delta message is lost, and
- there is no later full-state reconciliation, and
- the receiver has no way to detect the gap.
This is why production systems typically combine rumor mongering (deltas) with anti-entropy (state/digest reconciliation).
5 — Membership gossip: failure detection and cluster view
Scenario
Your service needs a membership list: which nodes should receive traffic, hold shards, or participate in consensus.
But nodes fail in messy ways:
- Crash-stop
- CPU stall / GC pause
- Network partition
- Asymmetric reachability (A can reach B; B cannot reach A)
Gossip-based membership systems (e.g., SWIM-style) often combine:
- Failure detection: suspicion based on missed probes
- Dissemination: gossip of suspicion/confirmation
Interactive question (pause and think)
If node A cannot reach node B, is B necessarily dead?
- A) Yes
- B) No
Pause and think.
Progressive reveal — Answer
B) No.
You cannot distinguish failure from partition reliably in an asynchronous network.
[KEY INSIGHT] Membership gossip usually provides eventual agreement on reachability suspicion, not perfect truth.
Production insight: define what “alive” means
Many incidents come from mixing semantics:
- Process alive (PID exists)
- Node reachable (network path works)
- Node healthy (can serve requests)
Gossip membership typically answers “reachable enough to communicate,” not “healthy to serve.” For serving traffic, pair gossip with health checks and load balancer feedback.
6 — SWIM-style gossip: probe, indirect probe, suspicion
Scenario
You run a buddy check system in the cafe:
- Every interval, you pick one random person and ask “Are you okay?”
- If they do not respond, you ask a few other people to check on them.
- If still no response, you tell others “I suspect they left.”
That is the shape of SWIM (Scalable Weakly-consistent Infection-style Membership).
SWIM probe sequence
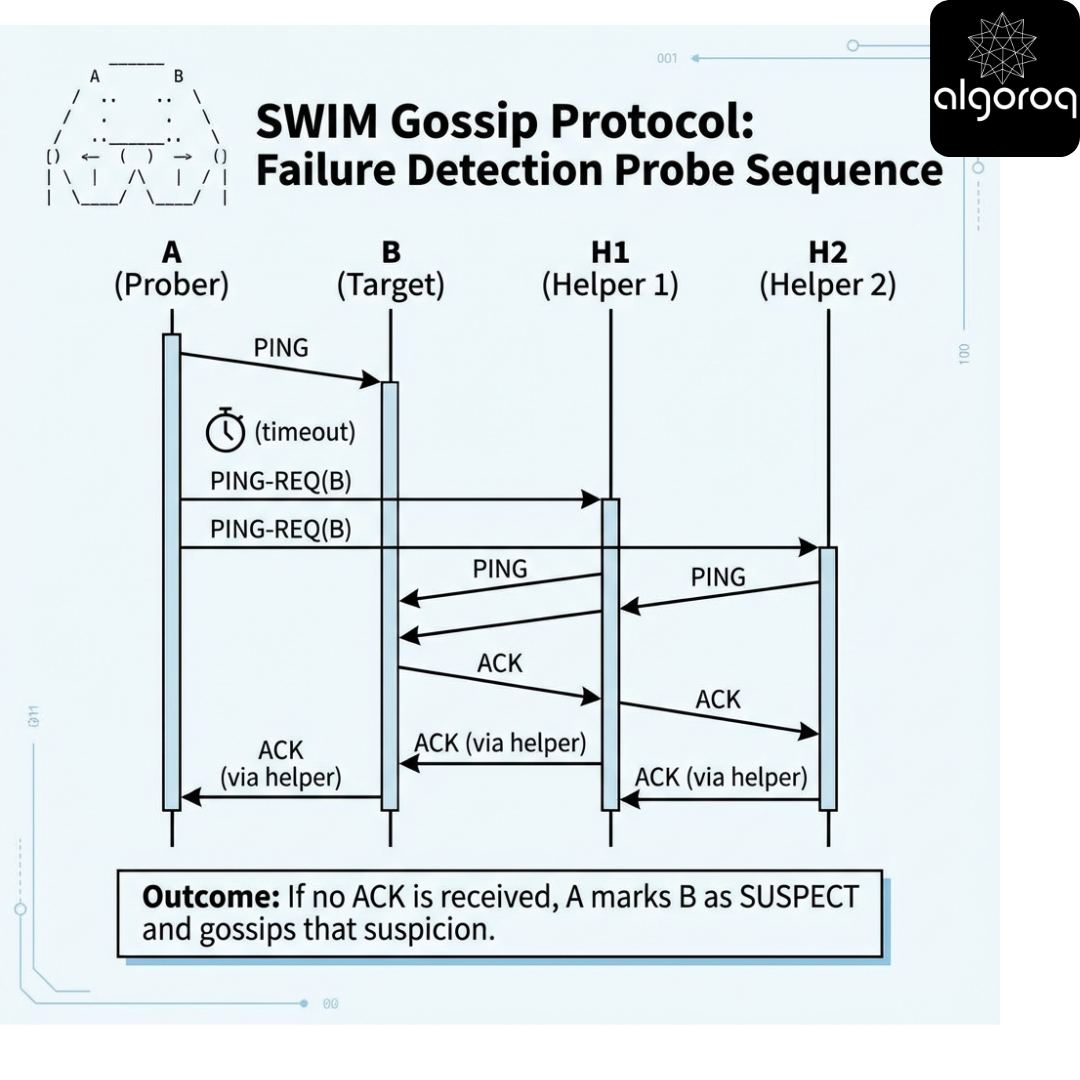
Interactive decision game
Which mechanism reduces false positives during transient packet loss?
