Distributed Consensus

Distributed Consensus (Paxos, Raft, ZooKeeper)
Audience: advanced distributed systems engineers who want a mental model that survives real outages.
You’re running a “single” system… on five machines
Scenario: You operate a payment service. Product insists: “there must be exactly one current ledger head.” Ops insists: “it must survive machine failures.” Compliance insists: “no split-brain.”
You deploy 5 nodes across zones. Each node can crash, reboot, stall, or get partitioned. Messages can be delayed, reordered, duplicated, or dropped.
Your job: make the cluster behave like one reliable decision-maker.
Pause and think
If two nodes temporarily can’t talk, should both continue accepting writes?
- A) Yes, for availability; reconcile later.
- B) No, only one side should accept writes.
Hold that thought - we’ll return to it when we talk about safety vs availability and why consensus is the “no split-brain” contract.
Key insight
Consensus is the mechanism that lets a distributed system act like it has a single authoritative state machine, even when nodes fail and networks misbehave.
What consensus is (and what it is not)
Scenario
You’re at a coffee shop with 5 baristas. Customers line up. The shop must maintain a single queue order and a single “next order to prepare.” If two baristas both start the same order or skip someone, chaos.
Interactive question (pause and think)
Which is the core problem consensus solves?
- Agreeing on who is alive.
- Agreeing on the next value/command in a sequence.
- Agreeing on the fastest node.
Pause.
Progressive reveal -> Answer
Correct: 2. Agreeing on the next value/command in a sequence.
Consensus is about agreeing on an ordered log of decisions (commands) that all replicas apply in the same order.
Mental model
Think of consensus as:
- A shared notebook (log)
- Where each line is a decision
- Everyone must write the same line n before moving to line n+1
If you can do that, you can replicate a database, a configuration store, a scheduler, a lock service - anything modeled as a deterministic state machine.
Real-world parallel
A restaurant kitchen ticket rail: tickets (commands) must be processed in order. If two chefs disagree about ticket #17, the dining room burns.
Key insight
Most “consensus systems” are really replicated state machines built on top of a consensus log.
Challenge questions
- What happens if two nodes apply the same commands in different orders?
- If commands are deterministic but order differs, can you still converge?
The contract - Safety first, then liveness
Scenario
A delivery company must assign exactly one driver to each package. If two drivers deliver the same package, you have fraud and chargebacks.
Interactive question
Which property is non-negotiable for consensus?
- A) Safety: never decide two different values for the same log index.
- B) Liveness: always eventually decide.
Pause.
Progressive reveal -> Answer
Correct: Safety is non-negotiable.
A consensus algorithm may become unavailable under certain failures (e.g., network partition), but it must not produce conflicting decisions.
Mental model
- Safety: “Nothing bad happens.” No split brain.
- Liveness: “Something good eventually happens.” Progress.
In real systems, we typically accept temporary loss of liveness to preserve safety.
Common Misconception
“Consensus means the system is always available.”
No. In the presence of partitions, you must choose: consistency or availability (CAP). Consensus algorithms in this family choose consistency/safety.
Key insight
If you need strict consistency, you are implicitly choosing CP behavior under partitions.
Challenge questions
- Under what conditions can a 5-node cluster lose liveness but remain safe?
- If you add more nodes, does liveness always improve?
Failure model - what can go wrong in a distributed environment
Scenario
Your baristas communicate via walkie-talkies. Sometimes the walkie-talkie cuts out for 30 seconds. Sometimes a barista disappears (crash). Sometimes two baristas hear different things.
Interactive check: Which failures must consensus tolerate?
Match the failure to the typical model:
| Failure | Crash-fault tolerant (CFT) consensus (Paxos/Raft/ZK) | Byzantine fault tolerant (BFT) consensus |
|---|---|---|
| Node stops responding | Yes | Yes |
| Network delays/reordering/duplication | Yes | Yes |
| Node lies / sends conflicting messages intentionally | No | Yes |
| Disk corruption (silent) | No (needs extra measures) | Sometimes (depends on threat model + crypto) |
Pause and think: Paxos/Raft/ZooKeeper are designed for CFT, not Byzantine.
Network assumptions (state them explicitly)
These protocols assume:
- Asynchronous network (unbounded delay) for safety.
- Eventual synchrony for liveness (timeouts eventually exceed network/processing delay).
- Nodes can crash and restart; stable storage is required for certain metadata.
Key insight
Paxos/Raft/ZooKeeper assume crash faults and a non-malicious environment; liveness requires some eventual stability.
Challenge questions
- If a node’s clock jumps forward, is that a Byzantine failure?
- If a node’s disk returns stale data, what layer should detect it?
The core idea - Quorums and majorities
Scenario
A committee of 5 decides the “official menu of the day.” You require at least 3 signatures to declare it official.
Interactive question
Why does requiring a majority help?
- A) A majority vote is always correct.
- B) Two majorities always overlap.
- C) Majorities prevent message loss.
Pause.
Progressive reveal -> Answer
Correct: B. Two majorities always overlap.
That overlap node acts as a “witness” ensuring two conflicting decisions can’t both be committed without someone noticing.
Mental model
For N nodes, a quorum is usually floor(N/2) + 1.
- In N=5, quorum=3.
- Any two quorums share at least one node.
This overlap is the foundation of safety.
Real-world parallel
A bank vault requiring 3-of-5 keys: any two sets of 3 share at least one keyholder, preventing two independent groups from opening two “different vaults” at once.
Key insight
Quorum intersection is the geometric backbone of consensus safety.
Challenge questions
- With N=4 and quorum=3, what is the failure tolerance?
- Why do many systems prefer odd N?
