Vector Clocks and Lamport Timestamps

Vector Clocks and Lamport Timestamps
Audience: engineers who already know basic distributed systems concepts (messages, processes, partial failure) and want to reason precisely about ordering.
Network model assumptions (explicit): asynchronous network (unbounded delay), messages may be delayed, duplicated, and reordered; nodes may crash/restart; partitions may occur. No global clock assumption.
Who edited the order first?
You run a food-delivery platform.
- Service A (Restaurant) updates an order: "Add extra spicy."
- Service B (Courier) updates the same order: "Courier picked up."
- Service C (Customer Support) updates: "Customer called: remove peanuts."
All these updates happen across regions with variable latency, retries, and occasional partitions.
Your problem: when the updates arrive at the database (or event log), you need to answer:
- Did update X happen before update Y? (causal order)
- If they are concurrent, can we detect that reliably?
- If we must pick an order anyway (for UI or deterministic replication), how do we do it?
Pause and think
If the only thing you have is each machine's local clock (wall time), what can go wrong?
- clock skew
- NTP adjustments (time jumps backward/forward)
- drift under load
- leap seconds
- VM pause / container rescheduling artifacts
Key insight:
In distributed systems, physical time is not a reliable ordering oracle. We often need logical time.
Production insight:
- Even if you use monotonic clocks locally, you still can't compare monotonic clocks across machines.
- If you use wall time for ordering (e.g., last-writer-wins), you are implicitly choosing a consistency model that can be violated by skew.
What "ordering" really means (partial order vs total order)
Scenario
Imagine three baristas in a coffee shop taking orders on separate tablets. Orders sync to the kitchen over Wi-Fi. Wi-Fi sometimes drops.
The kitchen wants to know:
- Which actions were causally related (one depended on seeing another)?
- Which actions were independent (concurrent)?
Interactive question (pause and think)
Which of these is actually true in a distributed system?
A. Every pair of events has a well-defined "happened first" relationship.
B. Some pairs of events are incomparable: neither happened before the other.
C. If two events have different wall-clock timestamps, the earlier timestamp happened first.
Answer (reveal)
Correct: B.
Distributed executions usually form a partial order:
- Some events are ordered by causality.
- Some are concurrent (no causal path between them).
Wall-clock timestamps do not fix this because they can be inconsistent across machines.
Mental model:
Think of events as nodes in a graph.
- An arrow e1 -> e2 means "e1 could have influenced e2".
- If there is a path from e1 to e2, then e1 happened-before e2.
- If there is no path either way, they are concurrent.
Key insight:
You do not want "time". You want a way to approximate causality.
Challenge question:
- Name two reasons why "total ordering of all events" is expensive or unnatural in distributed systems.
Production answers you should expect:
- Total order requires coordination (consensus / total order broadcast), which increases latency and reduces availability under partition.
- Many events are independent; forcing a total order introduces artificial dependencies and can reduce throughput.
The happened-before relation (Lamport's foundation)
Scenario
You operate three microservices:
- Billing
- Inventory
- Shipping
A customer checks out.
- Billing charges card.
- Inventory reserves item.
- Shipping creates shipment.
You need to ensure shipping does not happen "before" reservation, but you also accept that some unrelated operations can proceed concurrently.
Pause and think
What establishes causality?
Pick all that apply:
- Two events in the same process, one after another.
- Sending a message and receiving that message.
- Two events with timestamps that differ by 1.
Answer (reveal)
Correct: 1 and 2.
Lamport's happened-before (->) is defined by:
- Program order: if a and b are in the same process and a occurs before b, then a -> b.
- Message order: if a is send(m) and b is receive(m), then a -> b.
- Transitivity: if a -> b and b -> c, then a -> c.
Statement 3 is a trap: timestamps are a tool we build; they do not define causality.
Key insight:
Causality is about information flow, not about numeric clocks.
Challenge question:
- If service A writes to a database and service B later reads that record, is that causality? Under what assumptions?
Clarification (important):
- It is causality only if B's read is guaranteed to observe A's write (e.g., same linearizable register, or same leader with read-your-writes/session guarantees, or B reads from a replica that has applied A's write).
- Under eventual consistency or stale reads, B may read an older version; then you cannot infer A -> B from "wall time" or from the mere fact that a read happened later.
Lamport timestamps - numbering events to respect causality
Scenario
You run a restaurant with a paper ticket system.
- Each station has a ticket counter.
- When a station creates a new ticket, it increments its counter and writes the number.
- When it receives a ticket from another station, it ensures its counter is at least that number, then increments.
This ensures ticket numbers move forward in a way that respects dependencies.
Interactive question (pause and think)
What property do Lamport timestamps guarantee?
A. If a -> b then L(a) < L(b).
B. If L(a) < L(b) then a -> b.
C. If two events are concurrent, they always get the same timestamp.
Answer (reveal)
Correct: A.
