Single Point of Failure

Single Point of Failure (SPOF): The One Bridge Problem
The Island Town Story
Let me tell you about a town built on an island. Beautiful place—homes, shops, schools, everything. But there's one problem:

Only ONE bridge connects the island to the mainland.
Now imagine what happens when:
Scenario 1: Bridge Under Maintenance
Monday 9 AM: "Bridge closed for repairs"
Result:
- No one can get to work
- No food deliveries
- No emergency services
- Town is isolated
The entire town stops functioning because of ONE bridge!
This bridge is a Single Point of Failure (SPOF)—one component whose failure brings down the entire system.
Let's See This in Real Software Systems
Example 1: The Single Database Disaster
Imagine you're running a social media app:
Your Architecture (Dangerous): ━━━━━━━━━━━━━━━━━━━━━━━━━━━━
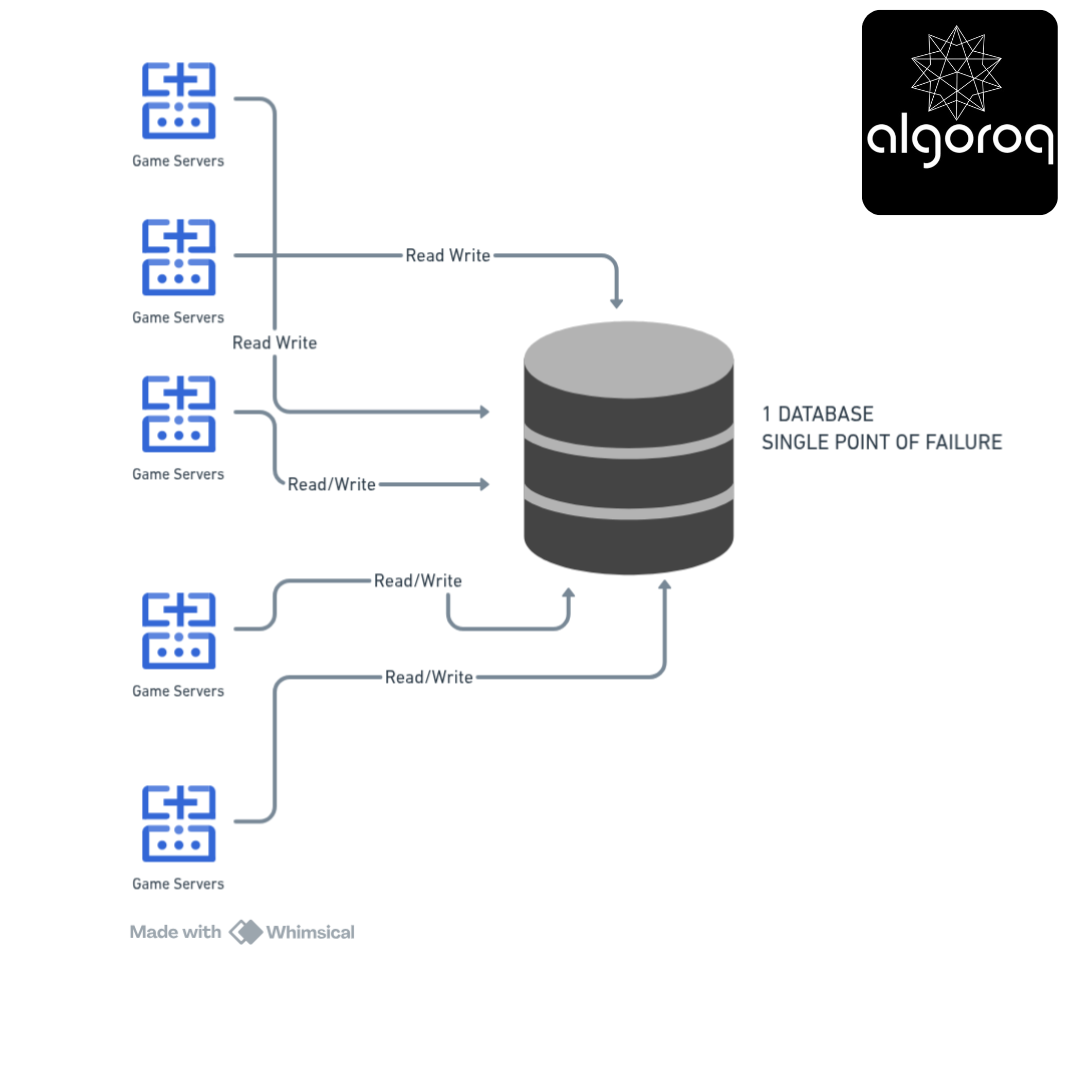
What happens when the database fails?