Replicated State Machine (RSM) in one picture
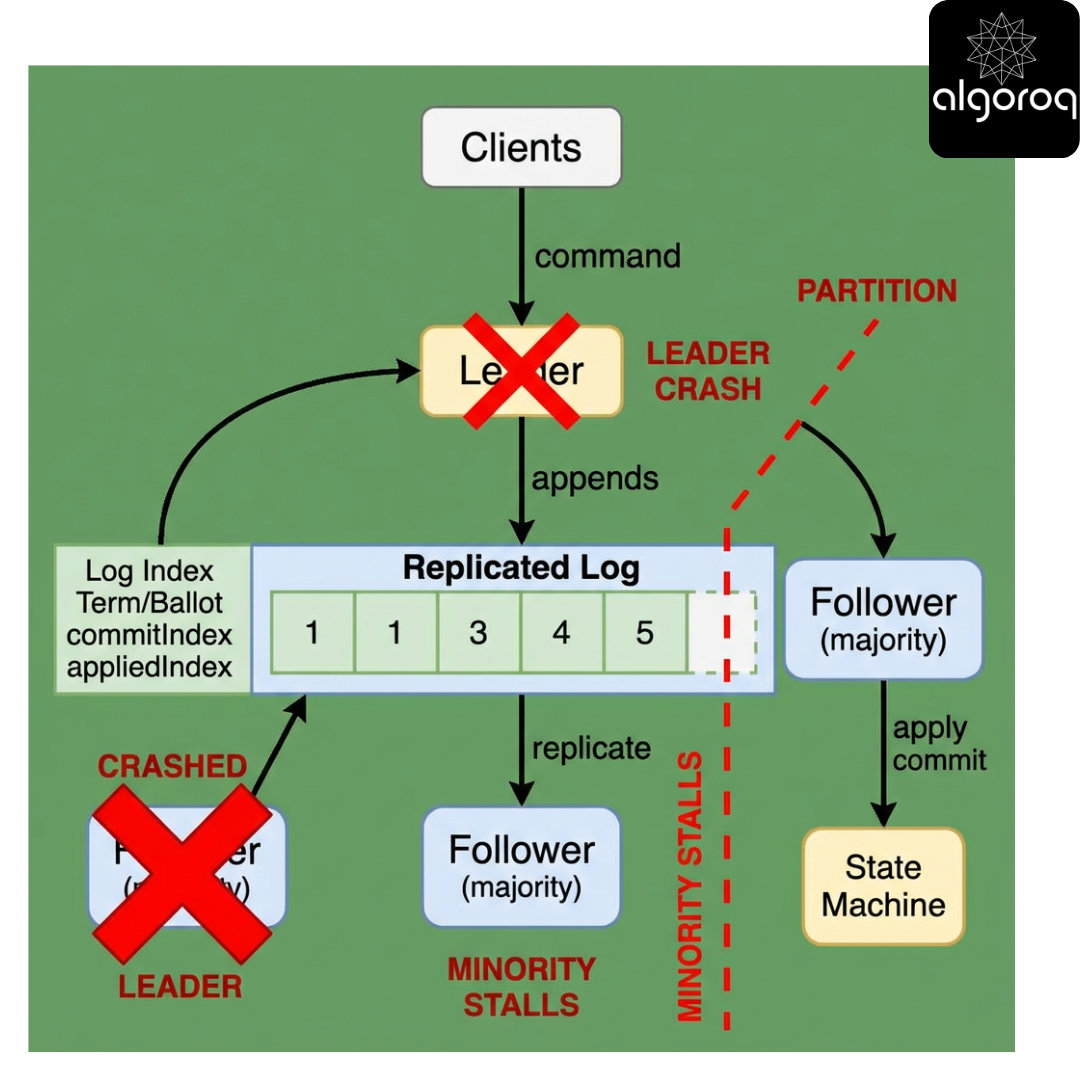
Scenario
You want your key-value store to behave like one machine.
Interactive question
What must be true for RSM correctness?
- All replicas execute the same commands.
- In the same order.
- Deterministically.
Pause.
Progressive reveal -> Answer
All three.
Consensus gives you (1) and (2). Your application must provide (3) or handle nondeterminism carefully.
Key insight
Consensus is not “replication.” It’s the agreement on order that makes replication safe.
Production insight: determinism pitfalls
- Don’t embed wall-clock timestamps inside commands unless the timestamp is generated by the leader and replicated as data.
- Avoid local randomness; if needed, generate randomness once and replicate the chosen value.
- Beware non-deterministic iteration order (e.g., hash maps) when applying commands.
Decision game - Do you need consensus here?
Scenario
You’re building:
- A) A metrics pipeline (eventual aggregation is fine)
- B) A leader election for a scheduler
- C) A distributed lock for a critical section
- D) A cache invalidation bus
Which statements are true?
- A needs consensus.
- B needs consensus.
- C needs consensus.
- D needs consensus.
Pause and think.
Progressive reveal -> Answer
- A: usually no (eventual consistency acceptable)
- B: yes (single leader)
- C: yes (mutual exclusion)
- D: depends (if correctness requires exactly-once invalidations, maybe; if best-effort, no)
Key insight
Use consensus when conflicting decisions are catastrophic.
Production insight
Cache invalidation often fails not because of ordering, but because of loss and retry storms. If invalidation correctness is security-critical (authz), treat it like configuration and use a CP store.
Part I - Paxos: the minimal, misunderstood foundation
Paxos in a coffee shop - picking today’s special
Scenario
Five baristas must agree on today’s special drink. They can’t all meet at once. Some are on break. Walkie-talkies drop.
Paxos is the protocol that ensures: once a special is chosen, it never changes.
Interactive question
What does Paxos primarily decide?
- A) A leader
- B) A value for a single slot
- C) A full replicated log
Pause.
Progressive reveal -> Answer
Correct: B. A value for a single slot.
Classic Paxos solves single-decree consensus: decide one value.
To get a log, you run Paxos for each slot (Multi-Paxos).
Key insight
Paxos is a building block: one slot at a time.
Paxos roles - Proposer, Acceptor, Learner
Scenario
- Proposers suggest the special.
- Acceptors are the “committee” that votes.
- Learners find out what won.
In practice, nodes often play multiple roles.
Interactive matching exercise
Match role -> responsibility:
| Role | Responsibility |
|---|---|
| Proposer | b) Initiates a proposal with a proposal number |
| Acceptor | a) Stores promises/accepts and enforces rules |
| Learner | c) Observes accepted values and determines chosen |
Key insight
Paxos safety lives inside acceptors.
Production insight
Acceptors must persist (on stable storage):
- highest promised ballot
- last accepted ballot/value
If acceptors lose this state (disk loss), safety can be violated unless you treat it as a new node and reconfigure membership.
Paxos safety rule - “Promises” prevent contradictions
Scenario
Two baristas propose different specials. We must avoid choosing both.
Paxos uses proposal numbers (ballots) and a two-phase handshake:
- Phase 1 (Prepare/Promise): proposer asks acceptors to promise not to accept lower-numbered proposals.
- Phase 2 (Accept/Accepted): proposer asks acceptors to accept a specific value under that proposal number.
Interactive question
Why does Paxos need proposal numbers?
- A) To order time.
- B) To break ties and ensure a single “highest” attempt.
- C) To encrypt messages.
Pause.
Progressive reveal -> Answer
Correct: B.
Proposal numbers establish a total order over attempts, independent of clocks.
Common Misconception
“Paxos elects a leader and then everything is easy.”
Leader election is an optimization (Multi-Paxos). Basic Paxos does not require a stable leader to be correct.
Key insight
Prepare/Promise ensures that once a value could have been chosen, future proposals must respect it.
Production insight: generating ballots
Real systems typically use a tuple (counter, nodeId):
- counter increases monotonically per node (persisted)
- nodeId breaks ties
This avoids collisions and ensures global ordering.