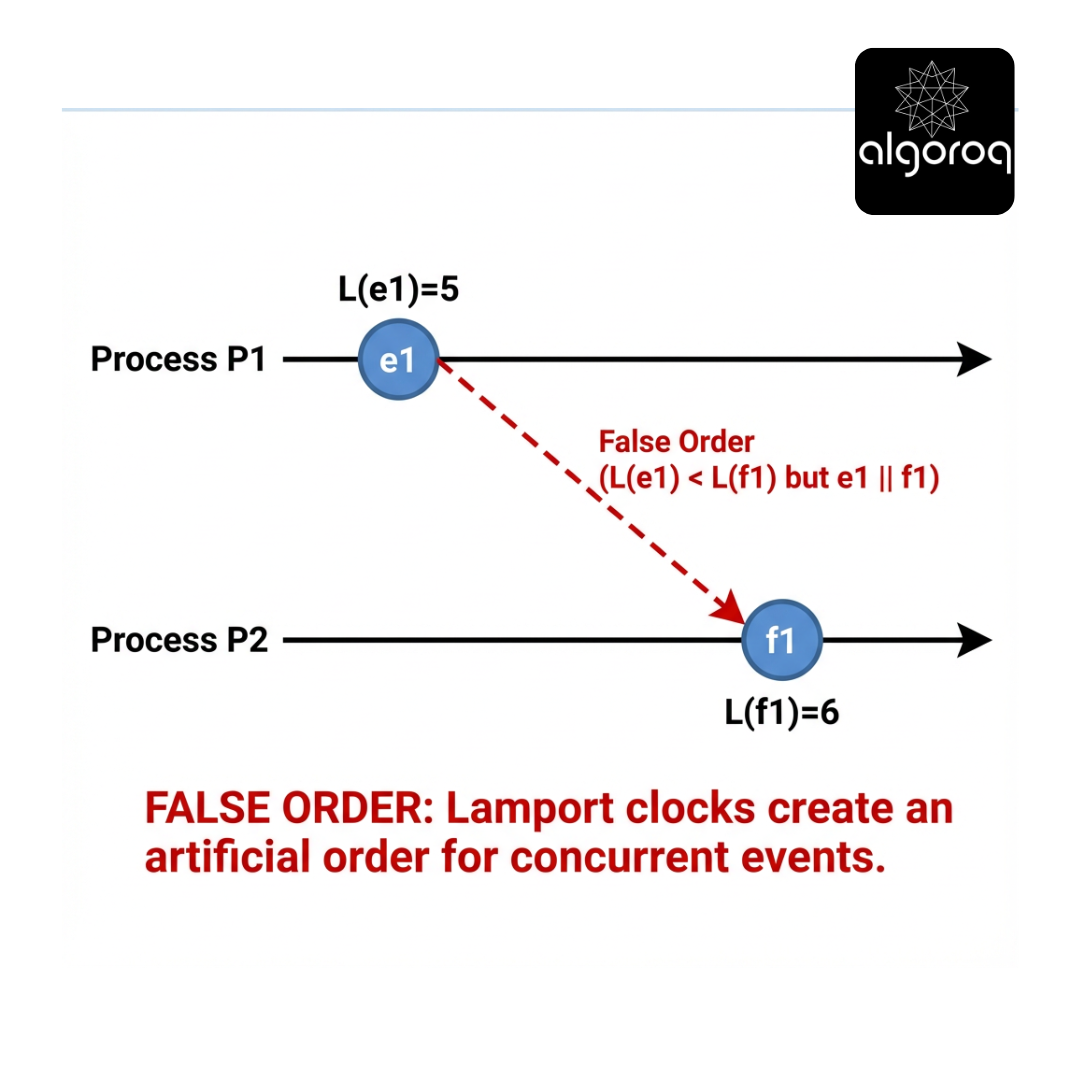
Lamport timestamps provide a consistent numbering that respects happened-before:
- Soundness for causality: a -> b implies L(a) < L(b).
- Not completeness: L(a) < L(b) does not imply a -> b.
So Lamport timestamps cannot detect concurrency reliably.
Mental model:
Lamport timestamp is like a "take-a-number" dispenser at each counter, with a rule:
- Your number must be greater than any number you have seen.
This preserves a causality-respecting order, but it also introduces false order between concurrent events.
Algorithm
Each process i maintains an integer clock Li.
Rules:
- Before each local event: Li := Li + 1 and timestamp the event with Li.
- Send message: include timestamp t = Li.
- Receive message with timestamp t: Li := max(Li, t) + 1.
[CODE: Python, demonstrate Lamport timestamp update rules for send/receive and local events]
Real-world usage
Lamport timestamps show up in systems that need:
- deterministic ordering for tie-breaking (often combined with process ID)
- monotonic versioning in logs
- ordering events in distributed mutual exclusion (classic Lamport algorithm)
But if you need to know whether events are concurrent, Lamport alone will not do.
[MISCONCEPTION]
"Lamport timestamps capture causality."
They capture it only one-way:
- If causality exists, timestamps reflect it.
- If timestamps differ, causality may not exist.
Key insight:
Lamport timestamps are a causality-respecting sequence, not a causality detector.
Challenge question:
- Suppose you sort events by (LamportTimestamp, processId) to get a total order. What kind of bugs can this hide in a replication system?
Production insight:
- It can hide write-write conflicts by forcing an arbitrary winner, causing lost updates unless your operation is commutative or you have explicit conflict resolution.
- It can hide invariant violations (e.g., CANCELLED vs PAID) by making one appear to "happen after" the other even though they were concurrent.
Which log order is safe?
Scenario
Two services update a shared key status:
- P1: sets status = "PAID"
- P2: sets status = "CANCELLED"
They happen concurrently (no messages between them). Your system uses Lamport timestamps and then sorts by (L, pid).
Which statement is true?
- Sorting by (L, pid) ensures every replica converges to the same final value.
- Sorting by (L, pid) ensures the final value respects real-world causality.
- Sorting by (L, pid) detects concurrency and can prevent conflicting updates.
Answer (reveal)
Mostly true: 1 - with important caveats.
- Deterministic ordering gives convergence if every replica applies the same set of operations in that same deterministic order.
Caveats (production-critical):
- If replicas can permanently miss operations (message loss without anti-entropy), they will diverge regardless of ordering.
- If operations are not idempotent and you don't deduplicate, duplicates can diverge state.
- If you have side effects (emails, payments), deterministic replay order does not make side effects safe.
Statements 2 and 3 are false.
Analogy:
It is like a restaurant manager forcing a single queue order by "ticket number then cashier ID". Everyone agrees on the order, but two independent customers might be arbitrarily swapped.
Key insight:
Total order is great for convergence; it is not the same as causal truth.
Challenge question:
- When is "deterministic but arbitrary" ordering acceptable? Name two system types.
Examples:
- Replicated logs where operations are commutative or where you only need a stable presentation order (analytics ingestion, audit display).
- Systems that already have a single-writer per key/partition (Kafka partition leader, Raft leader) where concurrency is structurally prevented.
Vector clocks - receipts of what you have seen
Scenario
Now imagine each barista keeps not just a local counter, but a small notebook:
- For each barista, it records the latest ticket number from that barista the kitchen has seen.
When barista A sends an order to the kitchen, it includes the notebook snapshot.
This allows the kitchen to compare two tickets and decide:
- Ticket X happened before ticket Y
- or they are concurrent
Pause and think
What extra power do vector clocks provide over Lamport timestamps?
A. They can detect concurrency.
B. They can totally order all events without ties.
C. They eliminate the need for message passing.
Answer (reveal)
Correct: A.