2:00 AM - Database server crashes
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
2:00:01 AM - All 1000 servers can't reach database
2:00:02 AM - Every user request fails
2:00:03 AM - Error alerts flooding your phone
2:00:05 AM - Website shows: "Service unavailable"
Impact:
❌ Can't log in
❌ Can't post
❌ Can't load feed
❌ Can't do ANYTHING
Lost revenue: $10,000/minute Angry users: Millions Your phone: Exploding with alerts 📱💥
Duration: Until you fix the database (hours? days?)
The Fix: Eliminate the SPOF
Improved Architecture (Resilient):
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
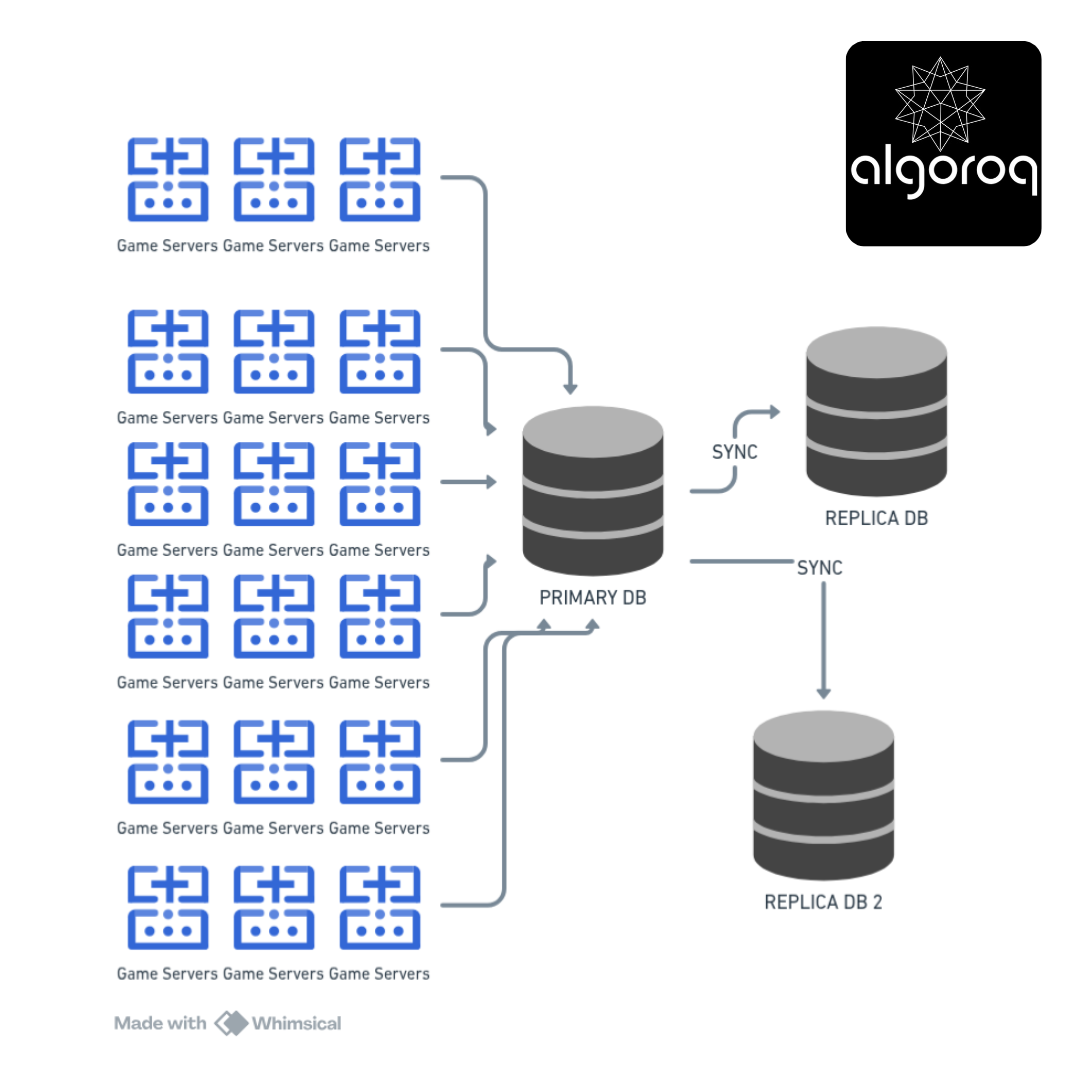
All databases sync continuously If primary fails → replica takes over No downtime!