Paxos walk-through (single slot)
Scenario
Cluster: A1..A5 acceptors. Quorum=3. Two proposers: P and Q.
Step-by-step (progressive reveal)
Step 0: No value chosen.
Step 1: P sends Prepare(n=10) to A1,A2,A3.
Pause: what do acceptors reply?
Answer: They reply Promise(10, lastAccepted?) and record “promised n=10.”
Step 2: P receives promises from a quorum.
Pause: what value can P propose in Phase 2?
Answer: If any acceptor reported a previously accepted value, P must propose the value with the highest accepted proposal number. Otherwise, P can propose its own value.
Step 3: P sends Accept(n=10, value=VanillaLatte) to A1,A2,A3.
Step 4: A1,A2,A3 accept and reply Accepted.
Chosen: Once a quorum accepts, VanillaLatte is chosen.
Key subtlety
A value can be chosen even if no learner has learned it yet. Learners learn via acceptor notifications or by querying.
Key insight
Paxos chooses when a quorum of acceptors accept the same (n, value).
Multi-Paxos - turn Paxos into a log
Scenario
Your coffee shop needs not one decision, but a sequence: specials for Monday, Tuesday, Wednesday…
Multi-Paxos runs Paxos for each log index but typically uses a stable leader to avoid repeating Phase 1 for every entry.
Interactive question
What does a stable leader buy you?
- A) Removes the need for quorums.
- B) Avoids Phase 1 for every log entry.
- C) Makes Paxos Byzantine tolerant.
Pause.
Answer
Correct: B.
With a stable leader, you do Phase 1 once (establish leadership with a high ballot), then append many entries with Phase 2.
Key insight
Multi-Paxos ~= “Paxos with a long-lived distinguished proposer.”
Production insight
Leader changes correlate with latency spikes because:
- Phase 1 must run again
- caches warm up (client routing)
- followers may need log catch-up
- disks may be saturated by replay/fsync
Paxos failure scenarios - what breaks, what pauses
Scenario set
You run a 5-acceptor Multi-Paxos cluster.
Failure game: which outcomes are possible?
- Leader crashes, 4 nodes remain connected.
- a) Safety violated
- b) Cluster unavailable briefly; new leader elected
- c) Cluster continues with no interruption
- Network partition: 2 nodes vs 3 nodes.
- a) Both sides can commit new entries
- b) Only the 3-node side can commit
- c) Neither side can commit
Pause and think.
Answers
- b (safety holds; liveness depends on leader replacement)
- b under majority-quorum consensus
Production insight: client-visible behavior
- The minority side should reject writes quickly (fail-fast) to avoid building large uncommitted tails.
- Clients must treat timeouts as “unknown” and use idempotency keys / de-duplication.
Part II - Raft: consensus designed for humans
Why Raft exists - “understandability” as a feature
Scenario
You inherit a Paxos-based system. It works, but nobody can confidently modify it. Incidents happen because engineers fear touching the consensus layer.
Raft was designed to be easier to understand and implement while providing similar properties (CFT, majority quorums, leader-based replication).
Interactive question
Which design choice is central to Raft?
- A) Leaderless decisions
- B) Strong leader that manages log replication
- C) Randomized quorums
Pause.
Answer
Correct: B.
Raft decomposes the problem into:
- Leader election
- Log replication
- Safety (ensuring leaders don’t overwrite committed entries)
Key insight
Raft is “Multi-Paxos with a clearer story”: explicit terms, elections, and log matching.
Raft roles and terms - Follower, Candidate, Leader
Scenario
A restaurant has:
- Followers: line cooks following the head chef’s tickets.
- Leader: head chef calling tickets.
- Candidate: a cook who steps up when the head chef disappears.
Raft adds terms: numbered epochs of leadership.
Interactive question
What is a “term” most like?
- A) A wall-clock timestamp
- B) A monotonic epoch number
- C) A hash of the leader ID
Pause.
Answer
Correct: B.
Terms let nodes detect stale leaders and stale messages.
Key insight
Term numbers are the “version” of leadership.
Production insight
Persist on stable storage:
currentTermvotedFor- log entries
If you don’t, a reboot can cause a node to “forget” it voted and violate election safety.
Raft leader election - random timeouts to avoid dueling leaders
Scenario
If everyone tries to become head chef at once, you get chaos. Raft uses randomized election timeouts.
Interactive exercise
You have 5 nodes. All followers. Election timeout is random 150-300ms.
Pause and think: Why randomness?
Progressive reveal -> Answer
Randomness reduces the probability that two nodes start elections simultaneously, preventing repeated split votes.
Election flow (simplified)
- Follower times out -> becomes Candidate.
- Candidate increments term, votes for itself.
- Sends RequestVote(term, lastLogIndex, lastLogTerm).
- Receives majority votes -> becomes Leader.
- Leader sends AppendEntries heartbeats to maintain authority.
Common Misconception
“Leader election is just ‘pick the lowest ID’.”
Not safe under partitions. You need a mechanism that ensures at most one leader per term and that leaders have sufficiently up-to-date logs.
Key insight
Raft’s voting rule couples leadership to log freshness, preventing leaders without committed entries.
Failure scenario: split vote
If two candidates each get 2 votes in a 5-node cluster, nobody wins; they time out again with new randomized timeouts and retry.
Raft log replication - AppendEntries and the log matching property
Scenario
The head chef writes tickets in order and ensures each station has the same ticket list.
Interactive question
What does Raft replicate?
- A) State snapshots only
- B) A log of commands
- C) Only the latest value
Pause.
Answer
Correct: B.
Log matching property
If two logs contain an entry with the same index and term, then:
- The logs are identical in all entries up to that index.
This is enforced by AppendEntries carrying prevLogIndex and prevLogTerm.
Progressive reveal: why prevLogTerm matters
Pause: Why not just prevLogIndex?
Answer: Because a follower might have an entry at that index from a different leader/term; term disambiguates and detects conflicts.
Performance insight: conflict backtracking
Naively decrementing nextIndex one-by-one can be expensive. Production Raft implementations use a conflict hint (e.g., conflictTerm and conflictIndex) to jump back faster.
Key insight
Raft repairs divergence by forcing followers to match the leader’s log prefix.
Commit index and applying to the state machine
Scenario
A ticket is not “official” until enough stations have it.
In Raft:
- Leader appends entry to its log.
- Replicates to followers.
- When entry stored on a majority, leader advances commitIndex.
- All nodes apply entries <= commitIndex to the state machine.
Interactive question
When is a log entry committed?
- A) When leader writes it locally
- B) When a majority stores it
- C) When all nodes store it
Pause.
Answer
Correct: B.
Subtle safety rule (important)
A leader only uses “count replicas” to advance commitIndex for entries from its current term. Earlier-term entries become committed indirectly when a later entry from the current term commits.