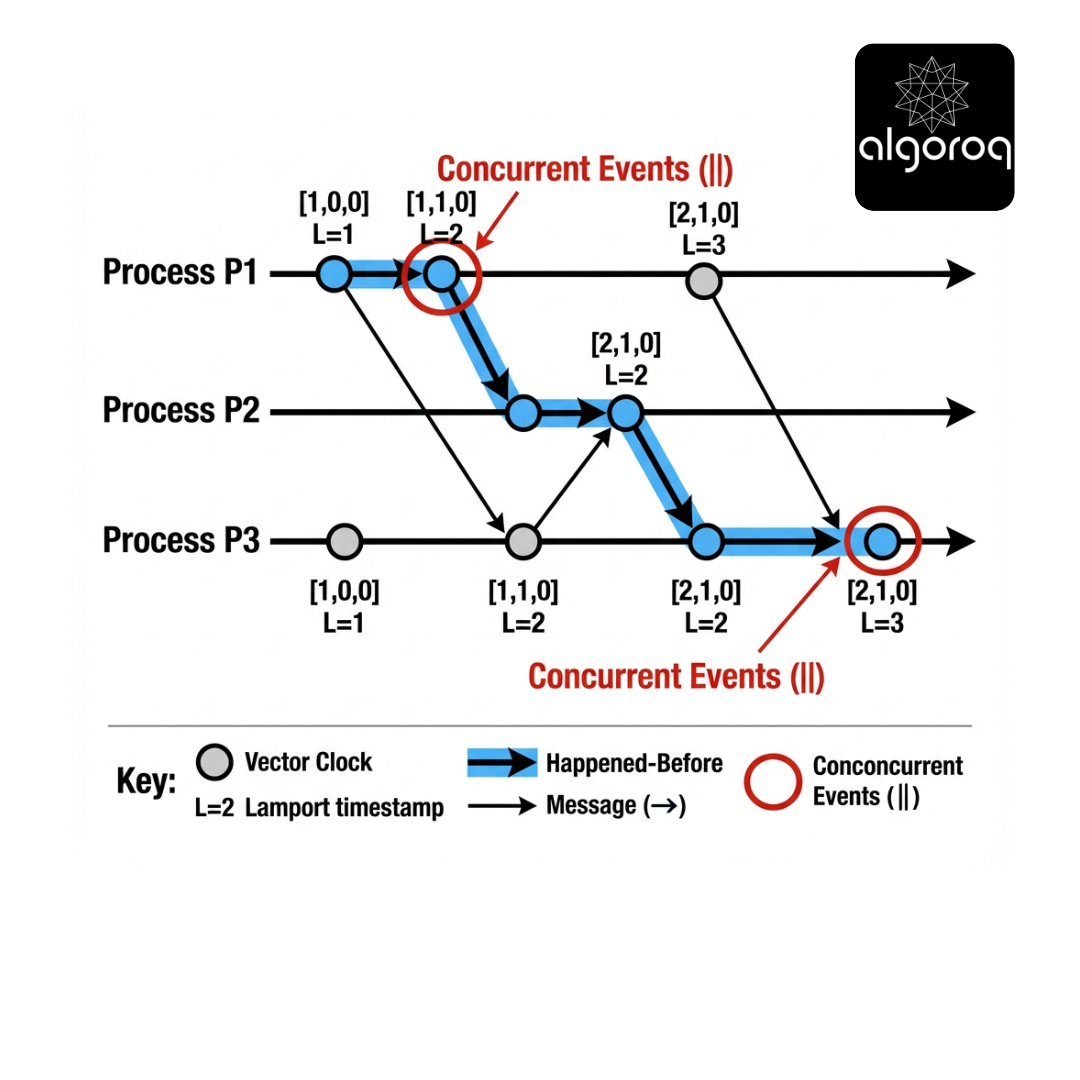
Vector clocks can determine whether a -> b, b -> a, or neither (concurrent), by comparing vectors.
They do not provide a natural total order (you can impose one, but that is extra and reintroduces arbitrary ordering).
Mental model:
A vector clock is a causal "receipt":
- "Here is what I have observed so far from everyone."
If my receipt is entirely included in yours, then I happened before you.
[IMAGE: Show two vectors VC(a)=[2,0,1] and VC(b)=[2,1,1]. Highlight component-wise comparison: all components of a <= b and at least one strictly <. Label "a happened-before b".]
Vector clock algorithm
System with N processes. Each process i maintains vector VCi[1..N].
Rules:
- Local event at i: VCi[i] += 1.
- Send message from i: attach a copy of VCi.
- Receive message at i with vector V:
- For each k: VCi[k] = max(VCi[k], V[k])
- Then VCi[i] += 1
Why the increment after merge?
- The receive itself is a new event that must be ordered after both the prior local state and the incoming message's causal past.
[CODE: Python, vector clock operations and comparison (happened-before / concurrent)]
How comparison works
Given two vector timestamps V and W:
- V <= W iff for all i, V[i] <= W[i].
- V < W iff V <= W and exists j such that V[j] < W[j].
Then:
- If V < W, event V happened-before event W.
- If neither V < W nor W < V, they are concurrent.
[MISCONCEPTION]
"Vector clocks give you exact real time."
No. They give you causal structure. Two events can be concurrent even if one "really" happened earlier in wall time.
Key insight:
Vector clocks are a concurrency detector.
Challenge question:
- Why do we increment VCi[i] after merging on receive (instead of before)? What would break?
Answer:
- If you increment before merge, you can produce a receive timestamp that is not strictly greater than the incoming message in that component-wise order, breaking the guarantee that send(m) -> recv(m).
Matching: Lamport vs Vector clocks
Scenario
You are designing a replicated key-value store. You need to choose a timestamping scheme.
Matching exercise (pause and think)
Match each requirement to Lamport or Vector:
- "I need a deterministic total order for log replication, even if it is arbitrary."
- "I need to detect if two writes are concurrent to trigger conflict resolution."
- "I can only afford O(1) metadata per event."
- "I can afford O(N) metadata per event, and N is small."
Answer (reveal)
1 -> Lamport (often plus tie-breaker) 2 -> Vector 3 -> Lamport 4 -> Vector
Comparison table
| Feature | Lamport Timestamp | Vector Clock |
|---|---|---|
| Metadata size | O(1) | O(N) (or O(#participants) with sparse maps) |
| Captures a -> b implies ts(a) < ts(b) | Yes | Yes |
| Can infer ts(a) < ts(b) implies a -> b | No | Yes (via vector comparison) |
| Detects concurrency | No | Yes |
| Easy to totally order events | Yes (with tie-breaker) | Needs extra rule |
| Scales to huge numbers of nodes | Yes | Not directly |
Key insight:
Lamport is compact and order-friendly; vector clocks are causality-friendly but metadata-heavy.