- Randomized probing
- Indirect probing (ping-req)
- Piggybacking membership updates on probes
Pause and think.
Progressive reveal — Answer
- Indirect probing (ping-req).
If A cannot reach B due to a transient issue on A’s path, helpers might still reach B, preventing a false suspicion.
Failure scenario: GC pauses and stop-the-world
A 2s GC pause can look like a failure if:
- probe interval is small (e.g., 200ms)
- timeouts are aggressive
- suspicion timeout is short
Mitigations:
- set timeouts based on p99 latency + jitter
- use indirect probes
- use suspicion timeouts that scale with cluster size (SWIM does this)
- optionally integrate local “I’m pausing” signals (best-effort) to reduce false positives
7 — Failure scenarios: partitions, churn, and correlated loss
Scenario
A region link degrades. Packet loss spikes to 20%. Latency doubles. Some nodes pause due to GC.
Gossip assumes random mixing over time. What happens when failures are correlated?
- Many nodes behind the same ToR switch
- A whole AZ becomes unreachable
- A common dependency (DNS, NTP, cert service) fails
Interactive question (pause and think)
Which is more dangerous for gossip convergence?
- A) Independent random packet loss (each message drops with p)
- B) Correlated loss / partitions (whole groups cannot talk)
Pause and think.
Progressive reveal — Answer
B) Correlated loss / partitions.
Independent loss slows convergence but does not fundamentally break connectivity. Partitions create disconnected components: gossip cannot cross them.
[KEY INSIGHT] Gossip needs a connected communication graph over time. Partitions create divergent truths that only reconcile after healing.
Partition + healing timeline
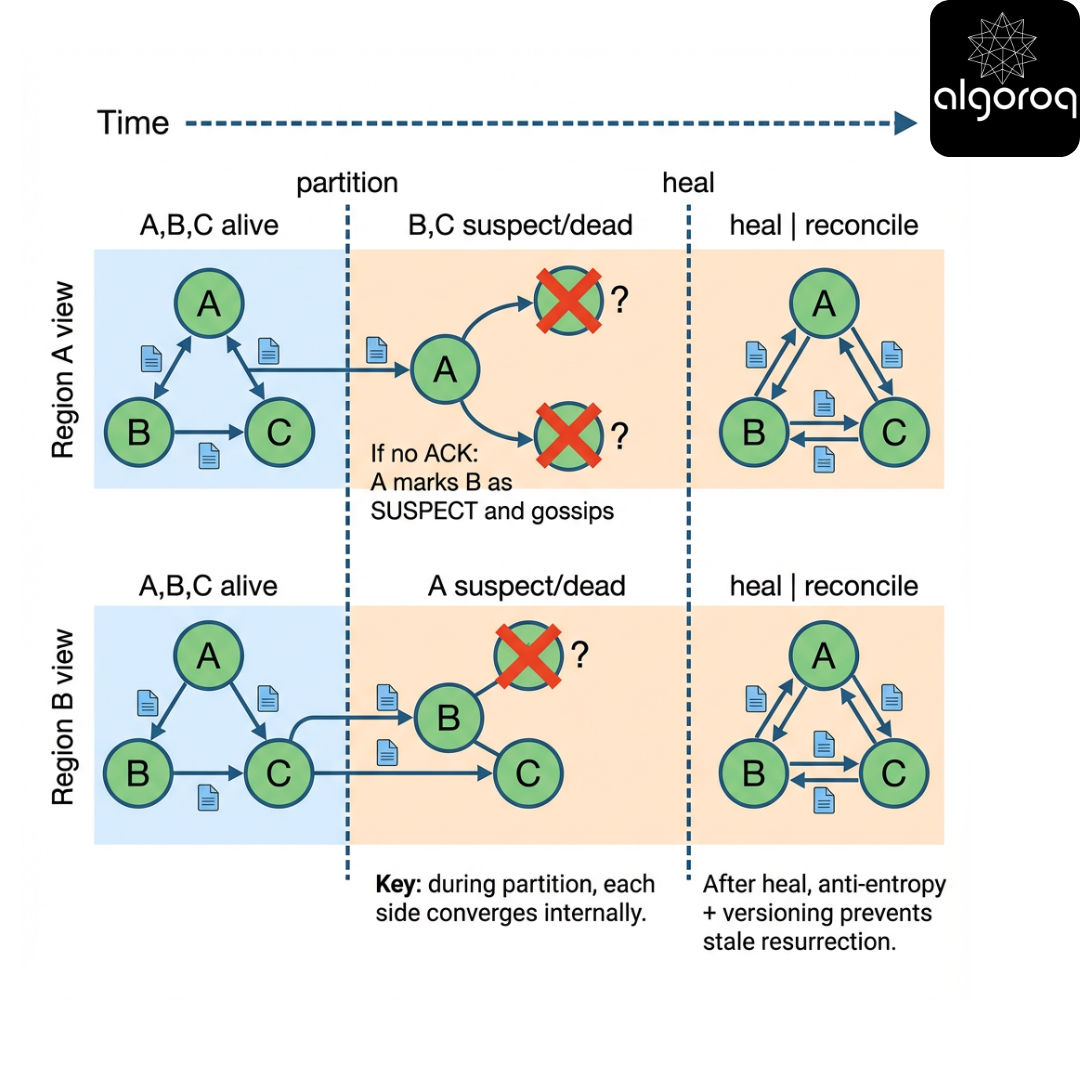
Production insight: correlated peer selection matters
If peer selection is “random” but actually biased (same rack/AZ), you can get:
- slow cross-AZ convergence
- blind spots during partial network failures
Mitigation: topology-aware randomization (e.g., choose peers across racks/AZs with weighted sampling).