Key insight
“Committed” is a quorum-backed promise that the entry will survive future leader changes.
Raft failure scenarios - partition, crash, slow disk
Scenario 1: Partition 3-2
- Majority side elects/keeps leader -> continues committing.
- Minority side cannot commit.
Scenario 2: Old leader isolated
Old leader may continue accepting client requests, but cannot commit without a majority. Correct behavior is to reject writes or accept-but-not-ack (rare; usually a bad API).
Scenario 3: Slow follower
A follower with slow disk can lag far behind; leader maintains nextIndex/matchIndex per follower.
Decision game: which statement is true?
- “A leader can commit entries without any follower acknowledging them.”
- “A follower can apply an uncommitted entry.”
- “A leader can be elected with a stale log.”
Pause.
Answer
- No (needs quorum)
- No (apply only committed)
- No (voting rule prevents it)
Production insight: GC pauses and stop-the-world
A leader that pauses for 30s can trigger elections. When it returns, it will observe a higher term and step down. This is correct but can cause:
- write unavailability during election
- tail latency spikes
Mitigations:
- keep GC pauses low (heap sizing, GC tuning)
- separate IO threads from GC-heavy work
- use jittered timeouts and avoid too-tight election windows
Raft configuration changes - changing the committee without chaos
Scenario
Your coffee shop hires a new barista (add node) or someone quits (remove node). You must change membership without creating two different majorities.
Raft uses joint consensus (in many implementations): during transition, decisions require quorums from both old and new configs.
Interactive question
Why can’t you just switch configs instantly?
Answer
Because you could create a moment where two different majorities exist (old set and new set) that don’t intersect, risking split brain.
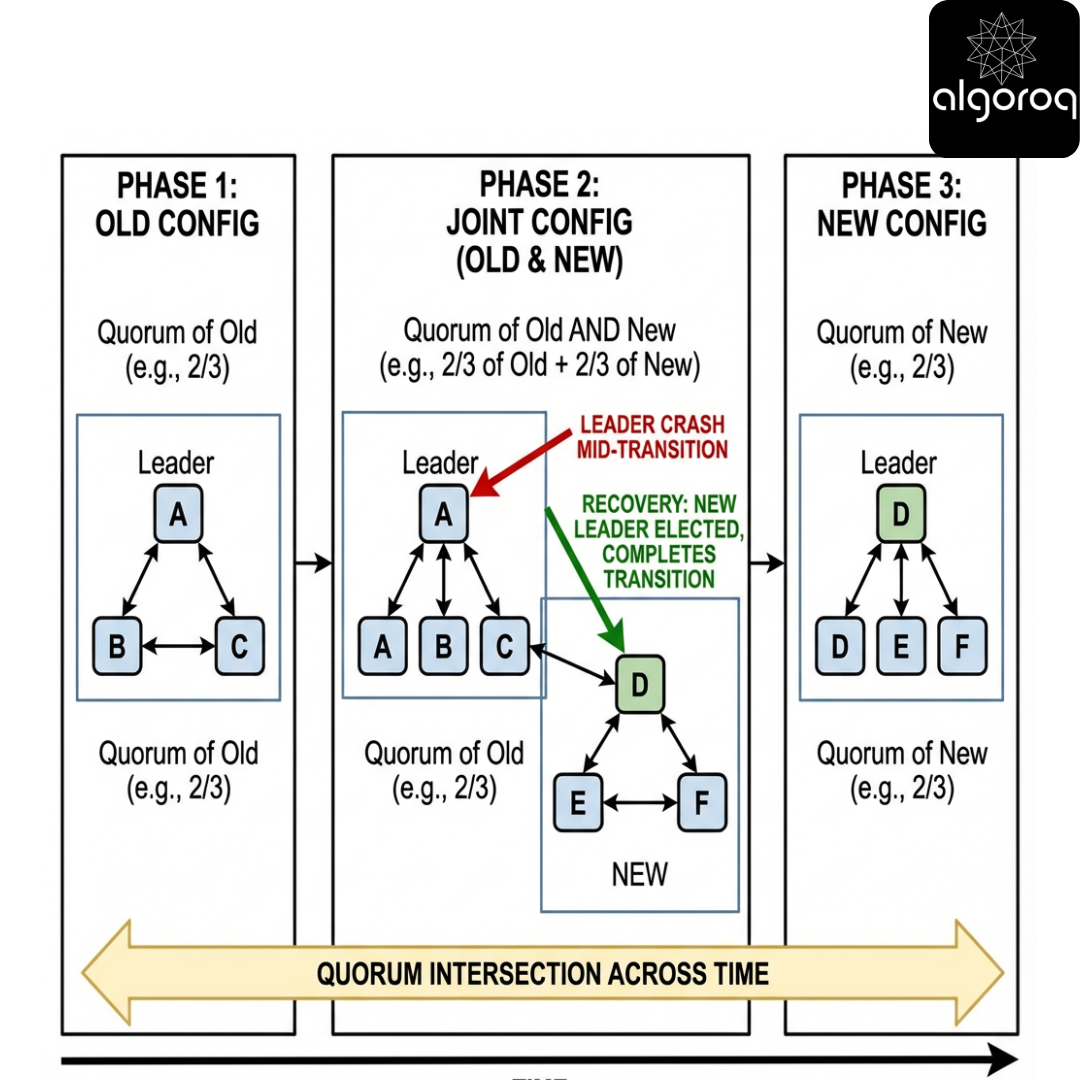
Key insight
Membership changes must preserve quorum intersection across time.
Failure scenario: leader crash mid-transition
Correct implementations persist the joint configuration as a log entry. After crash/restart, the cluster continues the transition based on the committed log.
Part III - ZooKeeper: consensus as a coordination service
ZooKeeper’s promise - “a small, consistent brain” for your cluster
Scenario
You run a fleet of services that need:
- Leader election
- Configuration storage
- Distributed locks
- Service discovery metadata
You don’t want every team implementing consensus. You deploy ZooKeeper as a shared coordination service.
Interactive question
ZooKeeper is best described as:
- A) A general-purpose database
- B) A coordination service with a replicated in-memory data tree
- C) A message queue
Pause.
Answer
Correct: B.
ZooKeeper provides a hierarchical namespace (znodes) with strong consistency guarantees.
Key insight
ZooKeeper is a CP coordination system optimized for metadata, not bulk data.
Production insight
ZooKeeper is often a shared dependency; treat it like critical infrastructure:
- isolate it (dedicated nodes, predictable disks)
- protect it from noisy neighbors
- enforce client retry/backoff policies to avoid ensemble overload during incidents
ZooKeeper’s consensus core - ZAB (and how it relates)
Scenario
ZooKeeper needs all servers to agree on the order of updates to the znode tree.