Challenge question:
- If N is dynamic (autoscaling microservices), what happens to vector clocks? What are two strategies to cope?
Production strategies:
- Use a bounded participant set (per-shard replication group, per-region, per-session).
- Use dotted version vectors (DVV) / version vectors with exceptions to compress.
Partitions, retries, duplicates, and reordering
Scenario
Your system uses asynchronous messaging. Network behavior:
- Messages can be delayed.
- Messages can be duplicated.
- Messages can arrive out of order.
- Nodes can crash and restart.
- Partitions can isolate subsets.
You still want meaningful ordering metadata.
Pause and think
Which of these break Lamport timestamps?
A. Message reordering B. Message duplication C. Network partitions D. Node crash + restart (without stable clock state)
Answer (reveal)
- A (reordering): does not break correctness. Receive rule uses max.
- B (duplication): does not break ordering correctness, but can create extra applied operations unless you deduplicate.
- C (partition): does not break correctness; it increases concurrency (more unrelated events).
- D (crash + restart): can break semantics if the process loses its clock state and reuses old timestamps.
Same story for vector clocks: the algorithm tolerates reordering/duplication/partition, but requires stable state across restarts if you want monotonicity for that process identity.
Production insight: duplicates and retries
- Logical clocks do not solve idempotency. You still need message IDs / operation IDs and deduplication.
- If you generate a new logical timestamp on each retry, you can accidentally create multiple distinct operations. Use an operation ID and treat retries as the same operation.
Crash/restart: identity and epochs
If a node restarts and reuses the same identity without persisting its clock component, it can appear to go backward.
Fix options:
- Persist logical clock state to stable storage.
- Or include an epoch/boot ID in the identity and treat (nodeId, epoch) as a new participant.
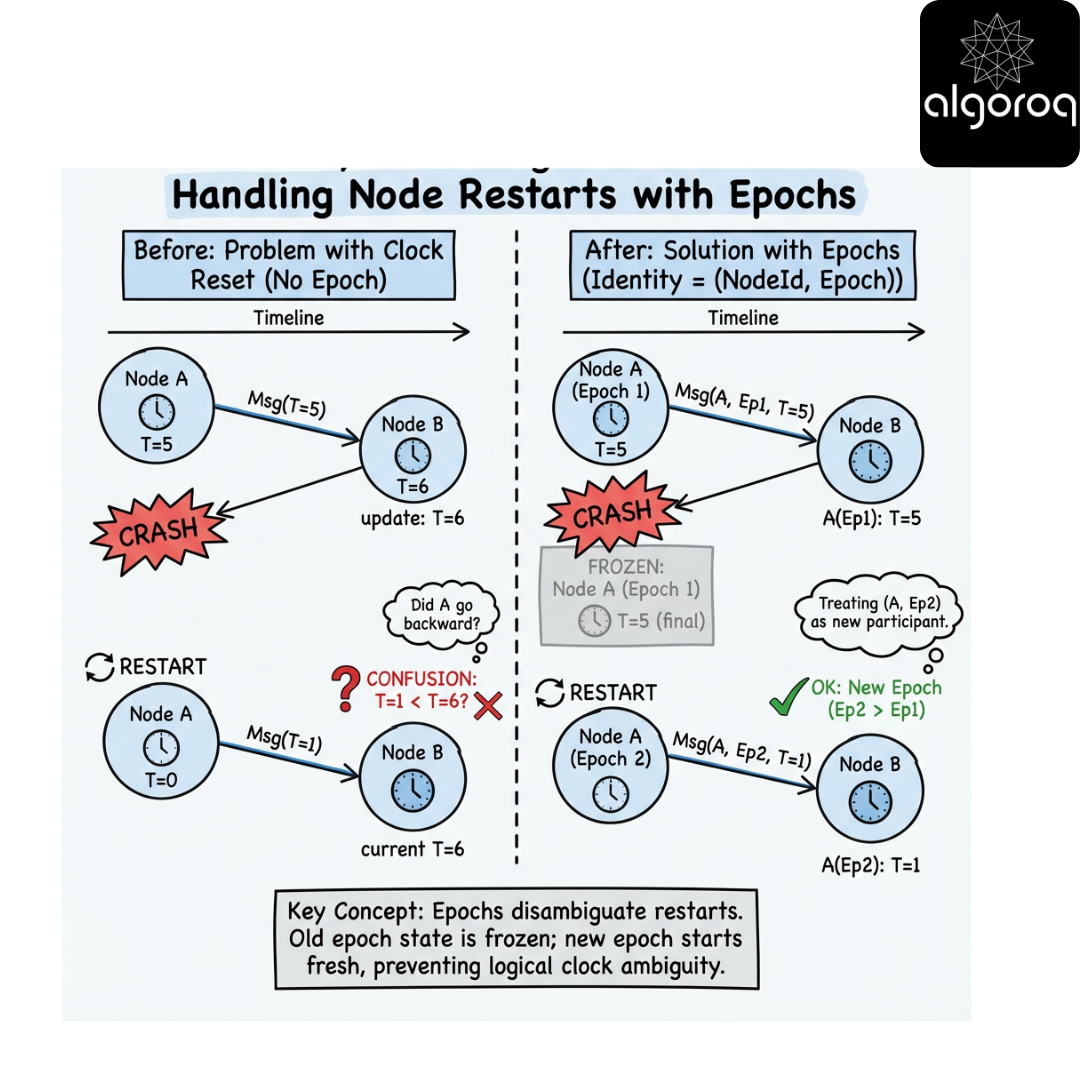
Key insight:
Logical clocks assume stable process identity and monotonic state; crashes force you to model identity/epoch.
Challenge question:
- If you do not persist Lamport clock across restart, can you still be safe by including (timestamp, nodeId, bootId)? What does it fix and what does it not fix?
Answer:
- It fixes uniqueness (no accidental collision between old and new process instances).
- It does not restore causal continuity across restarts; you've effectively created a new process in the happened-before model.
What you pay for
Scenario
You are choosing between:
- Lamport: 8 bytes per event (64-bit counter)
- Vector: N8 bytes per event (N services/nodes)
Your event rate is 1M events/sec, retained for 7 days.