8 — Mental model: Gossip as anti-entropy + probabilistic broadcast
Scenario
Imagine every node holds a notebook of facts. Over time, notebooks drift due to missed messages and failures.
Gossip is a periodic anti-entropy process:
- pick a peer
- compare summaries
- exchange missing updates
Interactive question
Which is the best mental model?
- Gossip is a replacement for consensus
- Gossip is a replacement for TCP
- Gossip is a background reconciliation mechanism
Pause and think.
Progressive reveal — Answer
- Gossip is a background reconciliation mechanism.
Gossip does not give you linearizability. It provides eventual convergence under assumptions (connectivity, bounded loss, enough rounds).
[KEY INSIGHT] Treat gossip as eventual and approximate. If you need strong agreement, pair it with consensus or quorum mechanisms.
CAP framing (important nuance)
- Gossip-based membership is typically AP under partition: each partition continues operating with its local view.
- You cannot have both perfect global membership agreement (C) and availability (A) during a partition (P).
Most systems choose availability and accept that membership is a hint that may be wrong temporarily.
9 — Decision game: When should you use gossip?
Scenario
You are choosing a dissemination mechanism for:
- membership
- feature flags
- schema versions
- cache invalidations
- security revocations
Decision game: Which statement is true?
A) Gossip is ideal for must-deliver security revocations.
B) Gossip is ideal for disseminating approximate metrics (like load averages).
C) Gossip is ideal for totally ordered event streams.
Pause and think.
Progressive reveal — Answer
B is true.
- Security revocations often require stronger guarantees (or at least bounded delay plus acknowledgement).
- Totally ordered streams require ordering/consensus.
- Approximate metrics are a perfect fit: eventual and probabilistic is fine.
Comparison table: gossip vs alternatives
| Goal | Gossip | Central registry | Pub/Sub | Consensus log |
|---|---|---|---|---|
| Membership at scale | Yes | Bottleneck risk | Needs infra | Expensive |
| Strong consistency | No | No/limited | Sometimes | Yes |
| Low per-node overhead | Yes | Yes | Sometimes | No |
| Works during partial failures | Degrades gracefully | No | Depends | Depends |
| Deterministic delivery | No | Sometimes | Yes | Yes |
[KEY INSIGHT] Gossip shines when eventual is acceptable, scale is high, and failures are routine.
10 — Convergence math intuition (without drowning in equations)
Scenario
You have 10,000 nodes. An update starts at 1 node. Each round, each informed node contacts 1 random peer and pushes the update.
Pause and think:
Roughly how many rounds until almost everyone knows?
- A) O(n)
- B) O(log n)
- C) O(log log n)
Pause and think.
Progressive reveal — Answer
B) O(log n) rounds for the bulk spread in the idealized push model, though constants and late-phase effects matter.
Clarification: tail behavior dominates SLOs
Even if median convergence is fast, the last 1% can take much longer due to:
- repeated contacts to already-informed peers
- partitions / correlated loss
- bounded payloads (you may not ship all updates each round)
This is why production systems use push-pull and anti-entropy.
11 — Versioning: timestamps, incarnation numbers, and rumor resurrection
Scenario
A node crashes and restarts. Old gossip says it is dead. New gossip says it is alive. Who wins?
If you do not version membership events, you can get:
- Resurrection bugs: dead nodes come back alive due to stale messages
- Flapping: alternating ALIVE/DEAD rumors
Interactive question
What metadata prevents stale membership messages from overriding newer truth?
- Wall-clock timestamps
- Monotonic incarnation/epoch numbers per node
- Random UUIDs per message
Pause and think.
Progressive reveal — Answer
- Monotonic incarnation/epoch numbers per node.
Wall clocks drift; timestamps can go backward. Incarnation numbers increase each time a node restarts (or each membership epoch), allowing deterministic conflict resolution:
- For a given node ID, higher incarnation wins.
Production detail: status precedence + incarnation
In SWIM-like designs, conflict resolution is typically:
- Compare incarnation (higher wins)
- If equal incarnation, compare status precedence (e.g., DEAD > SUSPECT > ALIVE) or use a status-specific version.
Be explicit; otherwise you can accept an “ALIVE” that incorrectly overrides a “DEAD” at the same incarnation.
[KEY INSIGHT] Use monotonic versioning (incarnation/epoch) to make gossip conflict resolution deterministic and resilient to reordering.
12 — Rumor mongering vs anti-entropy
Scenario
Two strategies for spreading updates:
- Rumor mongering: aggressively spread hot rumors for a short time
- Anti-entropy: periodically reconcile full state/digests forever
Interactive matching
Match to properties:
A) Rumor mongering B) Anti-entropy
Properties:
- Fast initial spread, but may miss some nodes
- Ensures eventual convergence even after missed messages
- Often uses periodic full/digest sync
Pause and think.