Now when failure happens:
2:00 AM - Primary database crashes
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
2:00:01 AM - Automatic failover detected
2:00:02 AM - Replica promoted to primary
2:00:03 AM - Traffic routed to new primary
2:00:05 AM - Users don't notice anything
Impact:
✓ Seamless transition
✓ No downtime
✓ Business continues
Lost revenue: $0
Angry users: 0
Your sleep: Undisturbed 😴
Real-World SPOF Examples (And How to Fix Them)
SPOF #1: Single Load Balancer
The Problem:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
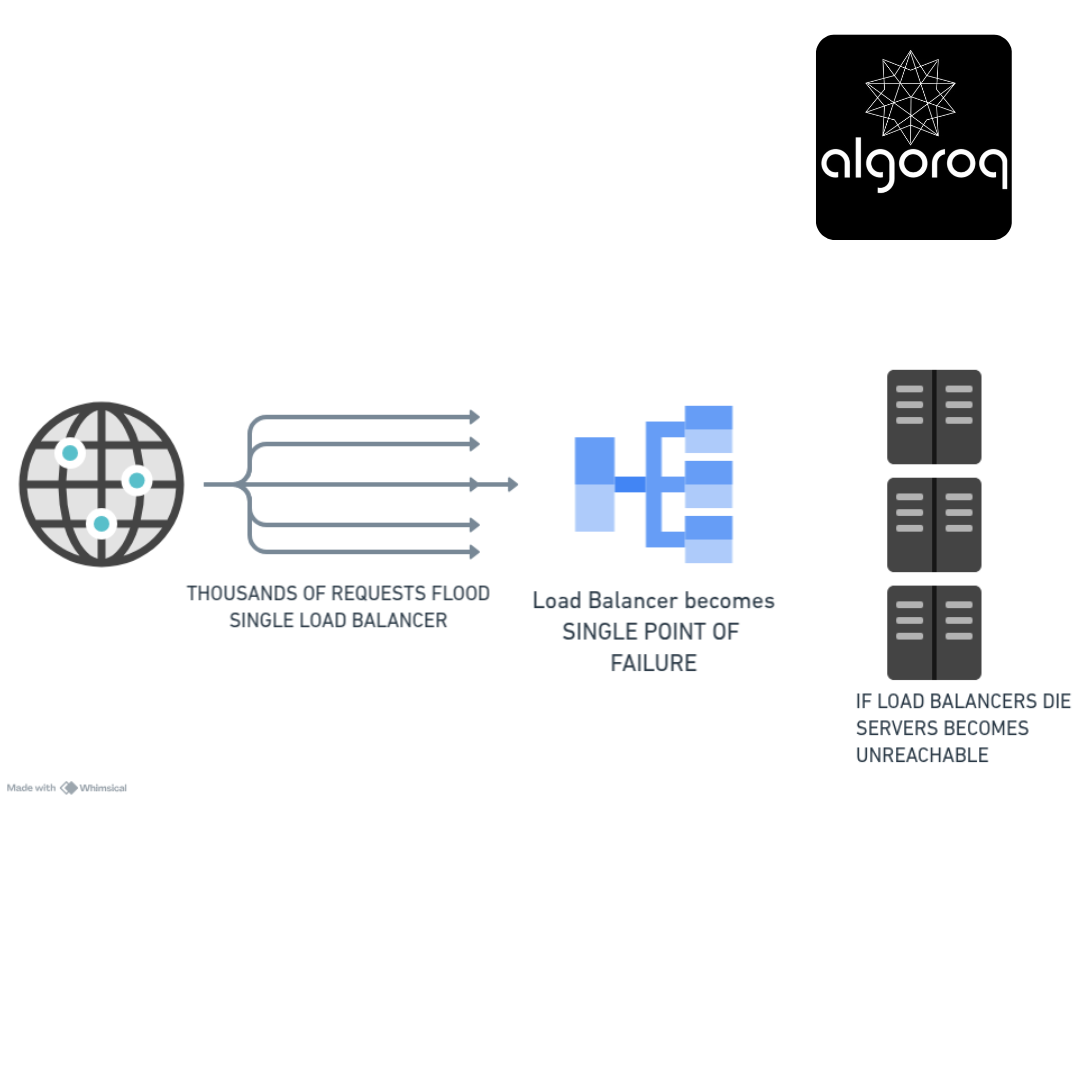
The Solution:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━

If LB1 fails → LB2 takes over automatically
SPOF #2: Single Internet Connection
The Problem:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━

ISP has outage → You're offline
The Solution:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
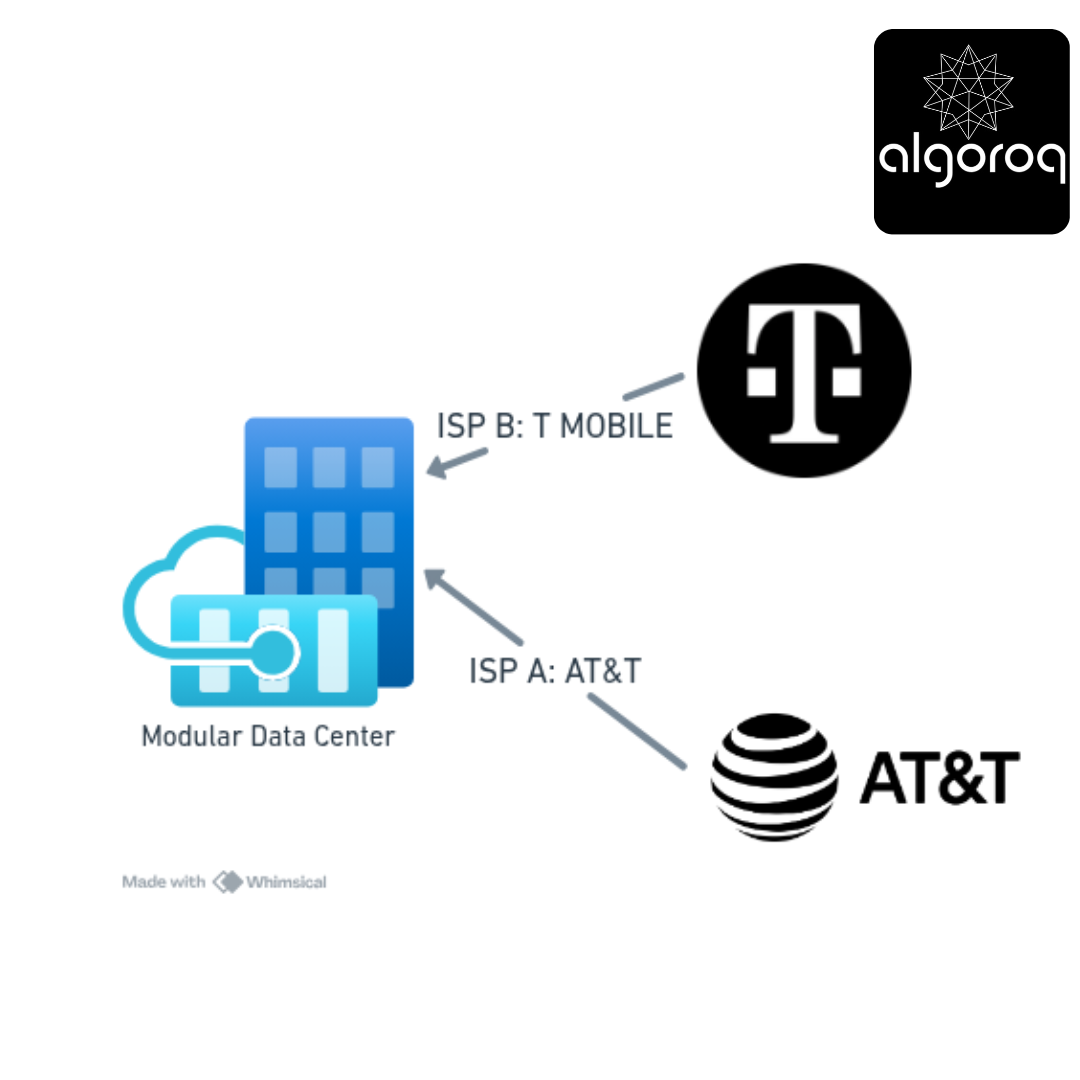
Multiple ISPs → If one fails, other takes over
SPOF #3: Single Payment Provider
The Problem:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━

Stripe down → Can't process ANY payments