Pause and think
If N=200, what happens to storage and network overhead?
Answer (reveal)
Vector metadata becomes enormous:
- 200 * 8 = 1600 bytes per event just for the clock.
- At 1M events/sec, that is about 1.6 GB/sec of clock metadata alone.*
Lamport stays constant.
Performance considerations:
- Vector merge is O(#keys in incoming U local). With sparse maps, this is proportional to the number of participants that have actually interacted.
- Comparing vectors is also O(#participants). If you compare frequently (e.g., sorting), this can dominate CPU.
Mental model:
Vector clocks buy you precision about concurrency, but you pay in:
- bandwidth
- storage
- CPU (merge/compare)
- membership management (who is in the vector?)
Lamport buys you cheap causality-respecting numbering, but you pay in:
- inability to detect concurrency
- potential "false order" that can hide conflicts
Key insight:
Choose the smallest mechanism that supports the semantics you need.
Challenge question:
- Name one system where "false order" is acceptable and one where it is dangerous.
Examples:
- Acceptable: log display ordering for debugging; analytics pipelines where you don't enforce invariants.
- Dangerous: multi-writer state machines with invariants (payments, inventory, locks) where lost updates or invalid transitions matter.
Usage patterns
Pattern 1: Causal consistency and conflict detection (vector clocks)
Used when you want to know whether two versions are concurrent.
- Classic example: Amazon Dynamo-style systems used vector clocks (or descendants) to detect siblings (concurrent versions).
- Client writes can be concurrent across partitions; vector clocks help surface conflicts for resolution.
Pattern 2: Total order broadcast / log replication (Lamport-like vs consensus)
Used when the system wants a single agreed order.
- Many systems use consensus (Raft/Paxos) to pick an order. The consensus log index acts like a global logical time.
- Lamport timestamps alone do not give agreement; they can help with tie-breaking or debugging but do not replace consensus.
Pattern 3: Debugging and tracing
Lamport clocks can annotate logs so you can sort "roughly causally," even if not perfectly.
Vector clocks can be used for causal tracing in smaller topologies.
[MISCONCEPTION]
"If I use vector clocks, I do not need consensus."
Vector clocks tell you what is concurrent; they do not decide which concurrent update wins. If you need a single authoritative decision, you still need:
- consensus
- or commutative/associative merge (CRDT)
- or application-level conflict resolution
Key insight:
Clocks describe concurrency; they do not resolve it.
CAP/availability note:
- If you choose consensus to serialize updates, you are choosing stronger consistency (often linearizability per shard) at the cost of availability during partitions.
- If you choose vector clocks + conflict resolution, you can remain available under partition but must handle concurrent versions.
Challenge question:
- In a shopping cart service, which is more appropriate: consensus ordering, vector-clock conflict detection, or a CRDT? Why?
Reading causality from vectors
Scenario
Three processes: A, B, C.
You observe three events with vector clocks:
- e1: [2, 0, 0]
- e2: [2, 1, 0]
- e3: [1, 1, 0]
Which statements are true?
- e1 -> e2
- e3 -> e2
- e1 and e3 are concurrent
Pause and compare component-wise.
Answer (reveal)
- e1=[2,0,0] and e2=[2,1,0]: e1 < e2, so 1 is true.
- e3=[1,1,0] and e2=[2,1,0]: e3 < e2, so 2 is true.
- e1 vs e3: mixed dominance (A: 2>1, B: 0<1), so concurrent; 3 is true.
Key insight:
Concurrency shows up as mixed dominance across vector components.
Challenge question:
- Construct two vector clocks that are equal. What does equality mean about the events?
Clarification:
- Equality means the same causal history as represented by the vector. In a correct implementation where each event increments exactly one component, two distinct events should not end up with identical vectors.
- In practice, you can see equality if you are comparing versions that refer to the same event, or if you have bugs (e.g., failing to tick on local events).
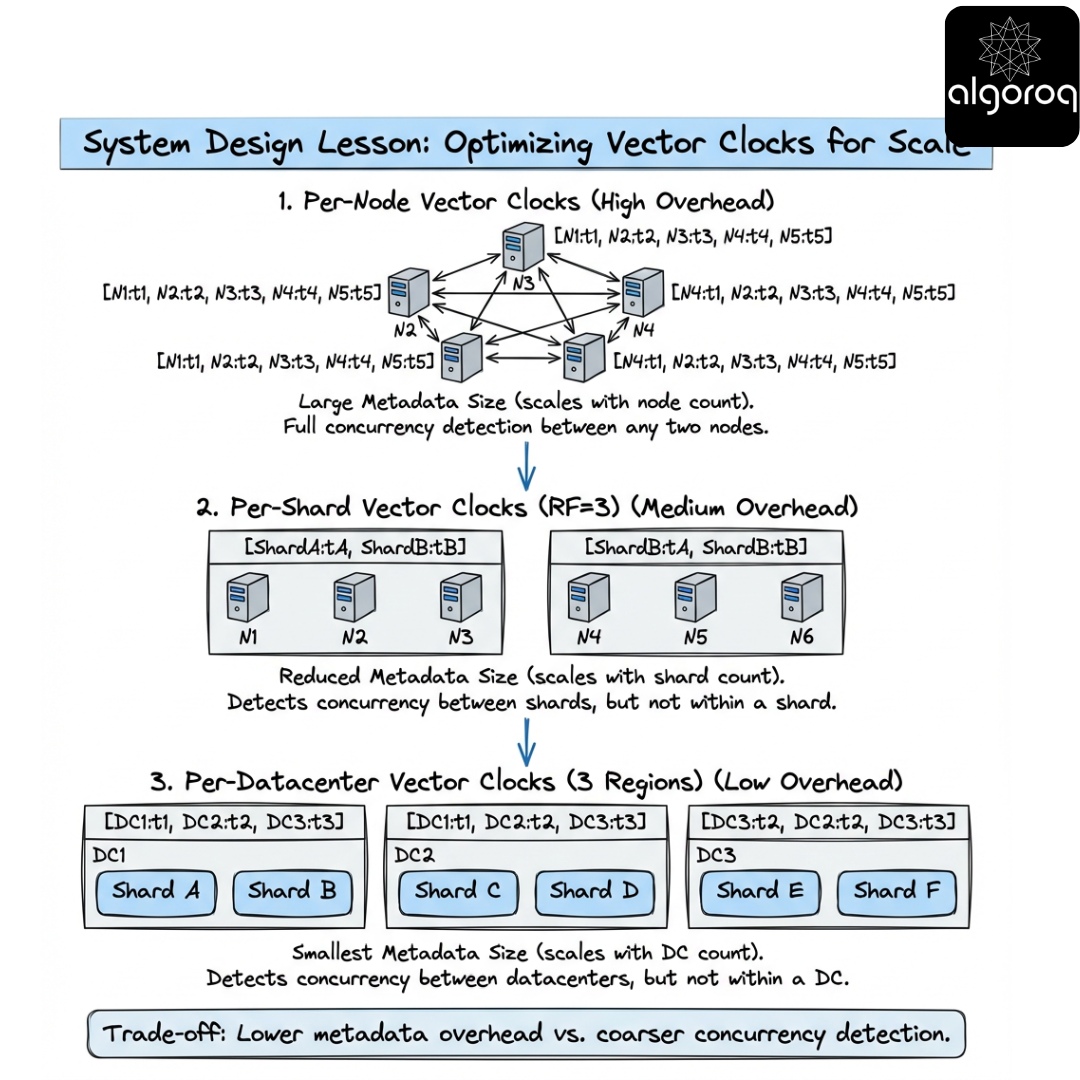
Identity, membership, and compression
Scenario
Your cluster autoscaled from 20 to 2000 nodes. Vector clocks now look impossible.