Progressive reveal — Answer
- A -> 1
- B -> 2 and 3
[KEY INSIGHT] If you only do rumor mongering, you risk permanent divergence. Anti-entropy provides the eventual in eventual consistency.
Clarification: “worst-case convergence” is unbounded without assumptions
If partitions can last arbitrarily long, worst-case convergence time is unbounded.
Under an operational assumption like “partition heals within 5 minutes” and anti-entropy runs every 60s, then post-heal repair is typically within O(anti-entropy interval) plus a few rounds.
13 — Real-world usage patterns
Gossip often carries control-plane information, not the main data plane.
Common patterns:
- Cluster membership and failure detection: SWIM-based systems, service discovery sidecars
- Replication metadata dissemination: e.g., “who owns which shard” (eventually)
- Distributed caching: approximate invalidations, peer discovery
- Monitoring/telemetry: aggregating approximate counts, sketches, top-k
[KEY INSIGHT] Gossip is a versatile control-plane mechanism: discovery, liveness hints, configuration hints, and approximate aggregates.
14 — Trade-offs: consistency, overhead, and tail latency
Scenario
Your product manager asks: can you guarantee all nodes get the update within 5 seconds?
With gossip, you can often provide high probability delivery, but not strict guarantees without extra mechanisms.
Interactive question
Which trade-off triangle best describes gossip?
- A) Strong consistency, low overhead, high scalability
- B) Eventual consistency, bounded overhead, high scalability
- C) Strong consistency, bounded overhead, high scalability
Pause and think.
Progressive reveal — Answer
B) Eventual consistency, bounded overhead, high scalability.
Performance considerations (what actually costs you)
- Bandwidth: redundancy is intrinsic; tune fanout and payload caps.
- CPU: serialization + digest comparison can dominate at large membership sizes.
- Tail latency: last-mile convergence is the hard part.
- GC pressure: avoid allocating large transient maps per round.
[KEY INSIGHT] Gossip optimizes for system-level robustness over per-message determinism.
15 — Hybrid designs: gossip plus something stronger
You often want:
- gossip for scalable dissemination
- stronger mechanisms for correctness-critical operations