The Solution:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
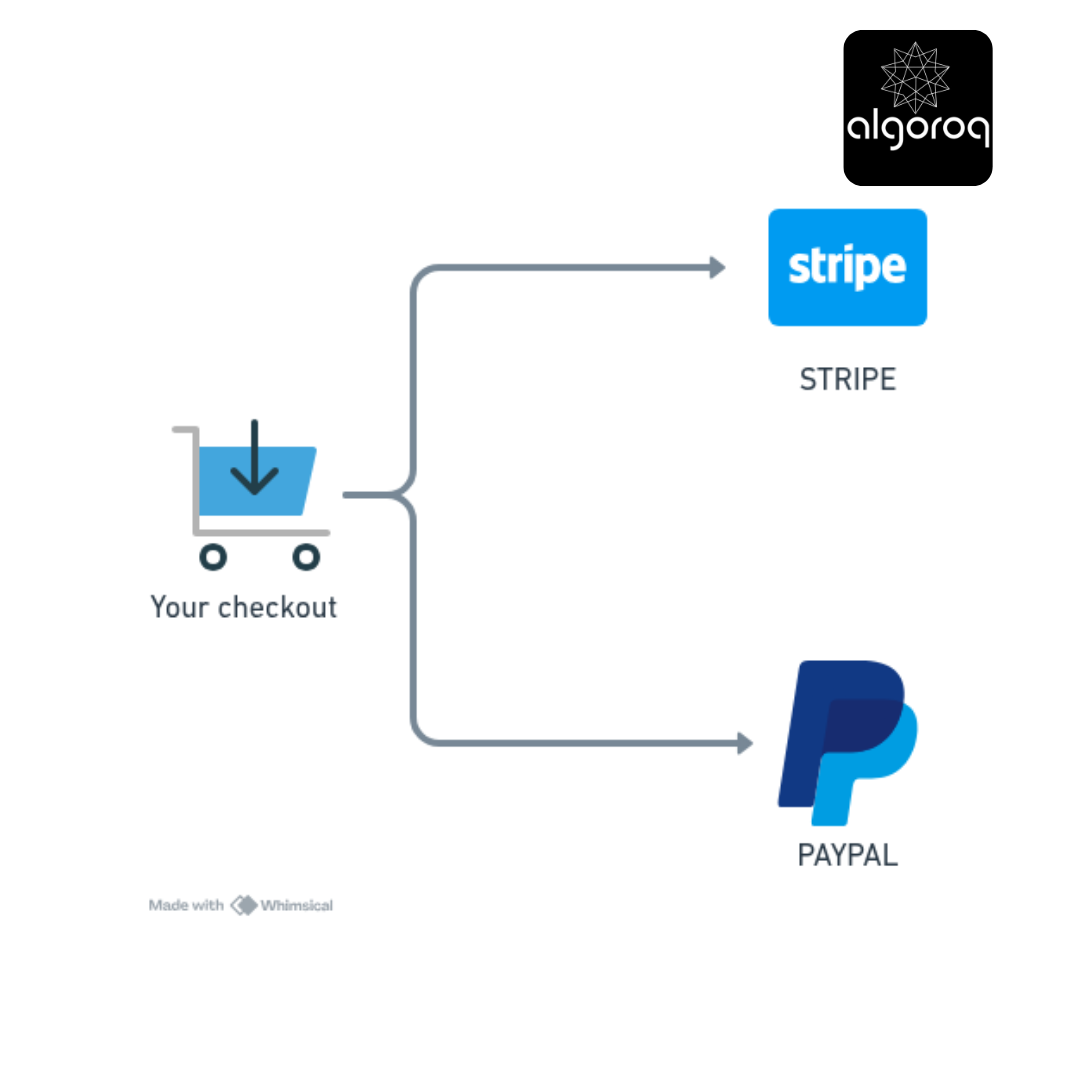
Try Stripe → If fails, try PayPal
The SPOF Identification Exercise
Let’s find SPOFs in any system. Look at this architecture:
System Architecture:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━

Question: In the diagram above How many SPOFs can you identify?
Answer: FIVE SPOFs! Let's see:
SPOF #1: DNS Server
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Problem: Users can't resolve your domain
Impact: Website unreachable
Fix: Multiple DNS providers (Route53 + Cloudflare)
SPOF #2: Load Balancer
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Problem: Can't distribute traffic
Impact: All servers unreachable
Fix: Active-Active or Active-Standby LB pair
SPOF #3: The Servers (as a group)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Problem: All in same data center
Impact: Data center outage = total failure
Fix: Multi-region deployment
SPOF #4: Database
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Problem: Single database instance
Impact: No data access