Pause and think
Is a vector clock really "one entry per node," always?
Answer (reveal)
Not necessarily.
Vector clocks require a set of participants. In practice, you can choose participants as:
- nodes
- replicas per key-range
- client sessions
- datacenters
- shards
You can also compress or approximate, but with trade-offs.
Strategies
-
Per-shard vector clocks
- If only shard replicas can write, vector size = replication factor, not cluster size.
-
Dotted version vectors (DVV)
- Keep a compact version vector plus a dot identifying a single event.
- Common in Dynamo descendants to reduce metadata while preserving concurrency detection.
-
Hierarchical clocks
- Track per-datacenter vectors plus local counters.
-
Hybrid Logical Clocks (HLC)
- Combine physical time with logical counters to get near-real-time ordering plus causality hints.
- Not a replacement for vectors when you need exact concurrency detection.
[MISCONCEPTION]
"Vector clocks do not scale, so they are useless."
They scale poorly with large participant sets, but many systems naturally have small participant sets per object (for example, per-shard replication group).
Key insight:
Vector clocks scale with the number of writers that can causally interact for the same object, not necessarily the whole cluster.
Challenge question:
- In a multi-leader database with 3 regions, what is a natural participant set for vector clocks? Why?
Answer:
- Regions (or per-region leaders) are a natural set: concurrency that matters is typically cross-region, and the set is stable and small.
Using clocks for conflict resolution (what clocks do not do)
Scenario
Two concurrent updates to the same user profile field:
- P1: name = "Sam"
- P2: name = "Samuel"
Vector clocks detect concurrency. Now what?
Pause and think
Which resolution strategies are valid?
A. Last-writer-wins using wall clock B. Deterministic tie-breaker (for example, node ID) C. Application merge (for example, keep both, ask user) D. CRDT register (multi-value register)
Answer (reveal)
All can be used, depending on requirements.
- A is simple but can be unfair under clock skew.
- B is deterministic but arbitrary.
- C preserves intent but pushes complexity upward.
- D encodes conflict semantics in data type.
Production insight:
- If you choose LWW, consider HLC (or TrueTime-like bounds) to reduce skew issues, but understand it still doesn't give you causality.
- If you choose deterministic tie-breakers, document the policy; otherwise you'll get "why did my update lose?" incidents.
Key insight:
Clocks answer "are these causally ordered?" not "which one is correct?"
Challenge question:
- If you must provide a single value to users, what is a principled approach to choosing a tie-breaker that minimizes surprise?
Good answers:
- Prefer domain semantics (e.g., CANCELLED dominates PAID if cancellation is authoritative), or require explicit user confirmation when concurrent.
When to choose which
Scenario
You are building three components:
- Event log for analytics (append-only)
- Replicated KV store with multi-writer updates
- Distributed lock service
Decision game (pause and think)
Pick the best fit:
- Lamport timestamps
- Vector clocks
- Consensus log index (Raft)
- CRDT (with causal metadata)
Component 1: Event log for analytics
Component 2: Multi-writer KV store
Component 3: Distributed lock
Answer (reveal) (one reasonable mapping)
-
Event log: consensus log index (or Lamport-like ordering if single writer per partition). Analytics wants stable ordering; causality detection usually not required.
-
Multi-writer KV store: vector clocks (or DVV/HLC plus conflict resolution/CRDT). Need to detect concurrent writes.
-
Distributed lock: consensus (or specialized lock protocols). Locks require agreement, not just timestamps.
Key insight:
The stronger the coordination requirement, the more you move from clocks to agreement.
Challenge question:
- Can you implement a correct distributed lock with only Lamport timestamps and no message acknowledgments? Why or why not?
Answer:
- No. Locks require mutual exclusion with agreement on ownership. Without acknowledgments/coordination, partitions can create split-brain (two holders). Lamport timestamps can order requests but cannot ensure a single winner is known to all.
Edge cases and real deployments
Scenario
You implement vector clocks but see weird results:
- Some events appear older after restart.
- Some concurrent updates are not detected.
Gotcha 1: Process identity reuse
If node i restarts and reuses the same index in the vector without persisting state, it can produce vectors that look like time went backward.
Fix: include epoch in identity or persist component.
Gotcha 2: Membership changes
If you change the participant set (add/remove nodes) you must define how vectors grow/shrink.