Common hybrids:
-
Gossip + consensus
- consensus log records authoritative membership/config
- gossip spreads the latest committed view quickly
-
Gossip + directory
- directory provides bootstrap and occasional correction
- gossip handles steady-state changes
-
Gossip + explicit repair
- nodes detect missing updates and request them directly
Decision game
Which hybrid is most appropriate for security revocation?
A) Gossip plus consensus (authoritative) B) Gossip only C) Gossip plus approximate anti-entropy (no authority)
Pause and think.
Progressive reveal — Answer
A) Gossip plus consensus.
Security revocations need an authoritative source of truth and auditability. Gossip can be the distribution layer, but not the decision layer.
Failure mode that remains even with gossip + consensus
Even with an authoritative store, you can still have:
- stale caches at nodes that can’t reach the authority during a partition
- split-brain serving if you choose “fail open” for availability
You must decide policy: fail open vs fail closed (see Section 22).
16 — Tuning knobs: interval, fanout, suspicion timeouts
Key knobs:
- Probe interval (how often each node probes)
- Fanout k (how many peers per round)
- Timeouts (how long to wait for ack)
- Suspicion timeout (how long before declaring dead)
- Payload limits (how many updates piggybacked)
Interactive question
What happens if you decrease probe interval aggressively?
- A) Faster detection, more network overhead, more false positives under transient latency
- B) Faster detection, less overhead
- C) No real change
Pause and think.
Progressive reveal — Answer
A).
Production insight: failure detection is a control system
Aggressive tuning can create positive feedback loops:
- more probes -> more load -> higher latency/loss -> more suspicions -> more gossip traffic -> more load
Mitigations:
- adaptive timeouts (based on observed RTT distributions)
- rate limiting suspicion dissemination
- separate “probe traffic” from “bulk anti-entropy” traffic
17 — Security and adversarial considerations
Scenario
In a multi-tenant environment, a malicious node could:
- claim other nodes are dead
- flood gossip with bogus updates
- cause membership churn and instability
Gossip assumes mostly honest participants. In adversarial settings you need:
- authentication of messages (mTLS, signatures)
- authorization (who can claim what)
- rate limiting
- Sybil resistance (hard)
Threat model (ASCII)
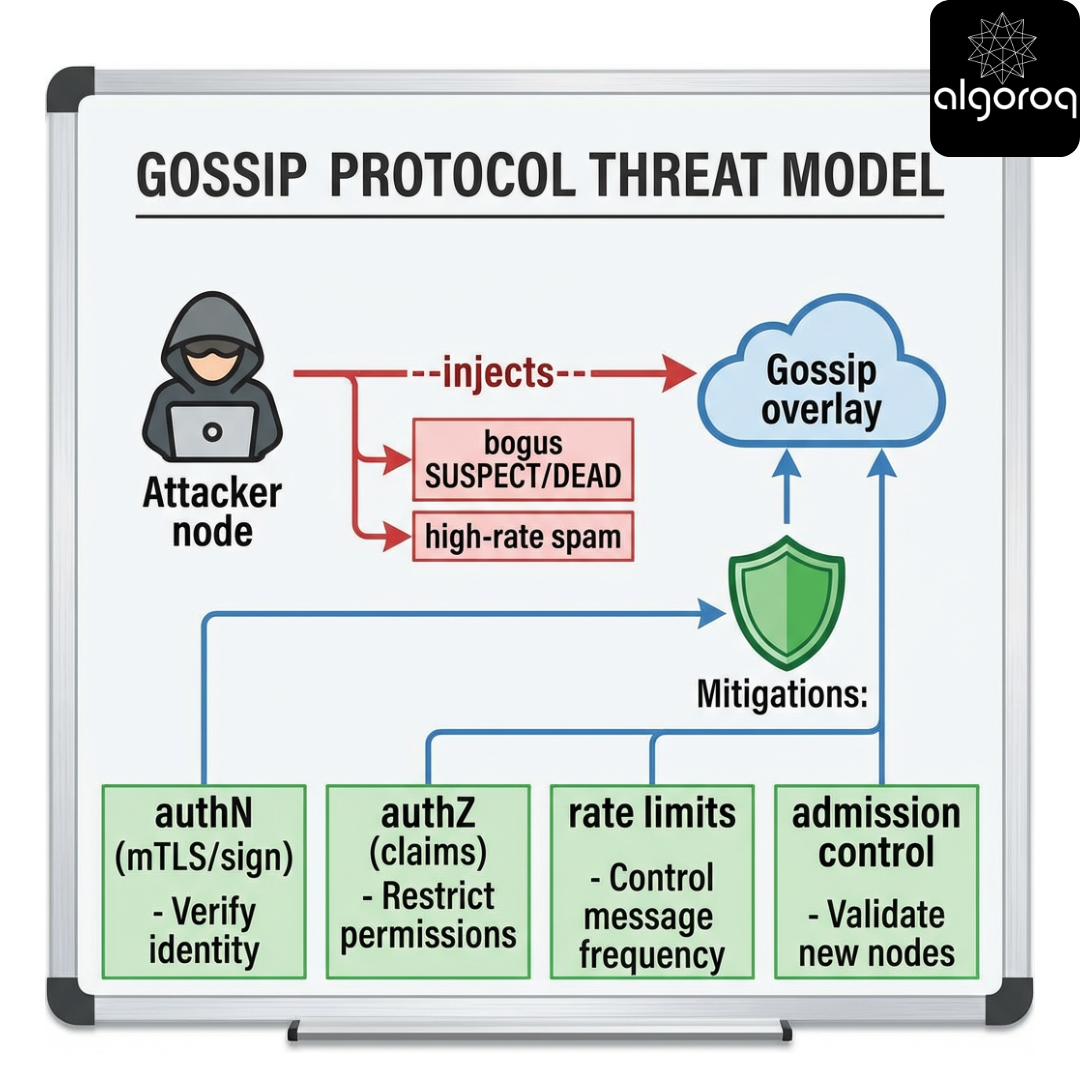
Operational risk introduced by signing
If you sign gossip messages, you introduce:
- key distribution/rotation complexity
- risk of clock/nonce mistakes if you add replay protection
- risk of CPU overhead (sign/verify) becoming the bottleneck
[KEY INSIGHT] Gossip protocols are typically designed for crash-fault tolerance, not Byzantine behavior. Add cryptographic and operational controls if the environment is hostile.
18 — Implementation sketch: a minimal gossip membership loop (corrected)
This section intentionally stays “minimal,” but the code must still be correct about:
- request/response correlation (UDP is unordered)
- bounded payloads
- conflict resolution (incarnation + status precedence)
- timeouts and error handling
Design sketch
- Each node maintains: nodeID -> {status, inc, ts}
- Periodically select random peers
- Exchange digests and reconcile (push-pull)
- (Optional) separate SWIM probing from anti-entropy; here we focus on dissemination.
Digest + delta exchange
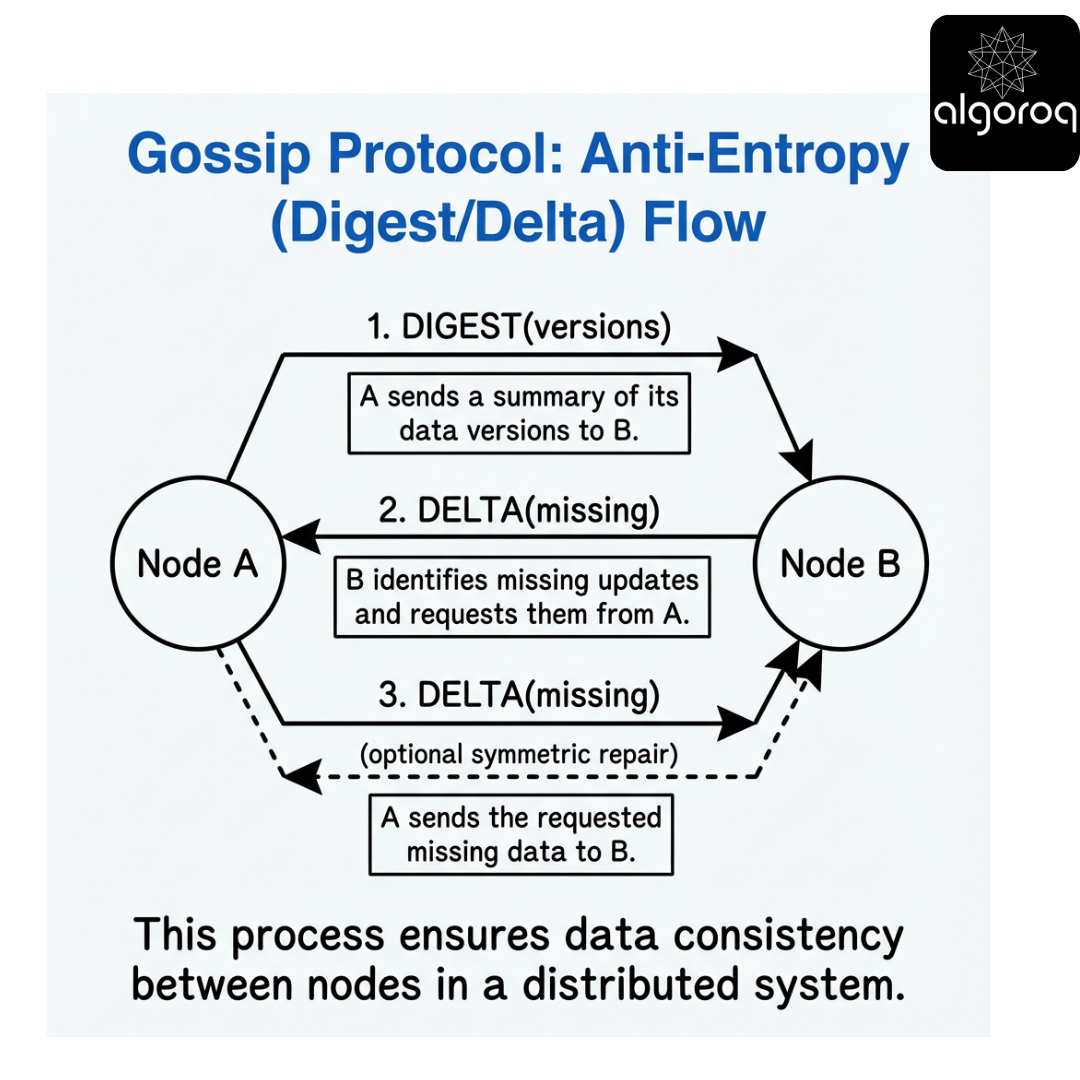
Status precedence
For equal incarnation, use precedence:
DEAD > SUSPECT > ALIVE
This prevents a stale ALIVE from overriding a DEAD at the same incarnation.
[CODE] Python: UDP push-pull digest with correlation + bounded payload
Notes on what this code still omits (intentionally):
- No SWIM probing (PING / PING-REQ) — this is dissemination only.
- No chunking protocol for large deltas (we truncate). Production systems implement chunking.
- No peer discovery / bootstrap.
- No encryption/authentication.
[CODE] JavaScript (Node.js): UDP digest + delta with correlation and payload cap
Interactive pause and think
Before looking at code, answer:
- What is the minimal information a digest must include to detect divergence?
Pause and think.
Progressive reveal — Answer
A digest needs, per node entry:
- nodeID
- incarnation/version
- status (or status version / precedence)
Often you can compress this (hashes, bloom filters), but conceptually you need enough to compare versions.
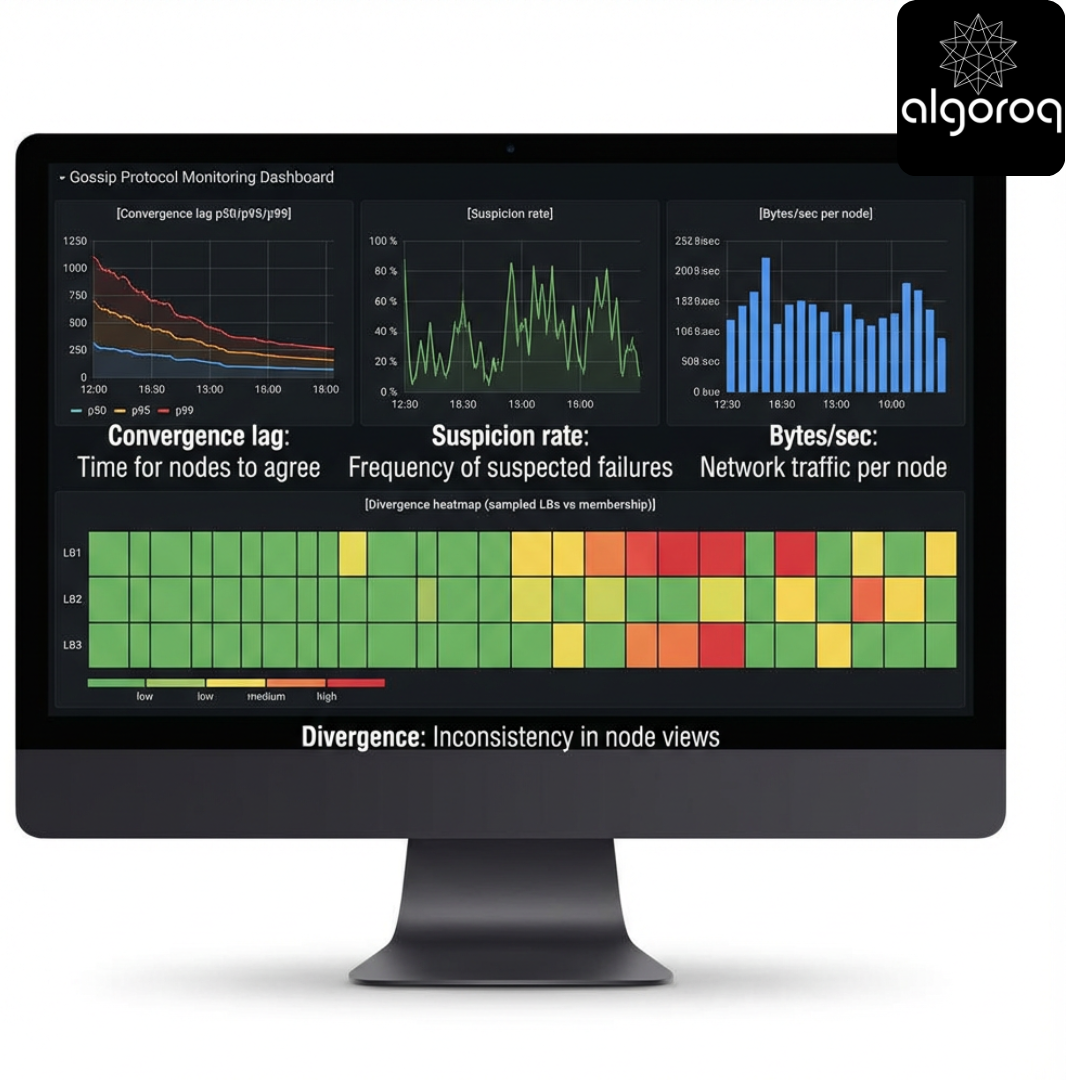
19 — Observability: how do you know gossip is working?