It uses ZAB (ZooKeeper Atomic Broadcast), a protocol similar in spirit to leader-based log replication (like Multi-Paxos/Raft).
Interactive question
What does ZooKeeper replicate?
- A) A log of transactions (updates)
- B) A CRDT state
- C) Only leader state
Pause.
Answer
Correct: A.
ZAB ensures a total order of updates and that followers apply them consistently.
Key insight
ZooKeeper is effectively a replicated log + deterministic state machine (the znode tree).
ZooKeeper data model - znodes, ephemeral nodes, watches
Scenario
You want leader election for a service “orders.” Each instance registers itself. When the leader dies, another should take over.
ZooKeeper gives you:
- Persistent znodes: survive client session.
- Ephemeral znodes: deleted when the client session ends.
- Sequential znodes: ZooKeeper appends a monotonically increasing counter.
- Watches: one-time notifications when data/children change.
Interactive question
Which feature is the secret weapon for coordination?
- A) Ephemeral nodes
- B) Watches
- C) Both, combined
Pause.
Answer
Correct: C.
Ephemeral nodes represent liveness; watches provide event-driven reactions.
Production insight: watches are not durable subscriptions
Watches are:
- one-shot
- can be missed across session expiration
- can trigger multiple times due to reconnect/re-register patterns
Correct recipes always re-read state after a watch fires.
Interactive pattern - Leader election with ephemeral sequential znodes
Scenario
Each service instance creates /election/c_ as an ephemeral sequential znode._
The one with the smallest sequence number is leader.
Pause and think
If you watch the leader znode directly, what happens when there are 10,000 clients?
Answer
You risk the herd effect: everyone wakes up on leader change.
Better: each node watches its predecessor (the znode with the next smaller sequence). Only one node wakes up when predecessor disappears.
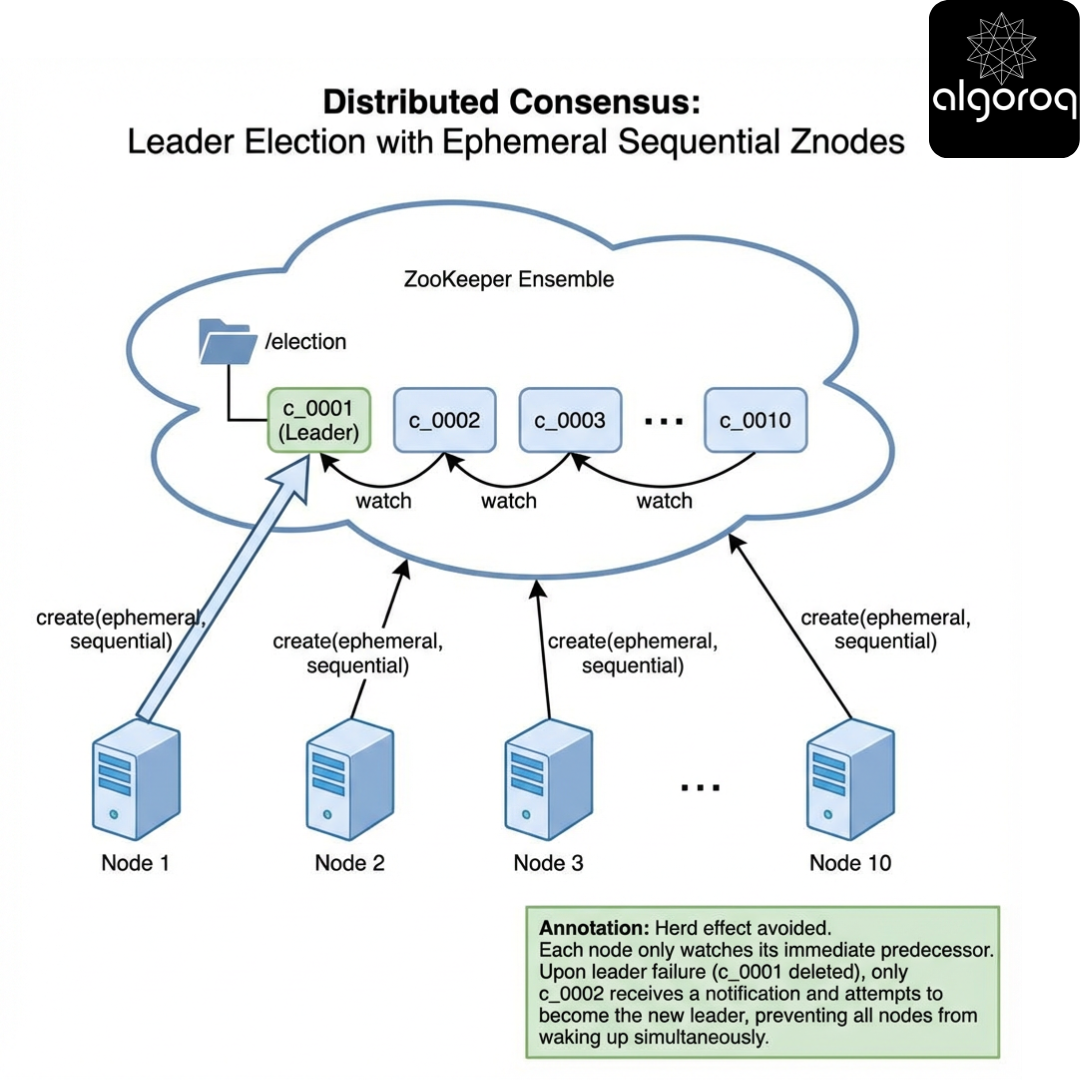
Code (toy demo)
The following code is not real ZooKeeper; it’s a TCP-style demo of the recipe. Production ZooKeeper clients use the official libraries and handle session events.
Python (fixed IO + race-safe loop)
JavaScript (fixed line framing)
Key insight
Correct ZooKeeper recipes avoid herd effects by watching predecessors, not the leader.
Failure scenarios to handle (real ZooKeeper)
- Session expiration: your ephemeral node is gone; you must recreate and re-elect.
- Temporary disconnect: session may still be valid; don’t assume leadership is lost until expiration.
- Watch race: predecessor can disappear between
getChildrenandexists(watch=true); always re-check.
ZooKeeper consistency guarantees - what you get (and what you don’t)
Scenario
You store configuration in ZooKeeper. You want every service to see updates in a consistent order.
ZooKeeper provides:
- Linearizable writes
- Total order of writes
- Session semantics (client order)
But reads can be tricky:
- A client reading from a follower may see stale data unless you use sync() or read from the leader.
Decision game: which statement is true?
- “ZooKeeper reads are always linearizable.”
- “ZooKeeper can serve stale reads.”