Common approaches:
- fixed membership per replication group
- map node IDs to sparse maps (hash maps) rather than arrays
- treat removed nodes as frozen components
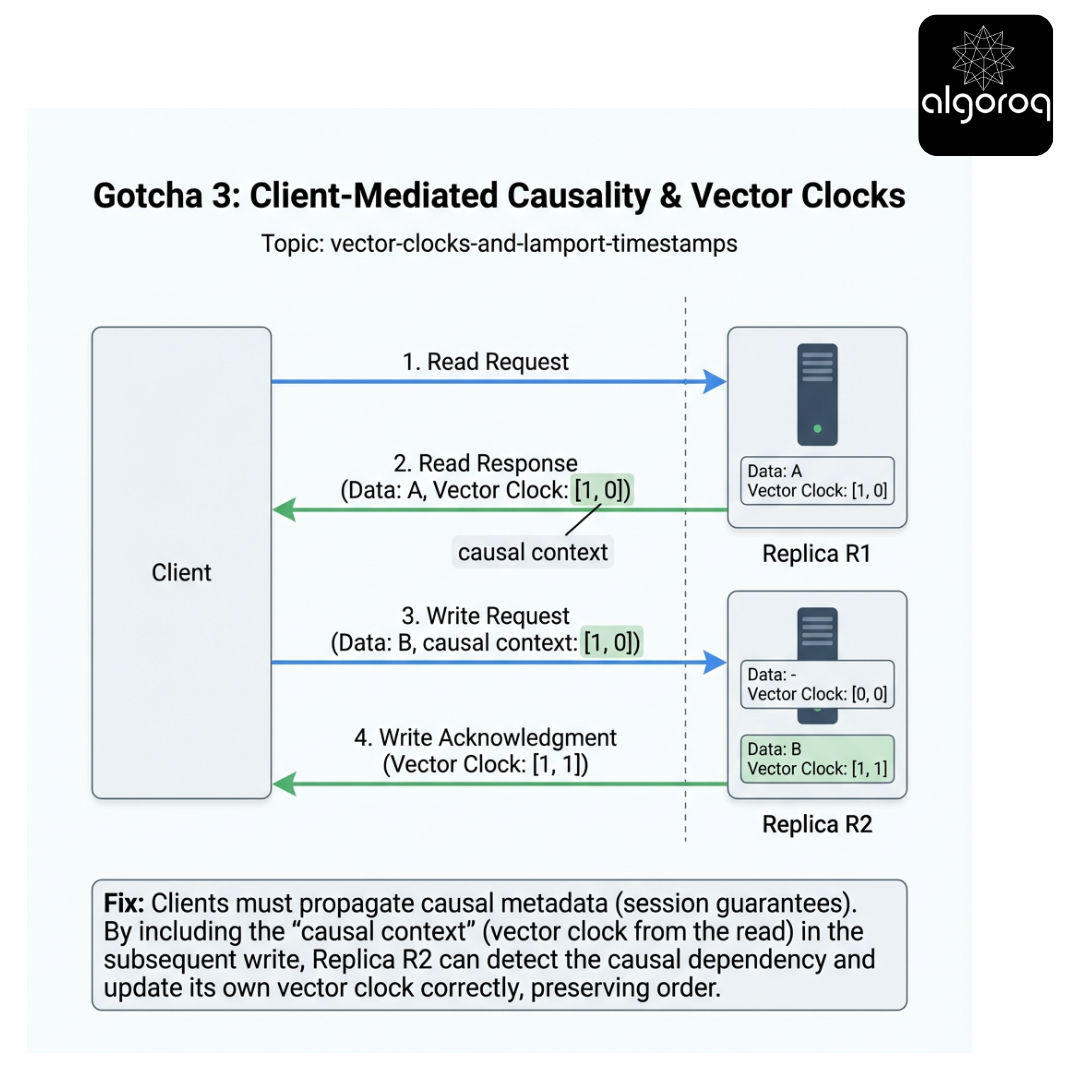
Gotcha 3: Client-mediated causality
If clients read from replica A and then write to replica B, causality might flow through the client.
If the write does not carry causal context (vector), the system can lose causal ordering.
Fix: clients must propagate causal metadata (session guarantees).
[MISCONCEPTION]
"Causality only flows through server-to-server messages."
Clients are often the biggest carriers of causality.
Key insight:
If you want causal consistency, causal context must travel along every information path, including clients.
Challenge question:
- In an HTTP API, where would you store/return vector clock context to the client? Header? Body? Cookie? What are the trade-offs?
Production guidance:
- Header is common (opaque token), keeps payload clean; but watch header size limits.
- Body is explicit and versioned; but requires clients to parse/forward.
- Cookies are risky (cross-origin, caching, size, security).
Compute clocks by hand
Scenario
Two processes P1 and P2.
Events:
- P1 does local event a
- P1 sends message m to P2
- P2 does local event b
- P2 receives m
- P2 sends reply r to P1
- P1 receives r
Step 1: Lamport timestamps (pause and think)
Assume both start at 0.
Compute Lamport timestamps for a, send(m), b, recv(m), send(r), recv(r).
Answer (reveal)
Let P1 clock = L1, P2 clock = L2.
- a: L1=1
- send(m): L1=2, m.ts=2
- b: L2=1
- recv(m): L2=max(1,2)+1=3
- send(r): L2=4, r.ts=4
- recv(r): L1=max(2,4)+1=5
Step 2: Vector clocks (pause and think)
Vectors are [P1,P2]. Start [0,0] at both.
Compute vector timestamp at each event.
Answer (reveal)
- P1 a: [1,0]
- P1 send(m): [2,0] attach
- P2 b: [0,1]
- P2 recv(m): merge max([0,1],[2,0])=[2,1], then increment P2 => [2,2]
- P2 send(r): [2,3] attach
- P1 recv(r): merge max([2,0],[2,3])=[2,3], then increment P1 => [3,3]
Key insight:
Vector clocks preserve the shape of causality: by the end, each side has seen the other's progress.
Challenge question:
- Which pairs among {a, b, recv(m)} are concurrent? Verify using vector comparisons.
Answer:
- a=[1,0] and b=[0,1] are concurrent.
- b=[0,1] and recv(m)=[2,2] => b happened-before recv(m).
- a=[1,0] and recv(m)=[2,2] => a happened-before recv(m).
Build a causality-aware order update system
Synthesis challenge
Return to the food-delivery platform.
You maintain an Order Timeline that shows status changes:
- PLACED
- PAID
- CANCELLED
- PICKED_UP
- DELIVERED
Updates can be produced by multiple services in different regions.
You want:
- To show users a timeline that never violates causality (for example, cannot show PICKED_UP before PAID if that dependency exists).
- To detect when two updates are concurrent and require special handling.
- To remain operational during partitions.
Decision game (pause and think)
Choose an approach:
A. Use Lamport timestamps only, sort by (L, serviceId).
B. Use vector clocks, show causal order; if concurrent, show both with conflict UI.
C. Use consensus to serialize all updates globally.
D. Use CRDT state machine with causal metadata.
Answer (reveal) (design discussion)
- A gives deterministic order but can hide concurrency; you may show a misleading story.