Scenario
A customer reports intermittent 503s. You suspect membership inconsistency: some nodes think an instance is alive, others do not.
What should you monitor?
- Convergence lag: time until update reaches X% of nodes
- Suspicion rate: SUSPECT events per minute
- False positive rate: nodes suspected but later confirmed alive
- Message volume: bytes per second per node
- Membership divergence: pairwise view differences (sampled)
Dashboard
Interactive decision game
Which metric is most directly tied to user-visible errors in load balancing?
A) Total gossip message count B) Membership divergence across load balancers C) CPU usage of gossip thread
Pause and think.
Progressive reveal — Answer
B) Membership divergence across load balancers.
Traffic routing correctness depends on who each load balancer believes is healthy.
How to sample divergence without O(n^2)
- Pick a small set of sentinel nodes (e.g., LBs) and compare their views.
- Compute a sketch/hash of the membership map (e.g., stable hash of sorted entries) and compare hashes.
- Sample random pairs periodically.
20 — Common misconceptions roundup
Common Misconception #1
“Gossip is eventually consistent, so it is always safe.”
Eventual consistency can be unsafe if you apply it to invariants requiring coordination (e.g., uniqueness, mutual exclusion).
Common Misconception #2
“If we increase fanout enough, gossip becomes reliable broadcast.”
Higher fanout improves probability and speed, but does not create acknowledgements, ordering, or deterministic delivery.
Common Misconception #3
“Gossip is random, so it is unpredictable.”
It is probabilistic, but you can model it and tune it. Many systems achieve stable behavior with correct parameters.
Common Misconception #4
“Gossip solves partitions.”
It does not. It adapts: each partition converges internally. Reconciliation requires healing plus anti-entropy.
[KEY INSIGHT] Gossip is a powerful primitive, but it is not a substitute for designing around partitions, versioning, and correctness boundaries.
21 — Interactive synthesis: design a gossip-based membership service
Scenario
You run a 3-region cluster (A, B, C), 2,000 nodes per region. Requirements:
- membership updates should converge to 99% of nodes within ~10 seconds under normal conditions
- tolerate 1 region partition for up to 5 minutes
- minimize false positives during GC pauses (up to 2 seconds)
- keep per-node bandwidth under 50 KB/s
Step 1 — Choose your gossip mode
- A) Push only
- B) Pull only
- C) Push-pull
Pause and think.
Answer reveal: Push-pull is usually the best default for membership because it handles both early and late phases and supports anti-entropy.
Step 2 — Choose versioning
- A) Wall-clock timestamps
- B) Incarnation numbers per node
Pause and think.
Answer reveal: Use incarnation numbers.
Step 3 — Handle partitions
- A) Immediately declare nodes in unreachable regions dead
- B) Use suspicion with longer timeouts and require multiple independent confirmations
Pause and think.
Answer reveal: B is safer. In partitions, dead is ambiguous; suspicion plus timeouts reduce catastrophic false positives.
Step 4 — Bound bandwidth
- A) Send full membership list every round
- B) Send digests and fetch missing entries; cap payload size
Pause and think.
Answer reveal: B.
[KEY INSIGHT] Production gossip systems are mostly about engineering constraints: versioning, bounded payloads, and carefully tuned failure detection.