- “ZooKeeper guarantees per-client FIFO ordering.”
Pause.
Answer
- 1: No
- 2: Yes (depending on read path)
- 3: Yes (client order guarantees)
Key insight
ZooKeeper is strongly consistent for writes, but read semantics depend on how you read.
Production insight
- For locks/coordination, prefer patterns that rely on writes + watches, not follower reads.
- Use
sync()when you must ensure your subsequent read reflects the latest committed state.
Part IV - Compare Paxos vs Raft vs ZooKeeper (and when to use what)
Comparison table - concepts and trade-offs
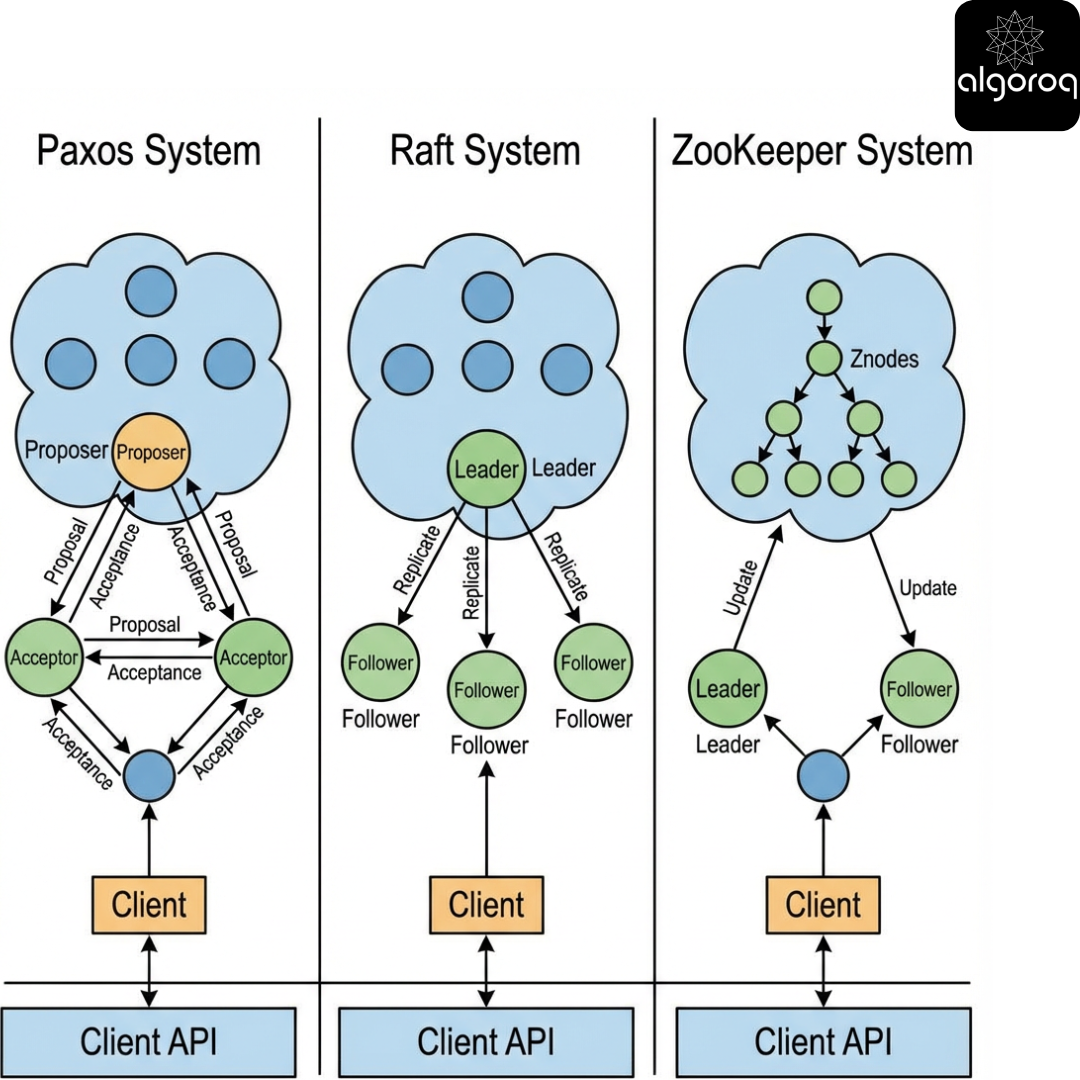
| Dimension | Paxos / Multi-Paxos | Raft | ZooKeeper |
|---|---|---|---|
| Primary goal | Consensus (single slot -> log) | Understandable consensus + log replication | Coordination service built on consensus (ZAB) |
| Typical deployment | Embedded in DBs/systems | Embedded in systems (etcd/Consul-like) | Dedicated ensemble used by many apps |
| Leader | Optional (optimization) | Central to design | Leader-based |
| API | Usually internal (append log) | Usually internal (append log) | External API (znodes, watches) |
| Strength | Proven minimal core | Clarity, safer implementations | Rich coordination primitives |
| Weakness | Hard to reason/teach | Membership changes & compaction complexity | Misuse leads to herd effects; not for bulk data |
| Failure behavior | CP; needs majority | CP; needs majority | CP; needs majority |
Key insight
Choose Raft/Multi-Paxos when you’re building a replicated system; choose ZooKeeper when many systems need shared coordination and you accept operating a dedicated ensemble.
Production trade-off: blast radius
- Shared ZooKeeper: one outage can impact many services.
- Embedded Raft per service: fewer shared dependencies, but more operational diversity and upgrade risk.
Matching exercise - use case -> best fit
Match each use case to the best option (Paxos/Multi-Paxos, Raft, ZooKeeper):
- A new distributed SQL database replication layer
- A Kubernetes-like control plane key-value store
- A shared lock service for multiple legacy apps
- A single app that needs leader election and log replication internally
Suggested answers
- Paxos/Multi-Paxos or Raft (embedded)
- Raft (common in etcd-like designs)
- ZooKeeper (coordination service)
- Raft (simpler embedded leader/log)
Part V - The hard parts engineers actually trip over
Linearizability vs serializability vs “it seems consistent”
Scenario
A client writes x=1, then reads x. They expect 1.
Interactive question
Which guarantee is this?
- A) Eventual consistency
- B) Linearizability
- C) Read-your-writes (session consistency)
Pause.
Answer
It depends:
- If the read must reflect the write for all clients and respect real-time order -> Linearizability.
- If only the same client must see its own writes -> Read-your-writes.
Consensus orders operations; your client read path determines whether you get linearizability.
Production insight
- “Leader reads” are typically linearizable.
- “Follower reads” can be stale unless you use quorum/lease mechanisms.
- Leader leases improve performance but require careful clock assumptions; if clocks drift or pauses occur, leases can break linearizability.