- B gives causal correctness and concurrency detection, but metadata and client propagation complexity.
- C gives a single authoritative order, but at the cost of coordination and reduced availability under partition (CAP trade-off).
- D can make concurrent updates merge safely, but requires careful modeling of state transitions and often still needs causal metadata.
A practical architecture often combines them:
- Per-order partitioned log (consensus within a shard) for strong ordering per order ID (highly common). This is effectively linearizable per order, and avoids vector clocks entirely for that object.
- Or multi-leader per order with vector clocks/DVV + conflict resolution if you need higher write availability across regions.
Failure scenarios to explicitly design for:
- Partition between regions: do you accept concurrent PAID and CANCELLED? If yes, you need conflict semantics.
- Duplicate events due to retries: require idempotency keys and dedup.
- Out-of-order delivery: your apply logic must be commutative or must buffer until dependencies are satisfied.
Consistency model clarity:
- Consensus per order gives strong consistency per order (often linearizability) but sacrifices availability under partition for that order.
- Vector clocks + conflict resolution gives eventual convergence with explicit concurrency handling (AP-style), but pushes complexity into merge policy/UI.
Final challenge questions
- If you shard by orderId, does that reduce the participant set enough to make vector clocks feasible? Why?
- Under what product requirements would you accept deterministic but arbitrary ordering?
- Where would you store causal metadata: in events, in database rows, or in message headers?
- How do retries and idempotency interact with logical clocks?
Appendix: Quick reference
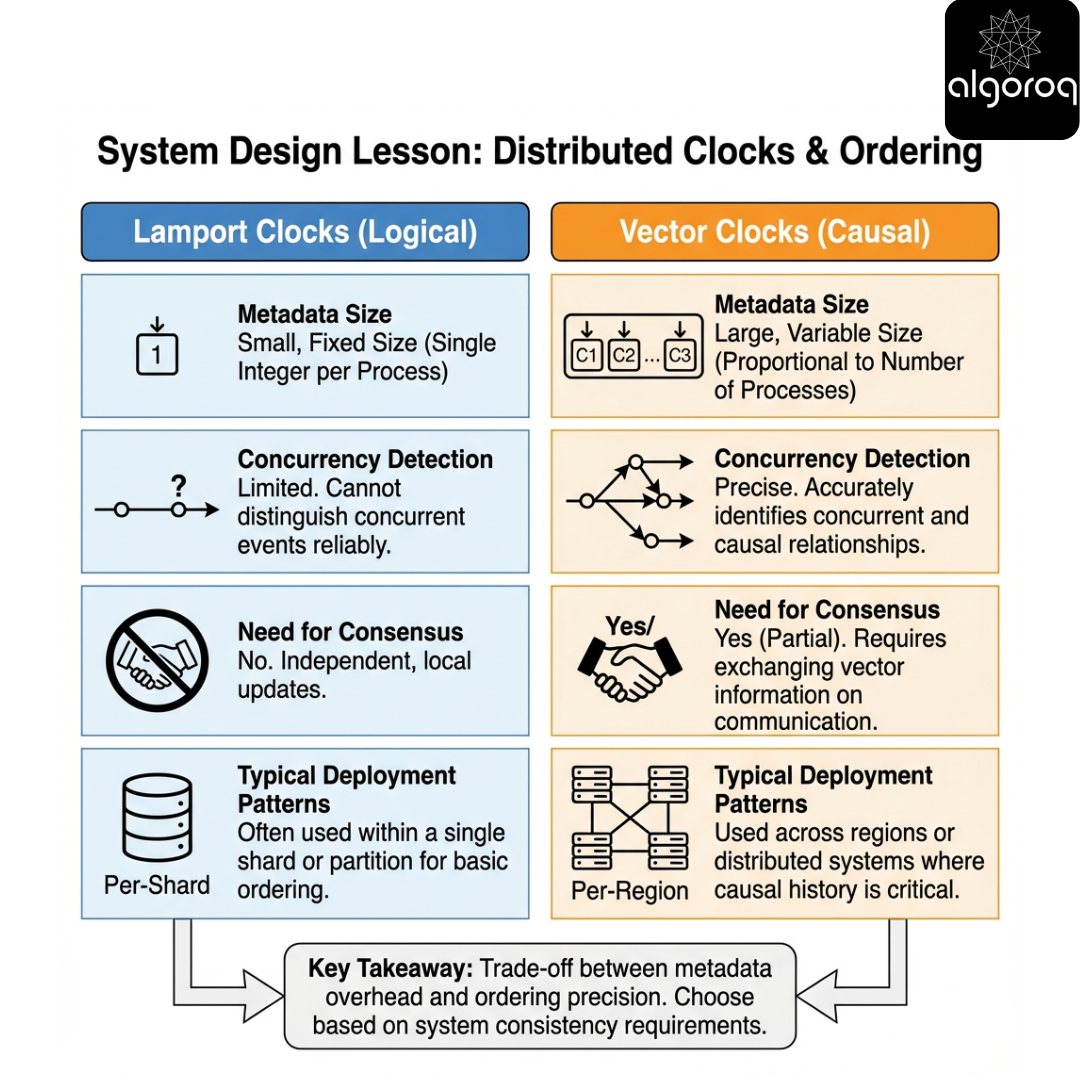
Lamport timestamp
- State: single integer per process
- Guarantees: a -> b implies L(a) < L(b)
- Cannot detect concurrency
- Great for: cheap ordering, tie-breaking, rough causal sorting
Vector clock
- State: vector/map of counters
- Guarantees: can determine happened-before and concurrency
- Cost: O(N) metadata, membership complexity
- Great for: detecting concurrent versions, causal consistency
Key Takeaways
- Lamport timestamps establish a partial ordering of events — if A happened before B, then timestamp(A) < timestamp(B)
- Vector clocks track causality across multiple nodes — each node maintains a vector of counters, one per node in the system
- Vector clocks detect concurrent events that Lamport timestamps cannot — two events are concurrent if neither vector dominates the other
- DynamoDB and Riak use vector clocks for conflict detection — when two replicas diverge, vector clocks identify the conflict for resolution
- The trade-off is metadata overhead — vector clocks grow with the number of nodes, which is why some systems use simpler alternatives