Fix: Primary-Replica setup with auto-failover
SPOF #5: File Storage
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Problem: Single storage server
Impact: Can't serve images/files
Fix: Distributed storage (S3, multiple regions)
The Cost-Benefit Analysis
Here's the truth:
Eliminating every SPOF is expensive. Let's see the tradeoffs:
Scenario: Small Startup ($1M revenue/year)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Option A: Single Database
Cost: $500/month
Downtime risk: 2 hours/year
Lost revenue: $230/hour = $460/year
Total cost: $6,460/year
Option B:
Database Cluster (No SPOF)
Cost: $3,000/month = $36,000/year
Downtime risk: 5 minutes/year
Lost revenue: $20
Total cost: $36,020/year
Is the extra $30,000 worth it? Maybe not!
Scenario: Large Company ($100M revenue/year)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Option A:
Single Database
Lost revenue: $23,000/hour × 2 hours = $46,000/year
Option B: Database Cluster
Extra cost: $36,000/year
Savings: $46,000 - $20 = $45,980
Now the extra $36,000 is worth it! ✓
The Decision Framework:
Should you eliminate this SPOF?
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Ask yourself:
-
What's the probability of failure?
-
High (>1%/year) → Eliminate it
-
Low (<0.1%/year) → Maybe acceptable
-
-
What's the business impact?
-
Critical (losing customers) → Eliminate it
-
Minor (slight inconvenience) → Maybe acceptable
-
-
What's the cost to fix?
-
Cheap (2x server cost) → Do it
-
Expensive (10x infrastructure) → Evaluate carefully
-
-
Can users tolerate downtime?
-
No (healthcare, finance) → Eliminate ALL SPOFs
-
Yes (personal blog) → Some SPOFs OK
-
Key Takeaways
- A single point of failure (SPOF) is any component whose failure brings down the entire system — databases, load balancers, and DNS are common SPOFs
- Redundancy eliminates SPOFs — run multiple instances of every critical component across different availability zones
- Active-passive failover keeps a standby ready to take over — simpler but wastes resources; active-active uses all instances
- Health checks detect failures automatically — the system must know something is down before it can route around it
- Design for failure from the start — assume any component can fail at any time and build accordingly