Bootstrap (critical missing piece in many designs)
A brand-new node with no peers needs:
- a seed list (static config, DNS, or directory)
- a join protocol (often: contact seed -> get initial membership snapshot -> start gossip)
- protection against seed overload (rate limit, caching, multiple seeds)
22 — Final synthesis challenge (hard mode)
Scenario
You are tasked with designing dissemination for two kinds of information:
- Soft state: node load averages, queue depths (approximate OK)
- Hard state: node X is revoked and must not serve traffic (must be enforced quickly and reliably)
Constraints:
- 10,000 nodes
- multi-region
- partitions happen weekly
- low operational complexity
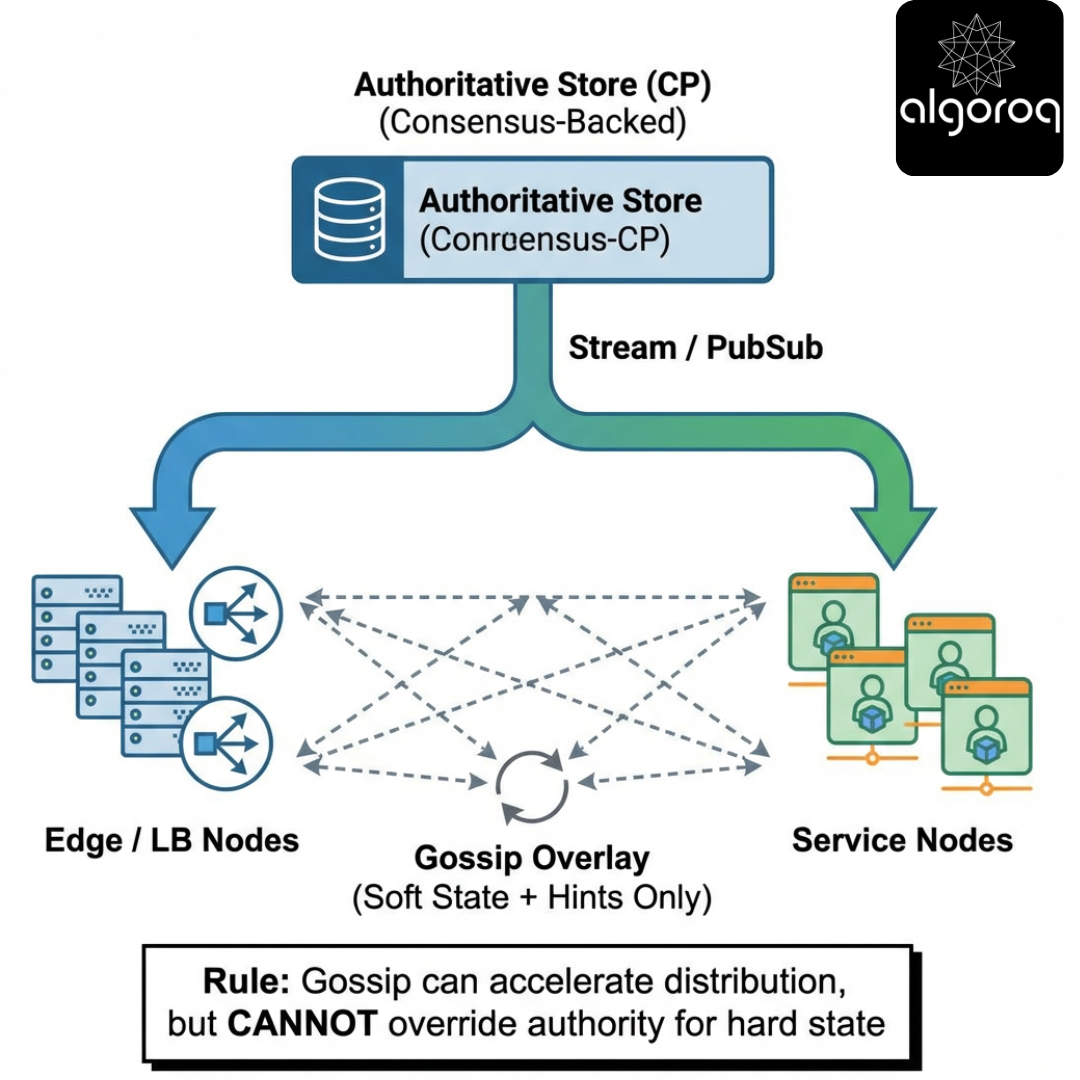
One strong solution
- Soft state: gossip periodically (push-pull), accept eventual convergence; use sketches/histograms to bound payload.
- Hard state: store in an authoritative system (consensus-backed config store). Distribute via:
- primary channel: pub/sub or streaming to edge components
- secondary channel: gossip as a fast fanout cache/invalidation hint
- enforcement: local denylist updated from authoritative stream; gossip never overrides authoritative state
- Repair: nodes periodically reconcile hard-state version with authority (anti-entropy against the source of truth), not just peers.
Hybrid architecture
Final challenge question
If the authoritative store is unreachable during a partition, do you fail closed (deny serving) or fail open (continue serving)?
Explain your choice in terms of safety, availability, and business risk.
Appendix — Quick reference cheatsheet
Gossip protocol checklist
- Define what is gossiped (state vs delta vs digest)
- Define conflict resolution (incarnation/epoch + status precedence)
- Bound per-round work (fanout, payload size, CPU)
- Choose dissemination mode (push/pull/push-pull)
- Add anti-entropy for repair
- Tune failure detection carefully (timeouts, suspicion)
- Instrument divergence and convergence
- Consider security assumptions (authN/authZ, rate limits)
[CODE] Python: convergence simulation (push gossip)
Key Takeaways
- Gossip protocols spread information by having each node randomly share with peers — like a rumor spreading through a crowd
- Gossip converges in O(log N) rounds — a 1000-node cluster reaches full convergence in about 10 gossip rounds
- No single point of failure — every node participates equally in spreading information, no coordinator needed
- Used for failure detection, membership, and metadata propagation — Cassandra, Redis Cluster, and Consul all use gossip
- Trade-off is convergence delay — updates take multiple rounds to reach all nodes, not suitable for latency-critical state changes