Log compaction and snapshots - keeping the notebook from exploding
Scenario
Your replicated log grows forever. Disk fills. Restart time becomes hours.
Consensus systems use:
- Snapshots of state machine
- Log truncation up to snapshot index
Interactive question
Why is snapshotting tricky?
Answer
Because you must ensure that:
- Snapshots correspond to a committed prefix
- Followers install snapshots safely
- Membership/config changes remain consistent across snapshots
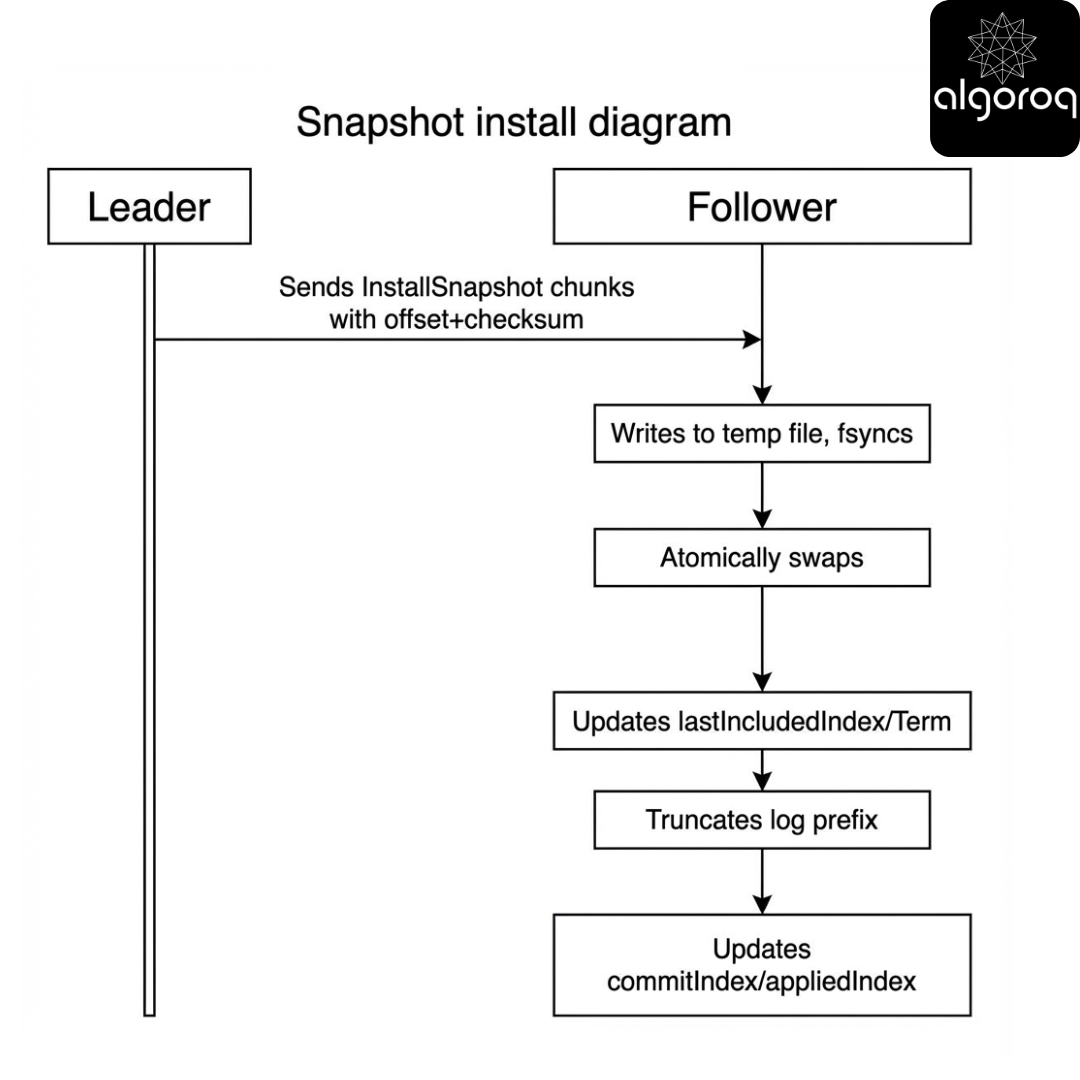
Code (correctness fixes)
Below is a toy illustration. Key fixes vs common mistakes:
- snapshots should be accepted only if they are not older than follower’s current snapshot
- commitIndex should become
max(commitIndex, lastIncludedIndex)(not decrease) - production requires chunking, checksums, and atomic file replace
Key insight
Snapshots are not just storage optimization - they are part of correctness and recovery.
The client problem - how do clients know who the leader is?
Scenario
A client wants to write. It contacts node A, but A is a follower.
Interactive question
Which client strategy is safest?
- A) Always write to a random node; let it forward.
- B) Cache the leader; retry on redirect.
- C) Broadcast writes to all nodes.
Pause.
Answer
Typically B, sometimes A depending on system design.
- Many Raft systems return “not leader” with leader hint.
- Some systems allow follower forwarding.
Broadcasting writes is expensive and can amplify failures.
Production insight: retries and idempotency
- Use exponential backoff + jitter.
- Treat timeouts as unknown outcome.
- Use idempotency keys / request IDs to prevent duplicate side effects.
Timeouts, heartbeats, and the latency/availability trade-off
Scenario
You set election timeout to 1s to avoid spurious elections. But failover now takes seconds.
Interactive question
What happens if election timeout is too low?
Answer
You get unnecessary elections under transient delays (GC pauses, noisy neighbors), reducing throughput and increasing tail latency.
If too high, recovery is slow.
Key insight
Tuning timeouts is balancing false positives (unneeded elections) vs failover time.
Production metrics to watch
- election rate / term churn
- leader tenure distribution
- fsync latency (p99)
- replication lag per follower
- commit latency (p99)
Part VI - Putting it all together: a progressive synthesis
Build a mental model that predicts behavior
Mental model: “The log is the truth, the leader is the coordinator”
- The system’s authoritative history is the committed log prefix.
- The leader is a traffic coordinator, not an oracle.
- Quorums ensure that committed history survives failures.
- Under partition, only the side with a quorum can move the commit point.
Key insight
If you can reason about commitIndex and quorum intersection, you can reason about most outages.
Synthesis decision game - Which system behavior is correct?
Scenario
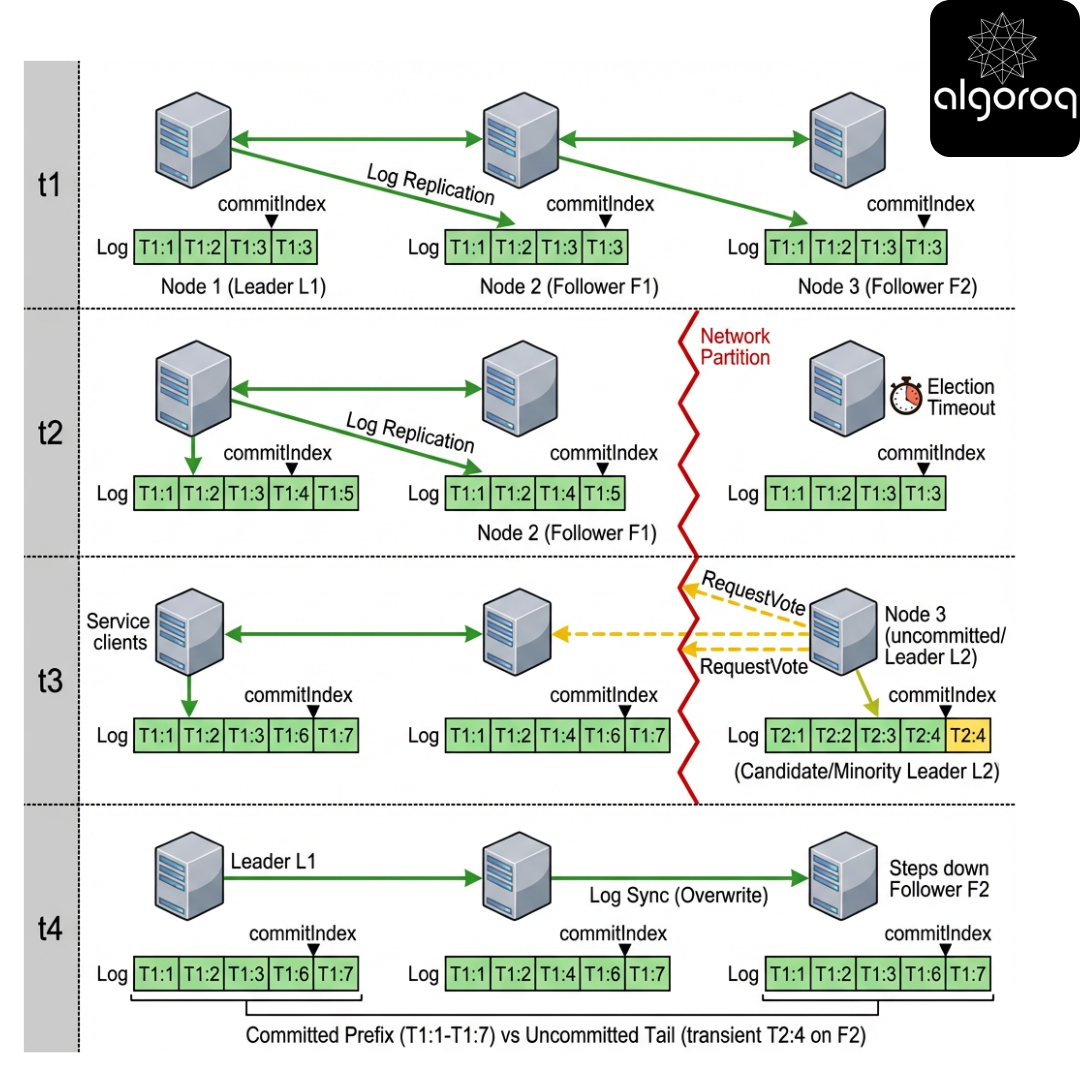
You have a 5-node Raft cluster: A,B,C,D,E.
- Term 7 leader is A.
- Network partition occurs: {A,B} and {C,D,E}.
- Clients keep sending writes to A.
Which statements are true?
- A can keep accepting writes and commit them.
- A may append entries locally but cannot commit them.
- {C,D,E} can elect a new leader and commit new writes.
- When partition heals, A’s uncommitted entries might be overwritten.
Pause and think.
Progressive reveal -> Answer
True: 2, 3, 4.
A can accept writes but should typically fail them (or accept but not acknowledge) because it can’t reach a majority.
When the partition heals, the majority side’s leader will force log convergence; A’s uncommitted tail can be discarded.
Key insight
Committed entries never roll back; uncommitted entries can.
Final synthesis challenge: Design a coordination layer for a microservice fleet
Scenario
You operate 200 microservices. They need:
- Leader election per service
- Config distribution
- Feature flags
- A global lock for one legacy shared resource
Constraints:
- You can operate one shared system (SRE-owned) or embed libraries in each service.
- You need strong consistency for locks and leader election.
- You want to minimize blast radius.
Your task (pause and sketch)
Choose an architecture:
- Option A: One ZooKeeper ensemble shared by all.
- Option B: One etcd-like Raft KV store shared by all.
- Option C: Each service embeds Raft for its own needs.
- Option D: Hybrid: shared CP store for coordination + embedded Raft where needed.
Pause and think about:
- Failure domains
- Operational complexity
- Client libraries and retry storms
- Data model fit (znodes vs KV)
Progressive reveal -> Suggested reasoning
- Shared coordination (ZooKeeper/etcd) centralizes correctness and operations, but increases shared dependency blast radius.
- Embedded consensus reduces shared dependency but increases implementation diversity, upgrades, and operational complexity.
- Hybrid often wins: shared CP store for cross-service coordination; embed consensus only for systems that truly need independent replication.
Key insight
Consensus is easy to want and hard to operate. The best design is the one whose failure modes you can explain at 3am.
Appendix: Practical “gotchas” checklist
- Majority quorum required for commit (CP under partition)
- Persist critical metadata (term/ballot, votedFor, accepted values)
- Beware GC pauses and long stop-the-world events
- Use jittered retries and backoff; avoid retry storms
- Understand read semantics (leader reads vs follower reads)
- Plan for snapshots/log compaction
- Test partitions (not just crashes)
- Monitor: election rate, commit latency, log lag, fsync latency
Where to go next
- Implement a toy Raft log to internalize commitIndex and term transitions.
- Read production postmortems involving split brain and quorum loss.
Note: the original appendix label said “Go” but the snippet was Python/JS. Fixed below.
[CODE: Python, context: “toy Raft append + commit simulation with partitions”; demonstrate leader appends, quorum acks, commit advancement, and rollback of uncommitted entries after leader change]
Key Takeaways
- Consensus allows a distributed system to act as a single reliable decision-maker — even when nodes fail and networks partition
- Safety is non-negotiable — consensus never produces conflicting decisions, even at the cost of temporary unavailability
- Raft is the most understandable consensus algorithm — leader election, log replication, and safety rules are clearly separated
- Paxos is theoretically equivalent to Raft but harder to implement — most production systems prefer Raft for its clarity
- etcd, ZooKeeper, and Consul all use consensus for distributed coordination — leader election, configuration management, and distributed locks